whisperX
3.1.1
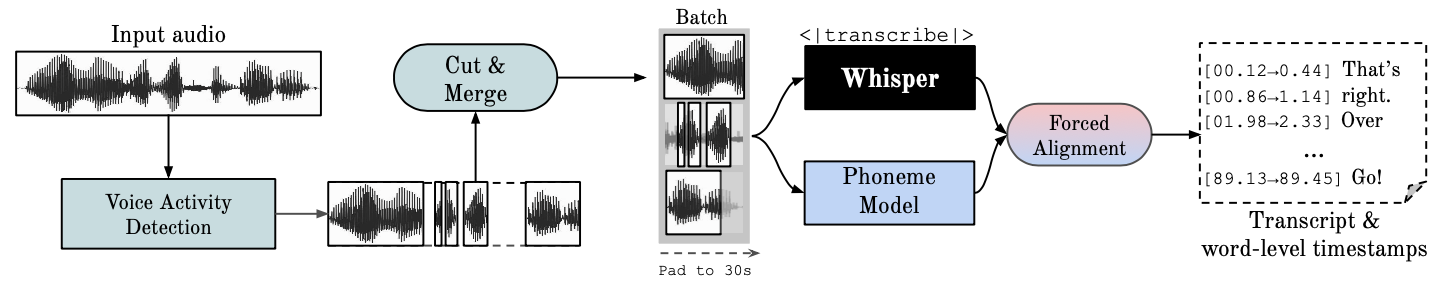
Ce référentiel fournit une reconnaissance vocale automatique rapide (70x en temps réel avec large-v2) avec des horodatages au niveau des mots et une diarisation des locuteurs.
Whisper est un modèle ASR développé par OpenAI, formé sur un vaste ensemble de données audio diverses. Bien qu'il produise des transcriptions très précises, les horodatages correspondants se situent au niveau de l'énoncé, et non par mot, et peuvent être inexacts de plusieurs secondes. Le murmure d'OpenAI ne prend pas en charge nativement le traitement par lots.
ASR basé sur les phonèmes Une suite de modèles affinés pour reconnaître la plus petite unité vocale distinguant un mot d'un autre, par exemple l'élément p dans "tap". Un exemple de modèle populaire est wav2vec2.0.
L'alignement forcé fait référence au processus par lequel les transcriptions orthographiques sont alignées sur les enregistrements audio pour générer automatiquement une segmentation au niveau du téléphone.
La détection d'activité vocale (VAD) est la détection de la présence ou de l'absence de parole humaine.
La diarisation des locuteurs est le processus de partitionnement d'un flux audio contenant de la parole humaine en segments homogènes en fonction de l'identité de chaque locuteur.
L'exécution GPU nécessite que les bibliothèques NVIDIA cuBLAS 11.x et cuDNN 8.x soient installées sur le système. Veuillez vous référer à la documentation CTranslate2.
conda create --name whisperx python=3.10
conda activate whisperx
conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
Voir d'autres méthodes ici.
pip install git+https://github.com/m-bain/whisperx.git
S'il est déjà installé, mettez à jour le package avec la validation la plus récente
pip install git+https://github.com/m-bain/whisperx.git --upgrade
Si vous souhaitez modifier ce package, clonez et installez en mode modifiable :
$ git clone https://github.com/m-bain/whisperX.git
$ cd whisperX
$ pip install -e .
Vous devrez peut-être également installer ffmpeg, rust, etc. Suivez les instructions d'openAI ici https://github.com/openai/whisper#setup.
Pour activer la diarisation du haut-parleur , incluez votre jeton d'accès Hugging Face (lecture) que vous pouvez générer à partir d'ici après l'argument --hf_token et acceptez l'accord d'utilisation pour les modèles suivants : Segmentation et Speaker-Diarisation-3.1 (si vous choisissez d'utiliser le haut-parleur -Diarisation 2.x, suivez plutôt les exigences ici.)
Note
Depuis le 11 octobre 2023, il existe un problème connu concernant la lenteur des performances avec pyannote/Speaker-Diarisation-3.0 dans WhisperX. Cela est dû à des conflits de dépendances entre fast-whisper et pyannote-audio 3.0.0. Veuillez consulter ce problème pour plus de détails et des solutions de contournement potentielles.
Exécutez Whisper sur un exemple de segment (en utilisant les paramètres par défaut, Whisper Small), ajoutez --highlight_words True pour visualiser la synchronisation des mots dans le fichier .srt.
whisperx examples/sample01.wav
Résultat en utilisant WhisperX avec alignement forcé sur wav2vec2.0 large :
Comparez cela au murmure original, où de nombreuses transcriptions sont désynchronisées :
Pour une précision d'horodatage accrue, au prix d'une mémoire GPU plus élevée, utilisez des modèles plus grands (un modèle d'alignement plus grand ne s'est pas révélé très utile, voir article), par exemple
whisperx examples/sample01.wav --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --batch_size 4
Pour étiqueter la transcription avec les identifiants des locuteurs (définir le nombre de locuteurs s'il est connu, par exemple --min_speakers 2 --max_speakers 2 ) :
whisperx examples/sample01.wav --model large-v2 --diarize --highlight_words True
Pour exécuter sur CPU au lieu de GPU (et pour exécuter sur Mac OS X) :
whisperx examples/sample01.wav --compute_type int8
Le modèle d'alignement du phonème ASR est spécifique à la langue . Pour les langues testées, ces modèles sont automatiquement sélectionnés à partir des pipelines torchaudio ou huggingface. Transmettez simplement le code --language et utilisez le murmure --model large .
Modèles actuellement fournis par défaut pour {en, fr, de, es, it, ja, zh, nl, uk, pt} . Si la langue détectée ne figure pas dans cette liste, vous devez rechercher un modèle ASR basé sur le phonème à partir du hub de modèles Huggingface et le tester sur vos données.
whisperx --model large-v2 --language de examples/sample_de_01.wav
Voir plus d’exemples dans d’autres langues ici.
import whisperx
import gc
device = "cuda"
audio_file = "audio.mp3"
batch_size = 16 # reduce if low on GPU mem
compute_type = "float16" # change to "int8" if low on GPU mem (may reduce accuracy)
# 1. Transcribe with original whisper (batched)
model = whisperx . load_model ( "large-v2" , device , compute_type = compute_type )
# save model to local path (optional)
# model_dir = "/path/"
# model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx . load_audio ( audio_file )
result = model . transcribe ( audio , batch_size = batch_size )
print ( result [ "segments" ]) # before alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model
# 2. Align whisper output
model_a , metadata = whisperx . load_align_model ( language_code = result [ "language" ], device = device )
result = whisperx . align ( result [ "segments" ], model_a , metadata , audio , device , return_char_alignments = False )
print ( result [ "segments" ]) # after alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model_a
# 3. Assign speaker labels
diarize_model = whisperx . DiarizationPipeline ( use_auth_token = YOUR_HF_TOKEN , device = device )
# add min/max number of speakers if known
diarize_segments = diarize_model ( audio )
# diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers)
result = whisperx . assign_word_speakers ( diarize_segments , result )
print ( diarize_segments )
print ( result [ "segments" ]) # segments are now assigned speaker IDs Si vous n'avez pas accès à vos propres GPU, utilisez les liens ci-dessus pour essayer WhisperX.
Pour des détails spécifiques sur le lot et l’alignement, l’effet du VAD, ainsi que le modèle d’alignement choisi, consultez le papier de préimpression.
Pour réduire les besoins en mémoire GPU, essayez l'une des solutions suivantes (2. et 3. peuvent affecter la qualité) :
--batch_size 4--model base--compute_type int8Différences de transcription par rapport au murmure d'openai :
--without_timestamps True , cela garantit 1 passage direct par échantillon dans le lot. Cependant, cela peut entraîner des divergences avec la sortie chuchotée par défaut.--condition_on_prev_text est défini sur False par défaut (réduit les hallucinations) Si vous êtes multilingue, une manière importante de contribuer à ce projet est de trouver des modèles de phonèmes sur Huggingface (ou de former les vôtres) et de les tester sur la parole dans la langue cible. Si les résultats semblent bons, envoyez une pull request et quelques exemples montrant son succès.
La recherche de bogues et les demandes d'extraction sont également très appréciées pour poursuivre ce projet, car il s'écarte déjà du champ de recherche initial.
Initialisation multilingue
Sélection automatique du modèle d'alignement basée sur la détection de la langue
Utilisation de Python
Intégration de la diarisation des locuteurs
Modèle flush, pour de faibles ressources mémoire GPU
Backend plus rapide
Ajoutez max-line etc. voir (chuchotement d'openai utils.py)
Segments au niveau de la phrase (boîte à outils nltk)
Améliorer la logique d’alignement
mettre à jour les exemples avec la diarisation et la mise en évidence des mots
Sortie du sous-titre .ass <- ramener ceci (supprimé dans la v3)
Ajouter du code d'analyse comparative (TEDLIUM pour spd/WER et segmentation de mots)
Autoriser silero-vad comme option VAD alternative
Améliorer la diarisation (niveau des mots). Plus difficile qu'on ne le pensait au départ...
Contactez [email protected] pour toute question.
Ce travail, ainsi que mon doctorat, sont soutenus par le VGG (Visual Geometry Group) et l'Université d'Oxford.
Bien sûr, cela s’appuie sur le murmure d’openAI. Emprunte un code d'alignement important au didacticiel PyTorch sur l'alignement forcé et utilise le merveilleux pyannote VAD / Diarization https://github.com/pyannote/pyannote-audio
Modèles VAD et diarisation précieux de [pyannote audio][https://github.com/pyannote/pyannote-audio]
Excellent backend de Fast-Whisper et CTranslate2
Ceux qui ont soutenu financièrement ce travail
Enfin, merci aux contributeurs OS de ce projet, qui ont permis de le maintenir et d'identifier les bugs.
@article { bain2022whisperx ,
title = { WhisperX: Time-Accurate Speech Transcription of Long-Form Audio } ,
author = { Bain, Max and Huh, Jaesung and Han, Tengda and Zisserman, Andrew } ,
journal = { INTERSPEECH 2023 } ,
year = { 2023 }
}

