Yang Zou, Jongheon Jeong, Latha Pemula, Dongqing Zhang, Onkar Dabeer.
Ce référentiel contient les ressources de notre article ECCV-2022 « Pré-formation auto-supervisée SPot-the-Difference pour la détection et la segmentation des anomalies ». Nous publions actuellement l'ensemble de données Visual Anomaly (VisA).
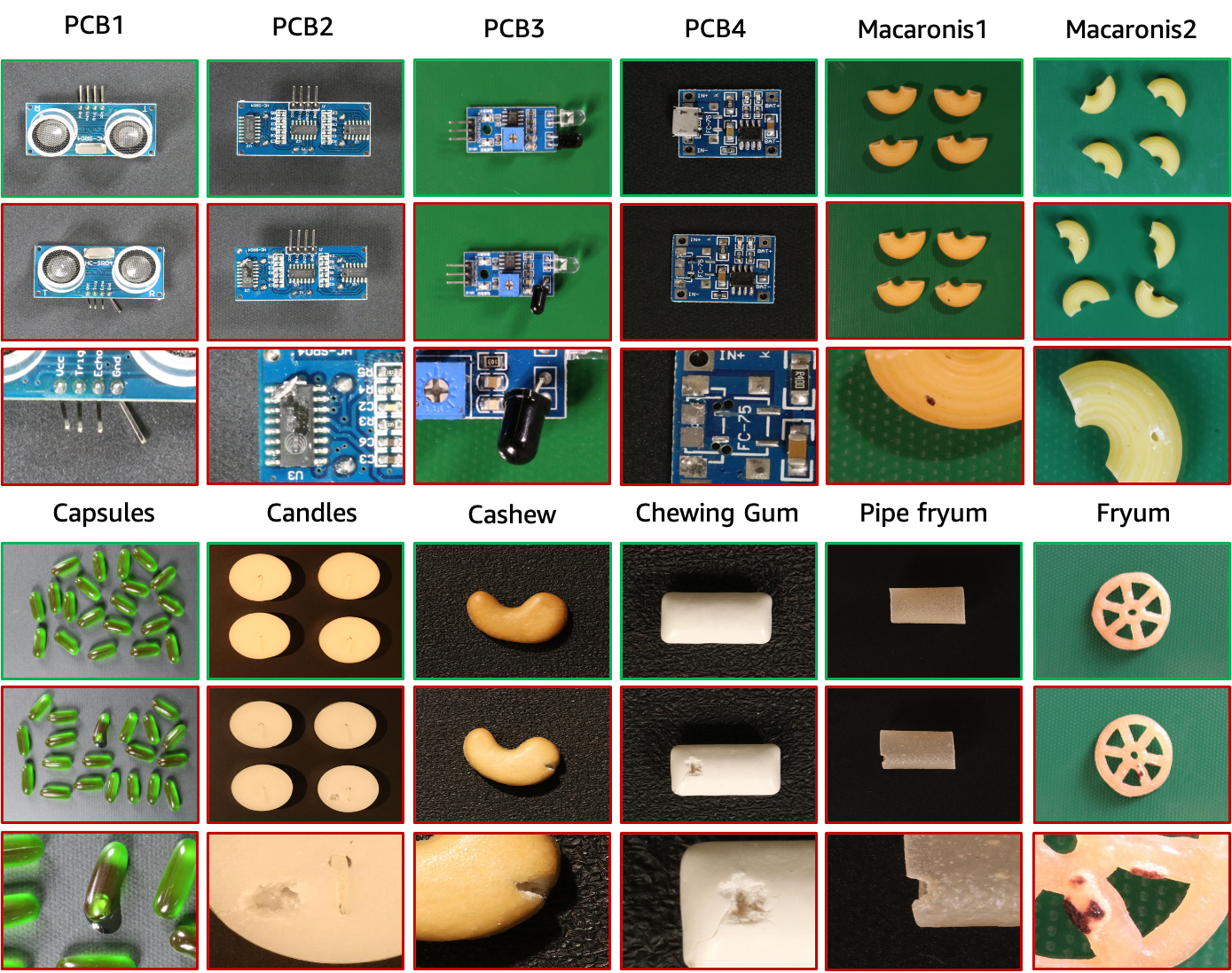
L'ensemble de données VisA contient 12 sous-ensembles correspondant à 12 objets différents, comme le montre la figure ci-dessus. Il y a 10 821 images avec 9 621 échantillons normaux et 1 200 anormaux. Quatre sous-ensembles sont différents types de cartes de circuits imprimés (PCB) avec des structures relativement complexes contenant des transistors, des condensateurs, des puces, etc. Pour le cas de plusieurs instances dans une vue, nous collectons quatre sous-ensembles : Capsules, Bougies, Macaroni1 et Macaroni2. Les instances dans Capsules et Macaroni2 diffèrent largement par leurs emplacements et leurs poses. De plus, nous collectons quatre sous-ensembles, dont Cashew, Chewing-gum, Fryum et Pipefryum, où les objets sont grossièrement alignés. Les images anormales contiennent divers défauts, notamment des défauts de surface tels que des rayures, des bosses, des taches de couleur ou des fissures, et des défauts structurels comme un mauvais placement ou des pièces manquantes.
| Objet | # échantillons normaux | # échantillons d'anomalies | # classes d'anomalies | type d'objet |
|---|---|---|---|---|
| PCB1 | 1 004 | 100 | 4 | Structure complexe |
| PCB2 | 1 001 | 100 | 4 | Structure complexe |
| PCB3 | 1 006 | 100 | 4 | Structure complexe |
| PCB4 | 1 005 | 100 | 7 | Structure complexe |
| Gélules | 602 | 100 | 5 | Plusieurs instances |
| Bougies | 1 000 | 100 | 8 | Plusieurs instances |
| Macaronis1 | 1 000 | 100 | 7 | Plusieurs instances |
| Macaronis2 | 1 000 | 100 | 7 | Plusieurs instances |
| Anacardier | 500 | 100 | 9 | Instance unique |
| Chewing-gum | 503 | 100 | 6 | Instance unique |
| Frium | 500 | 100 | 8 | Instance unique |
| Fryum de pipe | 500 | 100 | 9 | Instance unique |
Nous hébergeons l'ensemble de données VisA dans AWS S3 et vous pouvez le télécharger via cette URL.
L'arborescence des données téléchargées est la suivante.
VisA
| -- candle
| ----- | --- Data
| ----- | ----- | ----- Images
| ----- | ----- | -------- | ------ Anomaly
| ----- | ----- | -------- | ------ Normal
| ----- | ----- | ----- Masks
| ----- | ----- | -------- | ------ Anomaly
| ----- | --- image_anno.csv
| -- capsules
| ----- | ----- ...image_annot.csv donne une étiquette au niveau de l'image et un masque d'annotation au niveau des pixels pour chaque image. Les fonctions de carte id2class pour les masques multi-classes peuvent être trouvées dans ./utils/id2class.py Ici, les masques des images normales ne sont pas stockés pour économiser de l'espace.
Pour préparer les configurations à 1 classe, 2 classes highshot et 2 classes fewshot décrites dans l'article original, nous utilisons le fichier ./utils/prepare_data.py pour réorganiser les données en suivant les fichiers de fractionnement de données dans "./split_csv/". . Nous donnons un exemple de ligne de commande pour la préparation de l’installation d’une classe comme suit.
python ./utils/prepare_data.py --split-type 1cls --data-folder ./VisA --save-folder ./VisA_pytorch --split-file ./split_csv/1cls.csv
L'arborescence de données de la configuration réorganisée à 1 classe est la suivante.
VisA_pytorch
| -- 1cls
| ----- | --- candle
| ----- | ----- | ----- ground_truth
| ----- | ----- | ----- test
| ----- | ----- | ------- | ------- good
| ----- | ----- | ------- | ------- bad
| ----- | ----- | ----- train
| ----- | ----- | ------- | ------- good
| ----- | --- capsules
| ----- | --- ...Plus précisément, les données réorganisées pour la configuration à 1 classe suivent l'arborescence de données de MVTec-AD. Pour chaque objet, les données comportent trois dossiers :
Notez que les masques de segmentation de vérité terrain multiclasses dans l'ensemble de données d'origine sont réindexés en masques binaires où 0 indique la normalité et 255 indique une anomalie.
De plus, les configurations à 2 classes peuvent être préparées de la même manière en modifiant les arguments de prepare_data.py.
Pour calculer les métriques de classification et de segmentation, veuillez vous référer à ./utils/metrics.py. Notez que nous prenons en compte les échantillons normaux lors du calcul des métriques de localisation. Ceci est différent de certains autres travaux qui ne tiennent pas compte des échantillons normaux de localisation.
Veuillez citer l'article suivant si cet ensemble de données aide votre projet :
@article { zou2022spot ,
title = { SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation } ,
author = { Zou, Yang and Jeong, Jongheon and Pemula, Latha and Zhang, Dongqing and Dabeer, Onkar } ,
journal = { arXiv preprint arXiv:2207.14315 } ,
year = { 2022 }
}Les données sont publiées sous la licence CC BY 4.0.


