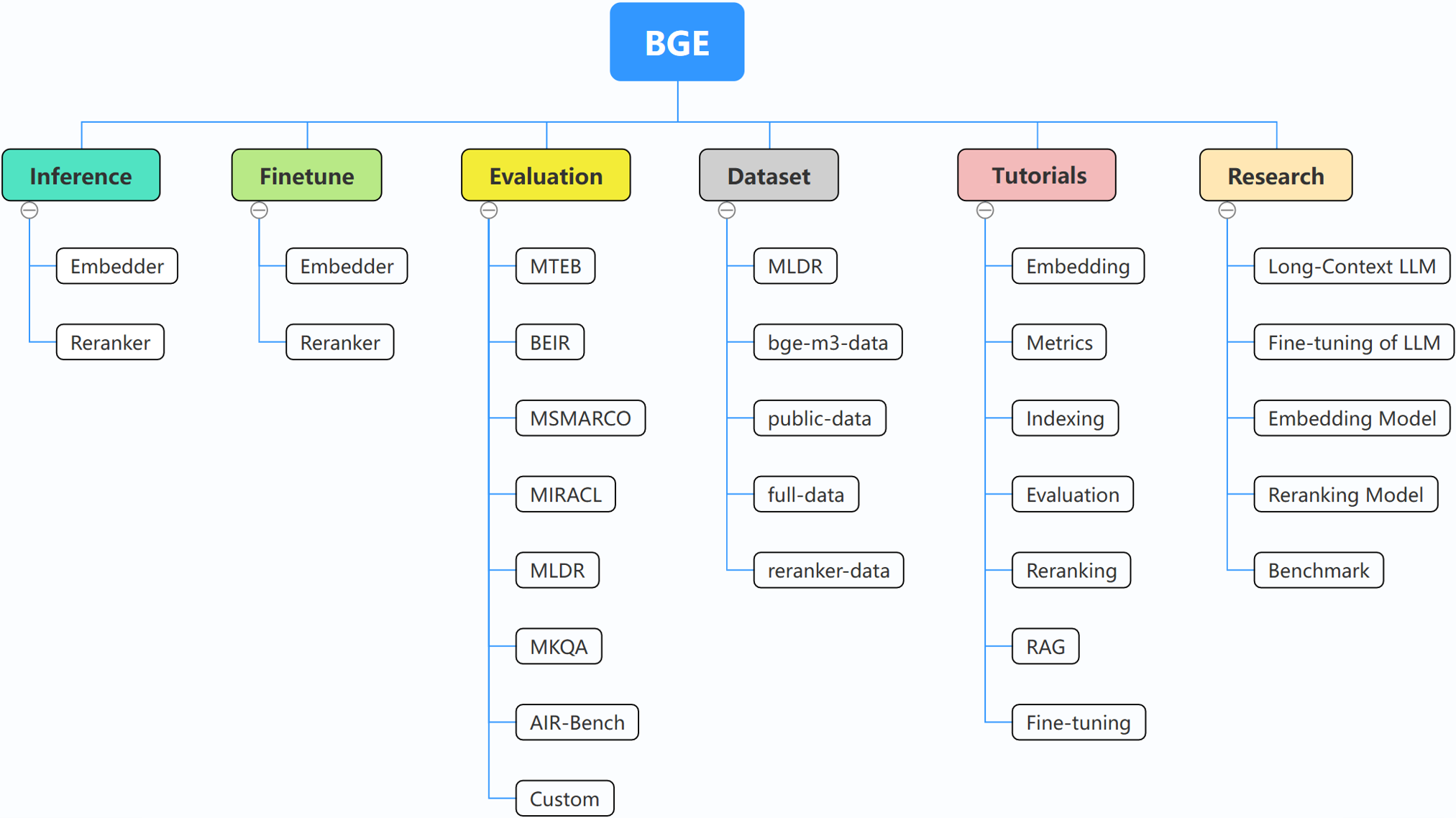
FlagEmbedding
1.3.2


Actualités | Installation | Démarrage rapide | Communauté | Projets | Liste des modèles | Contributeur | Citation | Licence
Anglais | Chine
BGE (BAAI General Embedding) se concentre sur les LLM augmentés par récupération, comprenant actuellement les projets suivants :
29/10/2024 : ? Nous avons créé le groupe WeChat pour BGE. Scannez le code QR pour rejoindre le chat de groupe ! Pour recevoir un message de première main sur nos mises à jour et nos nouvelles versions, ou pour avoir des questions ou des idées, rejoignez-nous maintenant !

22/10/2024 : Nous publions un autre modèle intéressant : OmniGen, qui est un modèle de génération d'images unifié prenant en charge diverses tâches. OmniGen peut accomplir des tâches complexes de génération d'images sans avoir besoin de plugins supplémentaires tels que ControlNet, IP-Adapter ou de modèles auxiliaires tels que la détection de pose et la détection de visage.
10/09/2024 : Présentation de MemoRAG , un pas en avant vers RAG 2.0 en plus de la découverte de connaissances inspirée de la mémoire (dépôt : https://github.com/qhjqhj00/MemoRAG, article : https://arxiv.org/pdf/ 2409.05591v1)
02/09/2024 : Début de la maintenance des tutoriels. Le contenu sera activement mis à jour et enrichi, restez à l'écoute !
26/07/2024 : publication d'un nouveau modèle d'intégration bge-en-icl, un modèle d'intégration qui intègre des capacités d'apprentissage en contexte, qui, en fournissant des exemples de requêtes-réponses pertinentes pour les tâches, peut encoder des requêtes sémantiquement plus riches, améliorant encore la sémantique capacité de représentation des intégrations.
26/07/2024 : Publier un nouveau modèle d'intégration bge-multilingual-gemma2, un modèle d'intégration multilingue basé sur gemma-2-9b, qui prend en charge plusieurs langues et diverses tâches en aval, réalisant un nouveau SOTA sur des benchmarks multilingues (MIRACL, MTEB-fr , et MTEB-pl).
26/07/2024 : publication d'un nouveau reranker léger bge-reranker-v2.5-gemma2-lightweight, un reranker léger basé sur gemma-2-9b, qui prend en charge la compression de jetons et les opérations légères par couches, peut toujours garantir de bonnes performances tout en économisant une quantité importante de ressources.
BAAI/bge-reranker-base et BAAI/bge-reranker-large , qui sont plus puissants que le modèle d'intégration. Nous vous recommandons de les utiliser/affiner pour reclasser les documents les plus importants renvoyés par l'intégration de modèles.bge-*-v1.5 pour atténuer le problème de la distribution de similarité et améliorer sa capacité de récupération sans instruction.bge-large-* (abréviation de BAAI General Embedding), classé 1er sur les benchmarks MTEB et C-MTEB ! ? ?Si vous ne souhaitez pas affiner les modèles, vous pouvez installer le package sans la dépendance finetune :
pip install -U FlagEmbedding
Si vous souhaitez affiner les modèles, vous pouvez installer le package avec la dépendance finetune :
pip install -U FlagEmbedding[finetune]
Cloner le référentiel et installer
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install .[finetune]
Pour le développement en mode modifiable :
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install -e .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install -e .[finetune]
Tout d’abord, chargez l’un des modèles d’intégration BGE :
from FlagEmbedding import FlagAutoModel
model = FlagAutoModel.from_finetuned('BAAI/bge-base-en-v1.5',
query_instruction_for_retrieval="Represent this sentence for searching relevant passages:",
use_fp16=True)
Ensuite, introduisez quelques phrases dans le modèle et obtenez leurs intégrations :
sentences_1 = ["I love NLP", "I love machine learning"]
sentences_2 = ["I love BGE", "I love text retrieval"]
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
Une fois que nous avons obtenu les plongements, nous pouvons calculer la similarité par produit interne :
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
Pour plus de détails, vous pouvez vous référer à l'inférence d'intégration, l'inférence de reclassement, le réglage fin de l'intégration, le fintune de reclassement, l'évaluation.
Si vous n'êtes pas familier avec l'un des concepts associés, veuillez consulter le didacticiel. Si ce n'est pas le cas, faites-le-nous savoir.
Pour des sujets plus intéressants liés à BGE, jetez un œil à la recherche.
Nous entretenons activement la communauté de BGE et FlagEmbedding. Faites-nous savoir si vous avez des suggestions ou des idées !
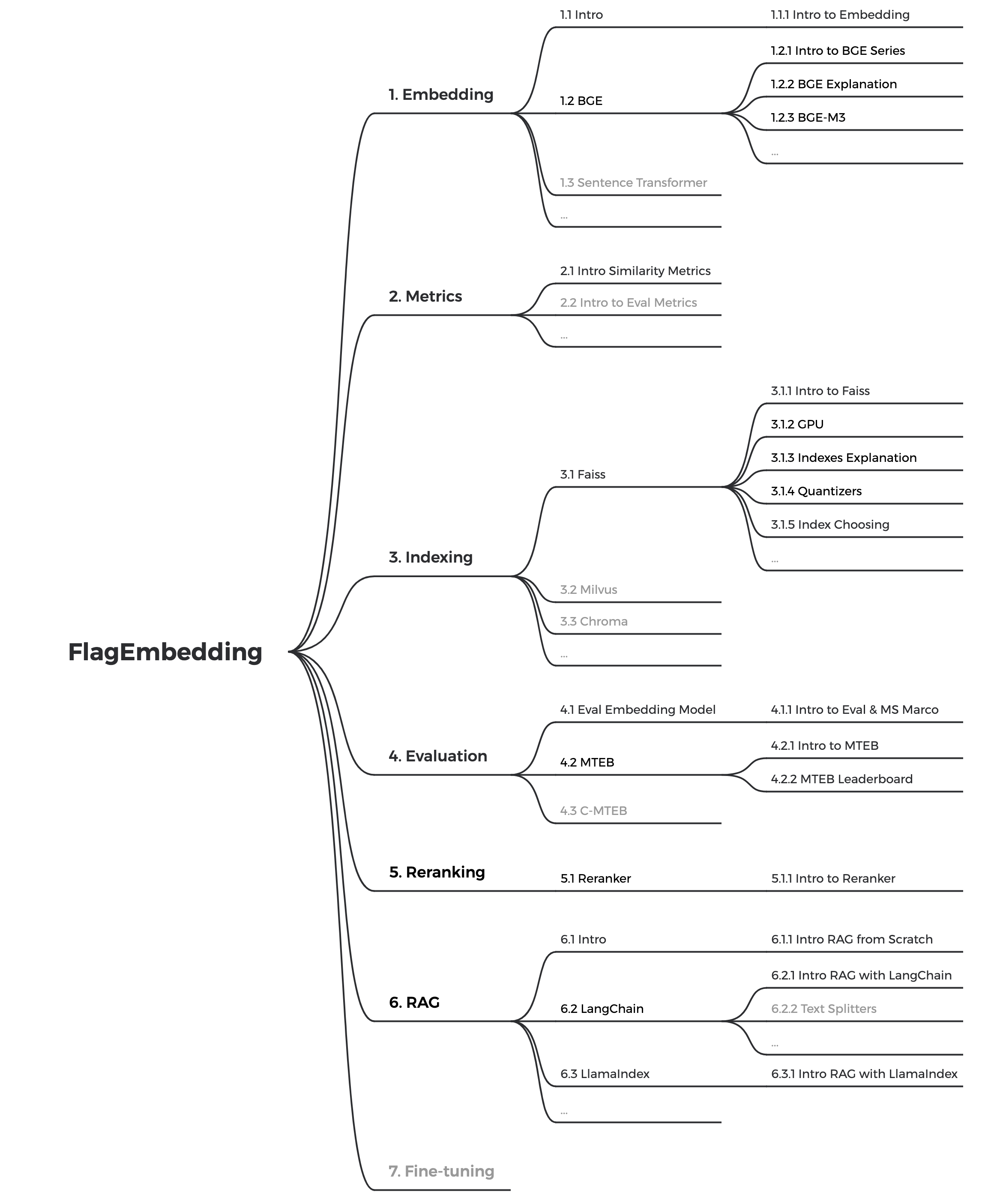
Nous mettons actuellement à jour les didacticiels, notre objectif est de créer un didacticiel complet et détaillé pour les débutants en matière de récupération de texte et de RAG. Restez à l'écoute!
Les contenus suivants seront publiés dans les semaines à venir :
bge est l' BAAI general embedding .
| Modèle | Langue | Description | instruction de requête pour la récupération |
|---|---|---|---|
| BAAI/bge-en-icl | Anglais | Un modèle d'intégration basé sur LLM avec des capacités d'apprentissage en contexte, qui peut exploiter pleinement le potentiel du modèle sur la base de quelques exemples de prises de vue. | Fournissez librement des instructions et quelques exemples de plans en fonction de la tâche donnée. |
| BAAI/bge-multilingue-gemma2 | Multilingue | Un modèle d'intégration multilingue basé sur LLM, formé sur un large éventail de langues et de tâches. | Fournir des instructions basées sur la tâche donnée. |
| BAAI/bge-m3 | Multilingue | Multifonctionnalité (récupération dense, récupération clairsemée, multi-vecteur (colbert)), multilingualité et multi-granularité (8 192 jetons) | |
| LM-Cocktail | Anglais | des modèles affinés (Llama et BGE) qui peuvent être utilisés pour reproduire les résultats de LM-Cocktail | |
| BAAI/llm-embedder | Anglais | un modèle d'intégration unifié pour prendre en charge divers besoins d'augmentation de récupération pour les LLM | Voir README |
| BAAI/bge-reranker-v2-m3 | Multilingue | un modèle d'encodeur croisé léger, possède de fortes capacités multilingues, facile à déployer, avec une inférence rapide. | |
| BAAI/bge-reranker-v2-gemma | Multilingue | un modèle d'encodeur croisé adapté aux contextes multilingues, fonctionne bien en termes de maîtrise de l'anglais et de capacités multilingues. | |
| BAAI/bge-reranker-v2-minicpm-layerwise | Multilingue | un modèle d'encodeur croisé adapté aux contextes multilingues, fonctionne bien en anglais et en chinois, permet la liberté de sélectionner les couches pour la sortie, facilitant ainsi l'inférence accélérée. | |
| BAAI/bge-reranker-v2.5-gemma2-lightweight | Multilingue | un modèle d'encodeur croisé adapté aux contextes multilingues, fonctionne bien en anglais et en chinois, permet la liberté de sélectionner des couches, de compresser le rapport et de compresser les couches pour la sortie, facilitant ainsi l'inférence accélérée. | |
| BAAI/bge-reranker-large | Chinois et anglais | un modèle cross-encodeur plus précis mais moins efficace | |
| BAAI/bge-reranker-base | Chinois et anglais | un modèle cross-encodeur plus précis mais moins efficace | |
| BAAI/bge-large-fr-v1.5 | Anglais | version 1.5 avec une distribution de similarité plus raisonnable | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-fr-v1.5 | Anglais | version 1.5 avec une distribution de similarité plus raisonnable | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-fr-v1.5 | Anglais | version 1.5 avec une distribution de similarité plus raisonnable | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh-v1.5 | Chinois | version 1.5 avec une distribution de similarité plus raisonnable | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh-v1.5 | Chinois | version 1.5 avec une distribution de similarité plus raisonnable | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh-v1.5 | Chinois | version 1.5 avec une distribution de similarité plus raisonnable | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-large-fr | Anglais | Modèle d'intégration qui mappe le texte en vecteur | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-fr | Anglais | un modèle à l'échelle de base mais avec une capacité similaire à bge-large-en | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-fr | Anglais | un modèle à petite échelle mais avec des performances compétitives | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh | Chinois | Modèle d'intégration qui mappe le texte en vecteur | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh | Chinois | un modèle de base mais avec une capacité similaire à bge-large-zh | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-petit-zh | Chinois | un modèle à petite échelle mais avec des performances compétitives | 为这个句子生成表示以用于检索相关文章: |
Merci à tous nos contributeurs pour leurs efforts et bienvenue chaleureusement aux nouveaux membres à nous rejoindre !
Si vous trouvez ce référentiel utile, pensez à donner une étoile et une citation
@misc{bge_m3,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Chen, Jianlv and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{cocktail,
title={LM-Cocktail: Resilient Tuning of Language Models via Model Merging},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Xingrun Xing},
year={2023},
eprint={2311.13534},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{llm_embedder,
title={Retrieve Anything To Augment Large Language Models},
author={Peitian Zhang and Shitao Xiao and Zheng Liu and Zhicheng Dou and Jian-Yun Nie},
year={2023},
eprint={2310.07554},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
FlagEmbedding est sous licence MIT.


