Ce référentiel contient du code PyTorch pour Motif, formant des agents IA sur NetHack avec des fonctions de récompense dérivées des préférences d'un LLM.
Motif : Motivation intrinsèque issue de l'intelligence artificielle
de Martin Klissarov* & Pierluca D'Oro*, Shagun Sodhani, Roberta Raileanu, Pierre-Luc Bacon, Pascal Vincent, Amy Zhang et Mikael Henaff
Motif obtient les préférences d'un Large Language Model (LLM) sur des paires d'observations sous-titrées à partir d'un ensemble de données d'interactions collectées sur NetHack. Automatiquement, il distille le bon sens du LLM en une fonction de récompense utilisée pour former les agents avec un apprentissage par renforcement.
Pour faciliter les comparaisons, nous fournissons des courbes d'entraînement dans le fichier pickle motif_results.pkl , contenant un dictionnaire avec des tâches comme clés. Pour chaque tâche, nous fournissons une liste de pas de temps et de rendements moyens pour Motif et lignes de base, pour plusieurs graines.
Comme illustré dans la figure suivante, Motif comporte trois phases :
Nous détaillons chacune des phases en fournissant les ensembles de données, les commandes et les résultats bruts nécessaires pour reproduire les expériences présentées dans l'article.
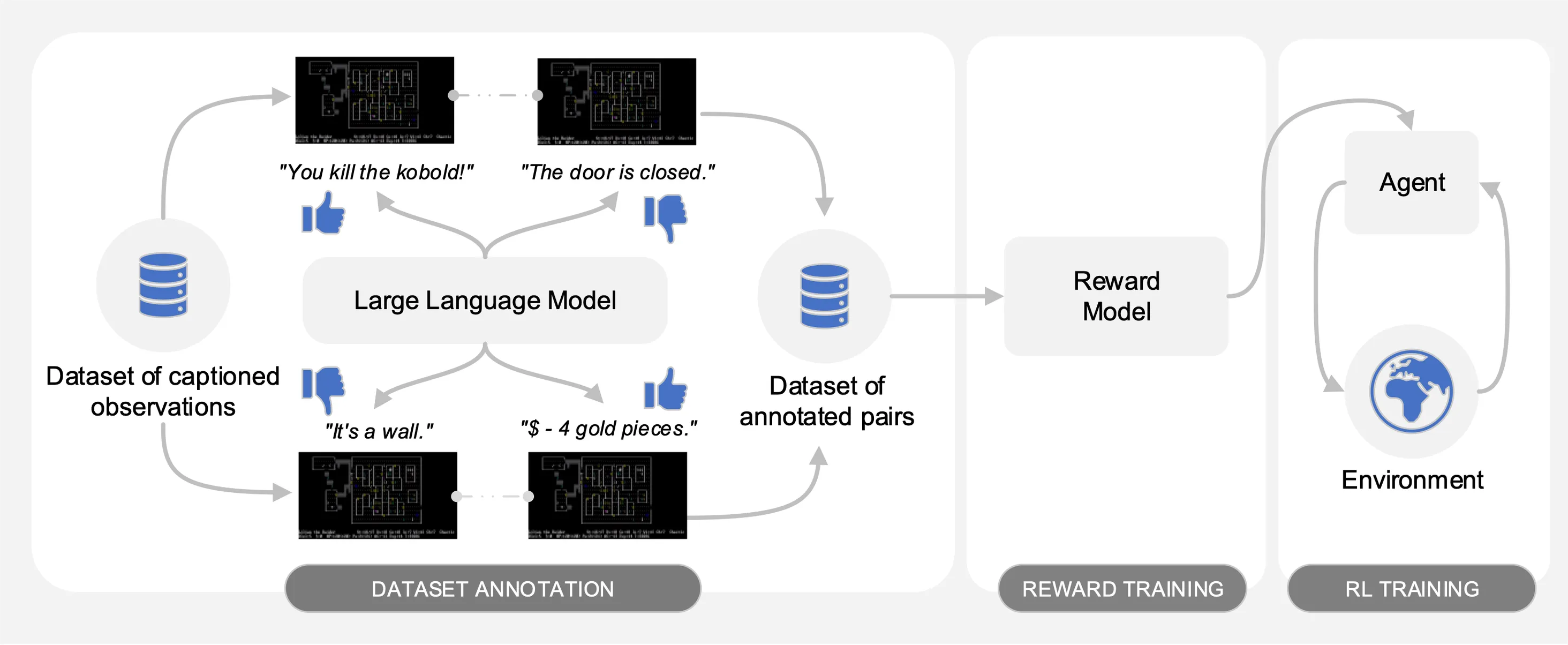
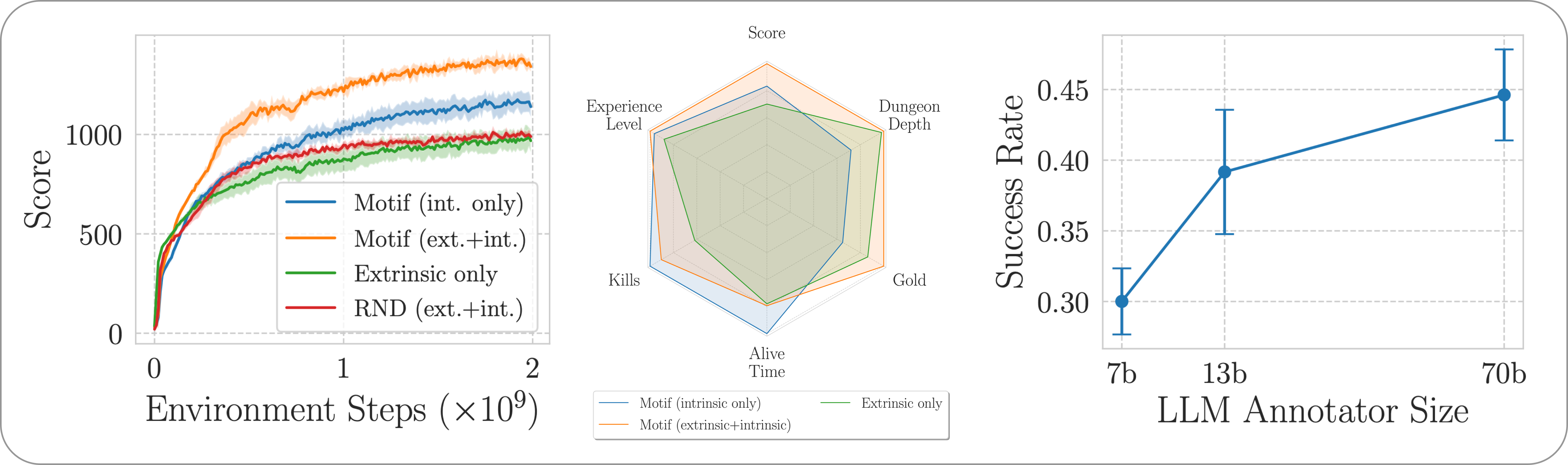
Nous évaluons les performances de Motif sur le jeu NetHack stimulant, ouvert et généré de manière procédurale via l'environnement d'apprentissage NetHack. Nous étudions comment Motif génère principalement des comportements intuitifs alignés sur l'humain, qui peuvent être facilement pilotés grâce à des modifications rapides, ainsi que ses propriétés de mise à l'échelle.

Pour installer les dépendances requises pour l'ensemble du pipeline, exécutez simplement pip install -r requirements.txt .
Pour la première phase, nous utilisons un ensemble de données de paires d'observations avec des légendes (c'est-à-dire des messages du jeu) collectées par des agents formés à l'apprentissage par renforcement pour maximiser le score du jeu. Nous fournissons l'ensemble de données dans ce référentiel. Nous stockons les différentes parties dans le répertoire motif_dataset_zipped , qui peut être décompressé à l'aide de la commande suivante.
cat motif_dataset_zipped/motif_dataset_part_* > motif_dataset.zip; unzip motif_dataset.zip; rm motif_dataset.zip
L'ensemble de données que nous fournissons présente un ensemble de préférences données par les modèles Llama 2, contenues dans le répertoire preference/ , en utilisant les différentes invites décrites dans l'article. Les noms des fichiers .npy contenant les annotations suivent le modèle llama{size}b_msg_{instruction}_{version} , où size est une taille LLM de l'ensemble {7,13,70} , instruction est une instruction introduite dans le invite donnée au LLM à partir de l'ensemble {defaultgoal, zeroknowledge, combat, gold, stairs} , version est la version du modèle d'invite à utiliser à partir de l'ensemble {default, reworded} . Nous fournissons ici un résumé des annotations disponibles :
| Annotation | Cas d'utilisation tiré du journal |
|---|---|
llama70b_msg_defaultgoal_default | Principales expériences |
llama70b_msg_combat_default | Se diriger vers le comportement de The Monster Slayer |
llama70b_msg_gold_default | S’orienter vers le comportement du Gold Collector |
llama70b_msg_stairs_default | Se diriger vers le comportement The Descender |
llama7b_msg_defaultgoal_default | Expérience de mise à l'échelle |
llama13b_msg_defaultgoal_default | Expérience de mise à l'échelle |
llama70b_msg_zeroknowledge_default | Expérience d'invite sans connaissance |
llama70b_msg_defaultgoal_reworded | Expérience de reformulation rapide |
Pour créer les annotations, nous utilisons vLLM et la version chat de Llama 2. si vous souhaitez générer vos propres annotations avec Llama 2 ou reproduire notre processus d'annotation, assurez-vous de pouvoir télécharger le modèle en suivant les instructions officielles (il peut prendre quelques jours pour avoir accès aux poids des modèles).
Le script d'annotation suppose que l'ensemble de données sera annoté en différents morceaux à l'aide de l'argument n-annotation-chunks . Cela permet d'obtenir un processus qui peut être parallélisé en fonction de la disponibilité des ressources et qui est robuste aux redémarrages/préemptions. Pour exécuter avec un seul morceau (c'est-à-dire pour traiter l'intégralité de l'ensemble de données) et annoter avec le modèle d'invite et la spécification de tâche par défaut, exécutez la commande suivante.
python -m scripts.annotate_pairs_dataset --directory motif_dataset
--prompt-version default --goal-key defaultgoal
--n-annotation-chunks 1 --chunk-number 0
--llm-size 70 --num-gpus 8
Notez que le comportement par défaut reprend le processus d'annotation en ajoutant les annotations au fichier spécifiant la configuration, sauf indication contraire avec l'indicateur --ignore-existing . Le nom du fichier « .npy » créé pour les annotations peut également être sélectionné manuellement à l'aide de l'indicateur --custom-annotator-string . Il est possible d'annoter en utilisant --llm-size 7 et --llm-size 13 en utilisant un seul GPU avec 32 Go de mémoire. Vous pouvez annoter en utilisant --llm-size 70 avec un nœud à 8 GPU. Nous fournissons ici des estimations approximatives des temps d'annotation avec les GPU NVIDIA V100s 32G, pour un ensemble de données de 100 000 paires, ce qui devrait permettre de reproduire approximativement la plupart de nos résultats (qui sont obtenus avec 500 000 paires).
| Modèle | Ressources à annoter |
|---|---|
| Lama 2 7b | ~ 32 heures GPU |
| Lama 2 13b | ~ 40 heures GPU |
| Lama 2 70b | ~ 72 heures GPU |
Dans la deuxième phase, nous distillons les préférences du LLM en une fonction de récompense par entropie croisée. Pour lancer l'entraînement de récompense avec les hyperparamètres par défaut, utilisez la commande suivante.
python -m scripts.train_reward --batch_size 1024 --num_workers 40
--reward_lr 1e-5 --num_epochs 10 --seed 777
--dataset_dir motif_dataset --annotator llama70b_msg_defaultgoal_default
--experiment standard_reward --train_dir train_dir/reward_saving_dir
La fonction de récompense sera entraînée via les annotations de l' annotator situées dans --dataset_dir . La fonction résultante sera ensuite enregistrée dans train_dir sous le sous-dossier --experiment .
Enfin, nous formons un agent avec les fonctions de récompense qui en résultent grâce à un apprentissage par renforcement. Pour former un agent sur la tâche NetHackScore-v1 , avec les hyperparamètres par défaut utilisés pour les expériences combinant des récompenses intrinsèques et extrinsèques, vous pouvez utiliser la commande suivante.
python -m scripts.main --algo APPO --env nle_fixed_eat_action --num_workers 24
--num_envs_per_worker 20 --batch_size 4096 --reward_scale 0.1 --obs_scale 255.0
--train_for_env_steps 2_000_000_000 --save_every_steps 10_000_000
--keep_checkpoints 5 --stats_avg 1000 --seed 777 --reward_dir train_dir/reward_saving_dir/standard_reward/
--experiment standard_motif --train_dir train_dir/rl_saving_dir
--extrinsic_reward 0.1 --llm_reward 0.1 --reward_encoder nle_torchbeast_encoder
--root_env NetHackScore-v1 --beta_count_exponent 3 --eps_threshold_quantile 0.5
Pour changer de tâche, modifiez simplement l'argument --root_env . Le tableau suivant indique explicitement les valeurs requises pour correspondre aux expériences présentées dans l'article. La tâche NetHackScore-v1 est apprise avec la valeur extrinsic_reward égale à 0.1 , tandis que toutes les autres tâches prennent une valeur de 10.0 , afin d'inciter l'agent à atteindre l'objectif.
| Environnement | root_env |
|---|---|
| score | NetHackScore-v1 |
| escalier | NetHackStaircase-v1 |
| escalier (niveau 3) | NetHackStaircaseLvl3-v1 |
| escalier (niveau 4) | NetHackStaircaseLvl4-v1 |
| oracle | NetHackOracle-v1 |
| oracle-sobre | NetHackOracleSober-v1 |
De plus, si vous souhaitez former des agents en utilisant uniquement la récompense intrinsèque provenant du LLM mais aucune récompense de l'environnement, définissez simplement --extrinsic_reward 0.0 . Dans les expériences intrinsèques de récompense uniquement, nous terminons l'épisode uniquement si l'agent meurt, plutôt que lorsqu'il atteint l'objectif. Ces environnements modifiés sont énumérés dans le tableau suivant.
| Environnement | root_env |
|---|---|
| escalier (niveau 3) - intrinsèque seulement | NetHackStaircaseLvl3Continual-v1 |
| escalier (niveau 4) - intrinsèque seulement | NetHackStaircaseLvl4Continual-v1 |
Nous fournissons également un script pour visualiser vos agents RL formés. Cela peut fournir des informations importantes sur son comportement, mais générera également les principaux messages pour chaque épisode, ce qui peut aider à comprendre ce pour quoi il essaie d'optimiser. Il vous suffit d'exécuter la commande suivante.
python -m scripts.visualize --train_dir train_dir/rl_saving_dir --experiment standard_motif
Si vous développez notre travail ou le trouvez utile, veuillez le citer en utilisant le bibtex suivant.
@article{klissarovdoro2023motif,
title={Motif: Intrinsic Motivation From Artificial Intelligence Feedback},
author={Klissarov, Martin and D’Oro, Pierluca and Sodhani, Shagun and Raileanu, Roberta and Bacon, Pierre-Luc and Vincent, Pascal and Zhang, Amy and Henaff, Mikael},
year={2023},
month={9},
journal={arXiv preprint arXiv:2310.00166}
}
La majorité de Motif est sous licence CC-BY-NC, mais des parties du projet sont disponibles sous des conditions de licence distinctes : sample-factory est sous licence MIT.


