

MPIRE , abréviation de MultiProcessing Is Really Easy, est un package Python pour le multitraitement. MPIRE est plus rapide dans la plupart des scénarios, offre plus de fonctionnalités et est généralement plus convivial que le package multitraitement par défaut. Il combine les fonctions pratiques de type map de multiprocessing.Pool avec les avantages de l'utilisation d'objets partagés de copie sur écriture de multiprocessing.Process , ainsi que l'état du travailleur facile à utiliser, les informations sur le travailleur, les fonctions d'initialisation et de sortie du travailleur, les délais d'attente et fonctionnalité de barre de progression.
La documentation complète est disponible sur https://sybrenjansen.github.io/mpire/.
map / map_unordered / imap / imap_unordered / apply / apply_asyncfork )rich et portables sont pris en charge)daemonMPIRE est testé sur Linux, macOS et Windows. Pour les utilisateurs Windows et macOS, il existe quelques mises en garde mineures connues, qui sont documentées dans le chapitre Dépannage.
Via pip (PyPi) :
pip install mpireMPIRE est également disponible via conda-forge :
conda install -c conda-forge mpire Supposons que vous ayez une fonction chronophage qui reçoit des entrées et renvoie ses résultats. Des fonctions simples comme celles-ci sont connues sous le nom de problèmes parallèles embarrassants, des fonctions qui nécessitent peu ou pas d'effort pour se transformer en une tâche parallèle. Paralléliser une fonction simple car cela peut être aussi simple que d'importer multiprocessing et d'utiliser la classe multiprocessing.Pool :
import time
from multiprocessing import Pool
def time_consuming_function ( x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
with Pool ( processes = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) MPIRE peut être utilisé presque en remplacement du multiprocessing . Nous utilisons la classe mpire.WorkerPool et appelons l'une des fonctions map disponibles :
from mpire import WorkerPool
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) Les différences de code sont minimes : il n'est pas nécessaire d'apprendre une toute nouvelle syntaxe de multitraitement si vous êtes habitué au multiprocessing vanille. Cependant, la fonctionnalité supplémentaire disponible est ce qui distingue MPIRE.
Supposons que nous voulions connaître l'état de la tâche en cours : combien de tâches sont terminées, combien de temps avant que le travail ne soit prêt ? C'est aussi simple que de définir le paramètre progress_bar sur True :
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )Et il affichera une barre de progression tqdm bien formatée.
MPIRE propose également un tableau de bord, pour lequel vous devez installer des dépendances supplémentaires. Voir Tableau de bord pour plus d'informations.
Remarque : Les objets partagés de copie sur écriture ne sont disponibles que pour la méthode de démarrage fork . Pour threading les objets sont partagés tels quels. Pour les autres méthodes de démarrage, les objets partagés sont copiés une fois pour chaque travailleur, ce qui peut toujours être mieux qu'une fois par tâche.
Si vous souhaitez partager un ou plusieurs objets entre tous les travailleurs, vous pouvez utiliser l'option de copie sur écriture shared_objects de MPIRE. MPIRE ne transmettra ces objets qu'une seule fois pour chaque travailleur sans copie/sérialisation. Ce n'est que lorsque vous modifiez l'objet dans la fonction de travail qu'il commencera à le copier pour ce travailleur.
def time_consuming_function ( some_object , x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
def main ():
some_object = ...
with WorkerPool ( n_jobs = 5 , shared_objects = some_object ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )Voir shared_objects pour plus de détails.
Les Workers peuvent être initialisés à l'aide de la fonctionnalité worker_init . Avec worker_state vous pouvez charger un modèle ou configurer une connexion à une base de données, etc. :
def init ( worker_state ):
# Load a big dataset or model and store it in a worker specific worker_state
worker_state [ 'dataset' ] = ...
worker_state [ 'model' ] = ...
def task ( worker_state , idx ):
# Let the model predict a specific instance of the dataset
return worker_state [ 'model' ]. predict ( worker_state [ 'dataset' ][ idx ])
with WorkerPool ( n_jobs = 5 , use_worker_state = True ) as pool :
results = pool . map ( task , range ( 10 ), worker_init = init ) De même, vous pouvez utiliser la fonctionnalité worker_exit pour permettre à MPIRE d'appeler une fonction chaque fois qu'un travailleur se termine. Vous pouvez même laisser cette fonction de sortie renvoyer des résultats, qui pourront être obtenus ultérieurement. Consultez la section worker_init et worker_exit pour plus d'informations.
Lorsque votre configuration multitraitement ne fonctionne pas comme vous le souhaitez et que vous n'avez aucune idée de la cause, il existe la fonctionnalité d'informations sur les travailleurs. Cela vous donnera un aperçu de votre configuration, mais cela ne profilera pas la fonction que vous exécutez (il existe d'autres bibliothèques pour cela). Au lieu de cela, il profile le temps de démarrage, le temps d'attente et le temps de travail du travailleur. Lorsque les fonctions d'initialisation et de sortie du travailleur sont fournies, il les chronométre également.
Peut-être que vous envoyez beaucoup de données via la file d'attente des tâches, ce qui augmente le temps d'attente. Quoi qu'il en soit, vous pouvez activer et récupérer les informations à l'aide de l'indicateur enable_insights et de la fonction mpire.WorkerPool.get_insights , respectivement :
with WorkerPool ( n_jobs = 5 , enable_insights = True ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))
insights = pool . get_insights ()Consultez les informations sur les travailleurs pour un exemple plus détaillé et le résultat attendu.
Les délais d'attente peuvent être définis séparément pour les fonctions target, worker_init et worker_exit . Lorsqu'un délai d'attente a été défini et atteint, il lancera une TimeoutError :
def init ():
...
def exit_ ():
...
# Will raise TimeoutError, provided that the target function takes longer
# than half a second to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), task_timeout = 0.5 )
# Will raise TimeoutError, provided that the worker_init function takes longer
# than 3 seconds to complete or the worker_exit function takes longer than
# 150.5 seconds to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), worker_init = init , worker_exit = exit_ ,
worker_init_timeout = 3.0 , worker_exit_timeout = 150.5 ) Lorsque vous utilisez threading comme méthode de démarrage, MPIRE ne pourra pas interrompre certaines fonctions, comme time.sleep .
Voir les délais d'attente pour plus de détails.
MPIRE a été évalué sur trois critères différents : le calcul numérique, le calcul avec état et l'initialisation coûteuse. Plus de détails sur ces benchmarks peuvent être trouvés dans cet article de blog. Tout le code de ces benchmarks peut être trouvé dans ce projet.
En bref, les principales raisons pour lesquelles MPIRE est plus rapide sont :
fork est disponible, nous pouvons utiliser des objets partagés avec copie sur écriture, ce qui réduit le besoin de copier des objets qui doivent être partagés sur des processus enfants.Le graphique suivant montre les résultats normalisés moyens des trois critères. Les résultats des tests de référence individuels peuvent être trouvés dans le billet de blog. Les tests ont été exécutés sur une machine Linux dotée de 20 cœurs, avec hyperthreading désactivé et 200 Go de RAM. Pour chaque tâche, des expériences ont été réalisées avec différents nombres de processus/travailleurs et les résultats ont été moyennés sur 5 exécutions.
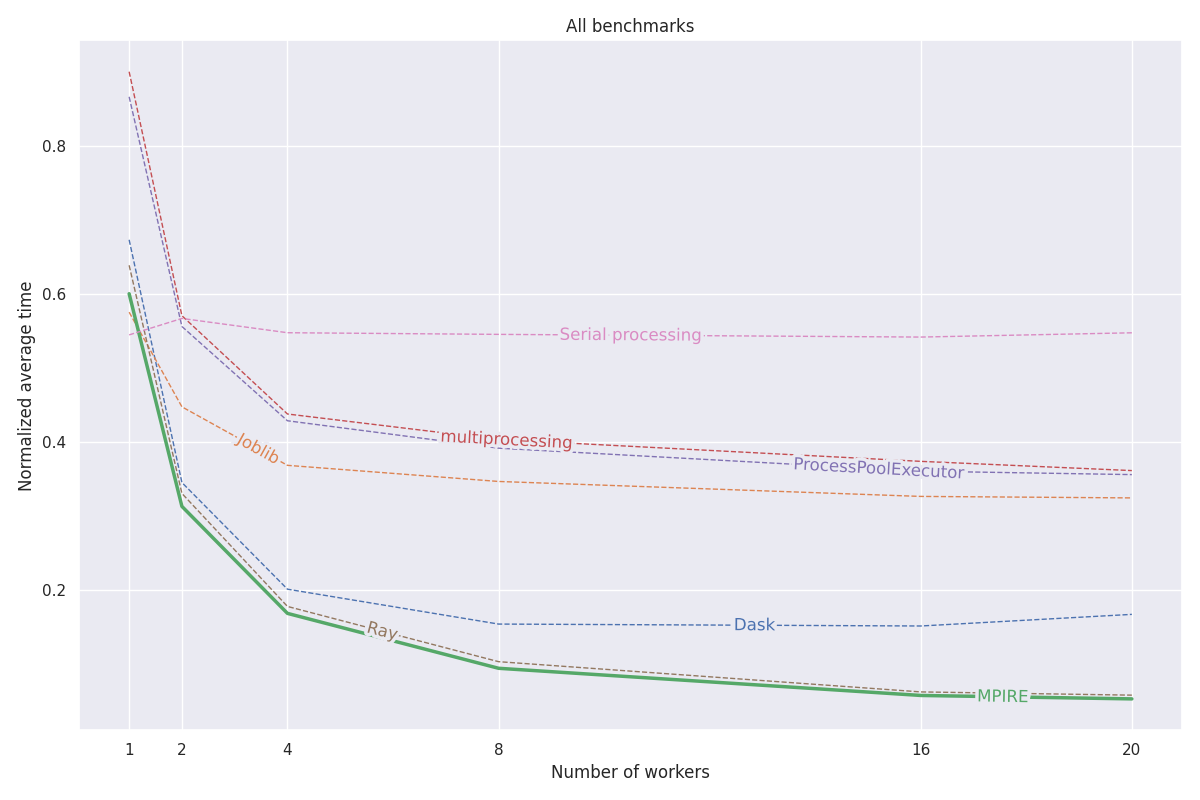
Consultez la documentation complète sur https://sybrenjansen.github.io/mpire/ pour plus d'informations sur toutes les autres fonctionnalités de MPIRE.
Si vous souhaitez créer la documentation vous-même, veuillez installer les dépendances de la documentation en exécutant :
pip install mpire[docs]ou
pip install .[docs]La documentation peut ensuite être construite en utilisant Python <= 3.9 et en exécutant :
python setup.py build_docs La documentation peut également être créée directement à partir du dossier docs . Dans ce cas, MPIRE doit être installé et disponible dans votre environnement de travail actuel. Exécutez ensuite :
make html dans le dossier docs .


