chrono_lens
v1.1.1
Il s'agit du référentiel public du projet d'analyse des caméras de circulation tel que publié sur le blog du campus scientifique des données de l'Office for National Statistics dans le cadre des indicateurs plus rapides de l'ONS sur le coronavirus (par exemple - Activité des caméras de circulation - 10 septembre 2020) et de la méthodologie sous-jacente. Le projet a utilisé Google Compute Platform (GCP) pour permettre une solution évolutive, mais la méthodologie sous-jacente est indépendante de la plate-forme ; ce référentiel contient notre implémentation orientée GCP.
Un exemple de résultat produit pour l’indicateur Coronavirus Faster est présenté ci-dessous.
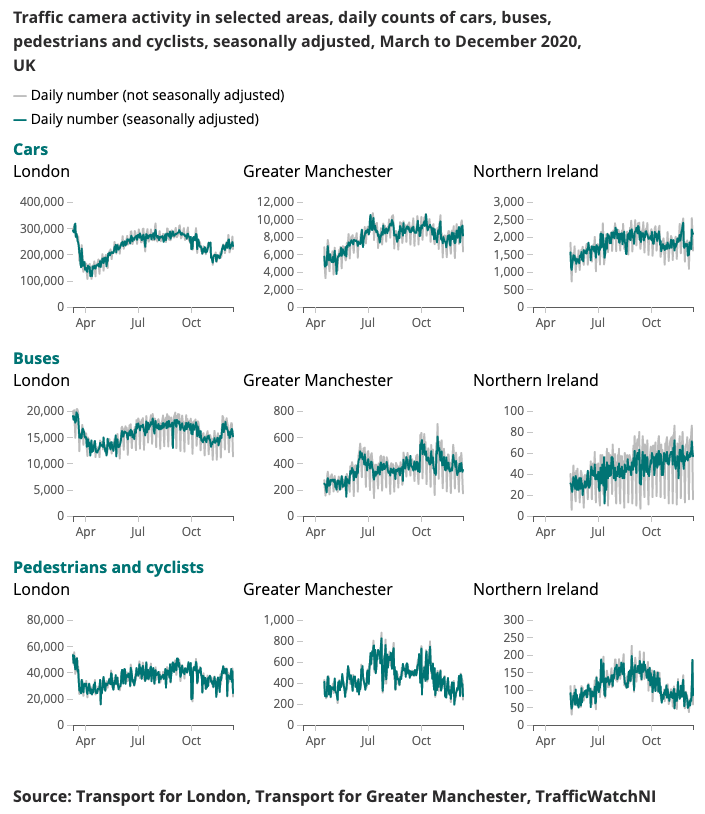
Comprendre l'évolution des modèles de mobilité et de comportement en temps réel a été un objectif majeur de la réponse du gouvernement au coronavirus (COVID-19). Le Data Science Campus a exploré des sources de données alternatives qui pourraient donner des indications sur la manière d’estimer les niveaux de distance sociale et de suivre la reprise de la société et de l’économie à mesure que les conditions de confinement s’assouplissent.
Les caméras de circulation sont une source de données largement accessible au public permettant aux professionnels des transports et au public d'évaluer la circulation dans différentes parties du pays via Internet. Les images produites par les caméras de circulation sont accessibles au public, à faible résolution et ne permettent pas d'identifier individuellement les personnes ou les véhicules. Ils diffèrent des vidéosurveillance utilisées pour la sécurité publique et les forces de l'ordre pour la reconnaissance automatique des plaques d'immatriculation (ANPR) ou pour surveiller la vitesse du trafic.
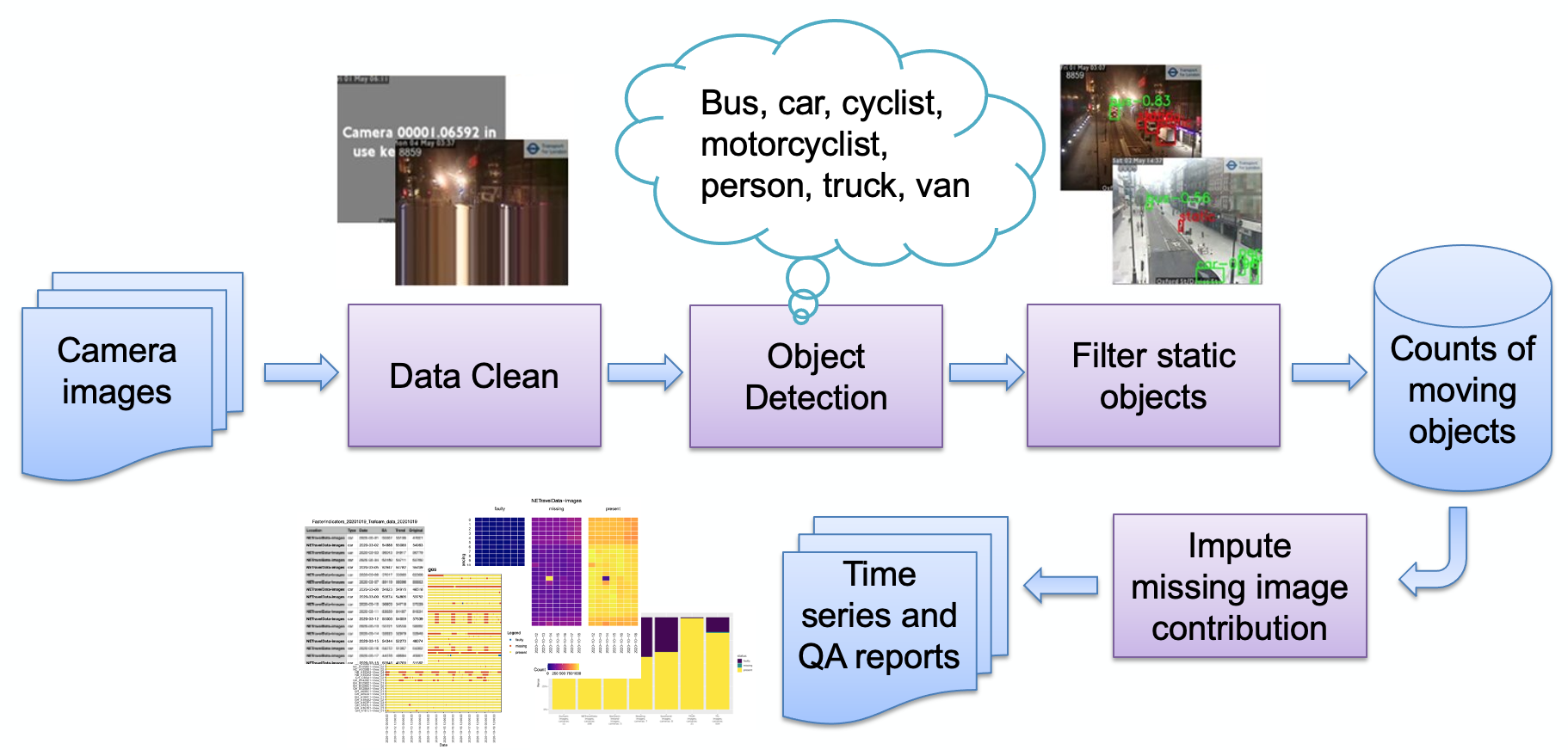
Les principales étapes du pipeline, telles que décrites dans l'image, sont :
Ingestion d'images
Détection d'image défectueuse
Détection d'objet
Détection d'objets statiques
Stockage des décomptes résultants
Les décomptes peuvent ensuite être traités davantage (désaisonnalisation, imputation des valeurs manquantes) et transformés en rapports au besoin. Nous passerons brièvement en revue les principales étapes du pipeline.
Un ensemble de sources de caméra (images JPEG hébergées sur le Web) est sélectionné par l'utilisateur et fourni sous forme de liste d'URL à l'utilisateur. Un exemple de code est fourni pour obtenir des images publiques de Transport for London, ainsi qu'un code spécialisé pour extraire les données de trafic NE directement de l'Observatoire urbain de l'Université de Newcastle.
Les caméras peuvent être indisponibles pour diverses raisons (défaillance du système, flux désactivé par l'opérateur local, etc.) et celles-ci pourraient amener le modèle à générer de faux comptes d'objets (par exemple, une petite tache peut ressembler à un bus distant). Un exemple d'une telle image est : 
Ces images ont jusqu'à présent toutes suivi le modèle d'une image très synthétique, composée d'une couleur de fond plate et d'un texte superposé (par rapport à une image d'une scène naturelle). Ces images sont actuellement détectées en réduisant la profondeur de couleur (en rassemblant des couleurs similaires), puis en examinant la fraction la plus élevée de l'image occupée par une seule couleur. Une fois ce seuil dépassé, nous déterminons que l’image est synthétique et la marquons comme défectueuse. D'autres défauts peuvent survenir en raison de l'encodage, tels que : 
Ici, le flux de la caméra est bloqué et la dernière ligne « en direct » a été répétée ; nous détectons cela en vérifiant si la ligne inférieure de l'image correspond à la ligne supérieure (dans les limites du seuil). Si tel est le cas, la ligne suivante ci-dessus est vérifiée pour une correspondance et ainsi de suite jusqu'à ce que les lignes ne correspondent plus ou que nous manquions de lignes. Si le nombre de lignes correspondantes est supérieur à un seuil, il est peu probable que l'image génère des données utiles et est donc signalée comme défectueuse.
Notez que différents fournisseurs d'images utilisent différentes manières d'indiquer qu'une caméra n'est pas disponible ; notre technique de détection repose sur l'utilisation de peu de couleurs, c'est-à-dire une image purement synthétique. Si une image plus naturelle est utilisée, notre technique risque de ne pas fonctionner. Une alternative consiste à conserver une « bibliothèque » d’images défaillantes et à rechercher des similitudes, ce qui peut mieux fonctionner avec des images plus naturelles.
Le processus de détection d'objets identifie à la fois les objets statiques et en mouvement, à l'aide d'un Faster-RCNN pré-entraîné fourni par l'Observatoire urbain de l'Université de Newcastle. Le modèle a été formé sur 10 000 images de caméras de circulation du nord-est de l’Angleterre, puis validé par l’ONS Data Science Campus pour confirmer que le modèle était utilisable avec des images de caméras d’autres régions du Royaume-Uni. Il détecte les types d'objets suivants : voiture, camionnette, camion, bus, piéton, cycliste, motocycliste.
Comme nous visons à détecter l’activité, il est important de filtrer les objets statiques à l’aide d’informations temporelles. Les images sont échantillonnées à intervalles de 10 minutes, de sorte que les méthodes traditionnelles de détection d'arrière-plan en vidéo, telles que le mélange de gaussiennes, ne conviennent pas.
Tous les piétons et véhicules classés lors de la détection d'objets seront définis comme statiques et supprimés du décompte final s'ils apparaissent également en arrière-plan. L'image ci-dessous montre un exemple de résultats du masque statique, où les voitures garées dans l'image (a) sont identifiées comme statiques et supprimées. Un avantage supplémentaire est que le masque statique peut aider à supprimer les fausses alarmes. Par exemple, dans l'image (b), la poubelle est identifiée à tort comme un piéton lors de la détection d'objet mais filtrée comme arrière-plan statique.

Les résultats sont simplement stockés sous forme de tableau, le schéma enregistrant l'identifiant de la caméra, la date, l'heure, les décomptes associés par type d'objet (voiture, camionnette, piéton, etc.), si une image est défectueuse ou si une image est manquante.
Initialement, le système a été conçu pour être cloud natif, afin de permettre l'évolutivité ; cependant, cela introduit une barrière à l'entrée : vous devez avoir un compte auprès d'un fournisseur de cloud, savoir comment sécuriser l'infrastructure, etc. Dans cette optique, nous avons également rétroporté le code pour qu'il fonctionne sur une machine autonome. (ou "hôte local") pour permettre à un utilisateur intéressé d'exécuter simplement le système sur son propre ordinateur portable. Les deux implémentations sont maintenant décrites ci-dessous.
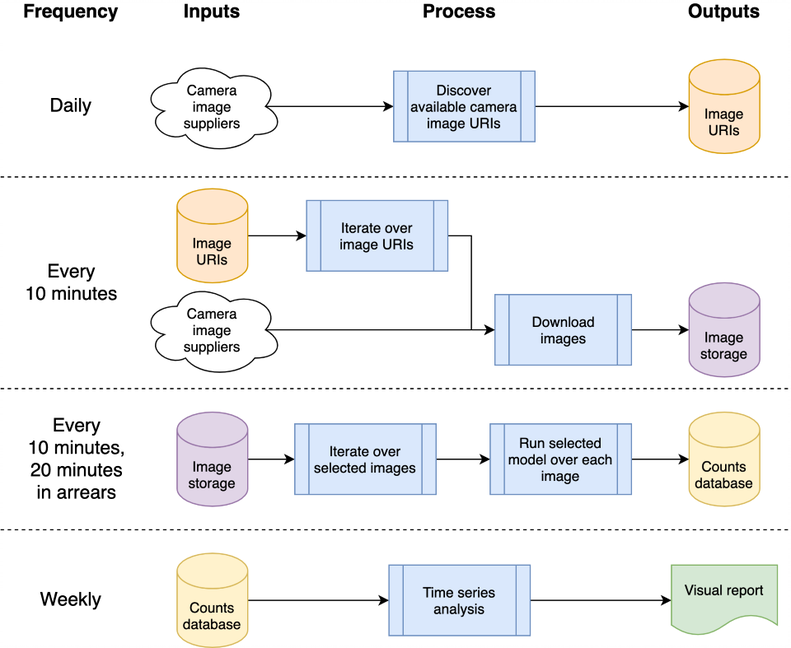
Cette architecture peut être mappée sur une seule machine ou sur un système cloud ; nous avons choisi d'utiliser Google Compute Platform (GCP), mais d'autres plateformes telles qu'Amazon Web Services (AWS) ou Azure de Microsoft fourniraient des services relativement équivalents.
Le système est hébergé sous forme de « fonctions cloud », qui sont du code autonome et sans état qui peut être appelé à plusieurs reprises sans provoquer de corruption – une considération clé pour augmenter la robustesse des fonctions. Les rafales de traitement quotidiennes et « toutes les 10 minutes » sont orchestrées à l'aide du planificateur de GCP pour déclencher un sujet Pub/Sub GCP selon le calendrier souhaité. Les fonctions cloud GCP sont enregistrées pour le sujet et sont démarrées chaque fois que le sujet est déclenché.
Le traitement des images pour détecter les véhicules et les piétons entraîne l'écriture du nombre d'objets dans une base de données pour une analyse ultérieure sous forme de série chronologique. La base de données est utilisée pour partager des données entre la collecte de données et l'analyse de séries chronologiques, réduisant ainsi le couplage. Nous utilisons BigQuery au sein de GCP comme base de données étant donné sa large prise en charge dans d'autres produits GCP, tels que Data Studio pour la visualisation des données ; l'implémentation de l'hôte local stocke les CSV quotidiens par comparaison, pour supprimer toute dépendance à l'égard d'une base de données particulière ou d'une autre infrastructure.
Le code source associé à GCP est stocké dans le dossier cloud ; celui-ci télécharge les images, les traite pour compter les objets, stocke les décomptes dans une base de données et produit (hebdomadairement) une analyse de séries chronologiques. Toute la documentation et le code source sont stockés dans le dossier cloud ; reportez-vous au Cloud README.md pour un aperçu de l'architecture et comment installer votre propre instance à l'aide de nos scripts dans votre espace de projet GCP. Le projet peut être intégré à GitHub, permettant le déploiement automatique et l'exécution de tests automatiquement à partir des validations vers un projet GitHub local ; ceci est également documenté dans le Cloud README.md. Le code de support Cloud est également stocké dans le module chrono_lens.gcloud , permettant aux scripts de ligne de commande de prendre en charge GCP, aux côtés du code de la fonction Cloud dans le dossier cloud .
Le code autonome d'une seule machine (« localhost ») est contenu dans le module chrono_lens.localhost . Le processus suit le même flux que la variante GCP, bien qu'il utilise une seule machine et que chaque fichier python dans chrono_lens.localhost correspond aux fonctions cloud de GCP. Reportez-vous à README-localhost.md pour plus de détails.
Nous décrivons maintenant les différentes étapes et prérequis pour installer le système, étant donné que les implémentations de GCP et d'hébergement local nécessitent au moins une installation locale.
La création d'un environnement virtuel est fortement conseillée permettant un environnement de travail isolé. Des exemples de bons environnements de travail incluent conda, pyenv et poerty.
Notez que les dépendances sont déjà contenues dans requirements.txt , veuillez donc l'installer via pip :
pip install -r requirements.txt
Pour éviter la validation accidentelle de mots de passe, des hooks de pré-commit sont recommandés pour empêcher le traitement des commits git avant que les informations sensibles n'arrivent dans le référentiel. Nous avons utilisé les hooks de pré-commit de https://github.com/ukgovdatascience/govcookiecutter
L'installation de Requirements.txt installera l'outil de pré-commit, qui doit maintenant être connecté à git :
pre-commit install
... qui extraira ensuite la configuration de .pre-commit-config.yaml .
REMARQUE : le test de pré-validation check-added-large-files a sa taille maximale en Ko dans .pre-commit-config.yaml qui est temporairement augmentée à 60 Mo lors de l'ajout du fichier de modèle RCNN /tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb . La limite est ensuite rétablie à 5 Mo en tant que limite supérieure "normale" raisonnable.
Il est recommandé d'effectuer une analyse de tous les fichiers avant de continuer, juste pour s'assurer que rien n'est déjà présent par erreur :
pre-commit run --all-files
Cela signalera tous les problèmes existants - utile car le hook n'est autrement exécuté que sur les fichiers modifiés.
Le projet est conçu pour être utilisé principalement via l'infrastructure cloud, mais il existe des scripts utilitaires pour l'accès local et les mises à jour des séries chronologiques dans le cloud. Ces scripts se trouvent dans le dossier scripts/gcloud , chaque script étant désormais décrit dans les sections suivantes distinctes. De plus amples informations peuvent être trouvées dans scripts/gcloud/README.md , et leur utilisation par une machine virtuelle facultative est décrite dans cloud/README.md .
L'utilisation hors cloud est prise en charge par les scripts du dossier scripts/localhost , et les détails sur l'utilisation du système chrono_lens sur une machine autonome sont décrits dans README-localhost.md . De plus amples informations sur l'utilisation des scripts peuvent être trouvées dans scripts/localhost/README.md .
Notez que les scripts utilisent le code du dossier chrono_lens .
| Version | Date | Remarques |
|---|---|---|
| 1.0.0 | 2021-06-08 | Première version du référentiel public |
| 1.0.1 | 2021-09-21 | Correction d'un bug pour les images isolées, modification de la version Tensorflow |
| 1.1.0 | ? | Ajout d'une prise en charge limitée pour une seule machine autonome |
Les domaines de travaux futurs potentiels sont présentés ici ; ces changements ne font peut-être pas l'objet d'une enquête, mais sont là pour sensibiliser les gens aux améliorations potentielles que nous avons envisagées.
À l'heure actuelle, des scripts shell bash sont utilisés pour créer l'infrastructure GCP ; une amélioration serait d'utiliser IaC, comme Terraform. Cela simplifie la modification (par exemple) des configurations de Cloud Function sans avoir à supprimer manuellement le Cloud Build Trigger et à le recréer lorsque l'environnement d'exécution ou les limites de mémoire sont modifiés.
La conception actuelle découle de son cas d'utilisation initial consistant à acquérir des images avant la finalisation des modèles, c'est pourquoi toutes les images disponibles sont téléchargées plutôt que uniquement celles qui sont analysées. Pour réduire les coûts d'ingestion, le code d'ingestion doit être recoupé avec les fichiers JSON d'analyse et télécharger uniquement ces fichiers ; une alerte doit être déclenchée lorsqu’une de ces sources n’est plus disponible ou si de nouvelles sources deviennent disponibles.
Le remplissage nocturne des images pour NETravelData semble actualiser environ 40 % des images NETravelData ; l'avantage d'une actualisation régulière est diminué si les chiffres ne sont requis que quotidiennement, et par conséquent la fonction Cloud distribute_ne_travel_data peut être supprimée.
http async vers PubSub La conception initiale utilise des scripts manuels lors du test de nouveaux modèles, à savoir batch_process_images.py . Celui-ci rapporte le succès (ou non) et le nombre d'images traitées. Pour ce faire, une fonction Cloud fonctionne bien car elle renvoie un résultat. Cependant, une architecture plus efficace consisterait à utiliser une file d'attente PubSub en interne avec les fonctions distribute_json_sources et processed_scheduled ajoutant du travail aux files d'attente PubSub qui sont consommées par une seule fonction de travail, plutôt que la hiérarchie actuelle des appels asynchrones (en utilisant deux fonctions supplémentaires pour évoluer ).
L'Observatoire urbain de l'Université de Newcastle a fourni le Faster-RCNNN pré-entraîné que nous utilisons (une copie locale est stockée dans /tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb ).
Les données sont fournies par le service de données ouvertes de gestion et de contrôle du trafic urbain du Nord-Est, sous licence Open Government License 3.0. Les images sont attribuées à Tyne and Wear Urban Traffic Management and Control.
Les données du Nord-Est sont ensuite traitées et hébergées par l'Observatoire urbain de l'Université de Newcastle, dont nous remercions vivement le soutien et les conseils.
Les données sont fournies par TfL et sont alimentées par TfL Open Data. Les données sont sous licence sous la version 2.0 de la licence Open Government. Les données TfL contiennent des données OS © Crown copyright et droits de base de données 2016 et Geomni UK Map data © et droits de base de données (2019).
Diverses bibliothèques tierces sont utilisées dans ce projet ; ceux-ci sont répertoriés sur la page des dépendances, dont nous reconnaissons avec gratitude les contributions.


