./imagesDockerfile pour inclure vos binairesf()TUPLE_CODECS
docker build -t image_compression_comparison .
docker run -it -v $(pwd):/image_compression_comparison image_compression_comparison
python3 script_compress_parallel.py
Des encodages ciblant certaines valeurs de métriques sont effectués et les résultats sont stockés dans les fichiers de base de données respectifs, par exemple :
main(metric='ssim', target_arr=[0.92, 0.95, 0.97, 0.99], target_tol=0.005, db_file_name='encoding_results_ssim.db')main(metric='vmaf', target_arr=[75, 80, 85, 90, 95], target_tol=0.5, db_file_name='encoding_results_vmaf.db')
compression_results_[PID]_[TIMESTAMP].txtcompression_results_worker_[PID]_[TIMESTAMP].txt Dans les fichiers de base de données sqlite3, par exemple encoding_results_vmaf.db et encoding_results_ssim.db .
Les taux BD en pourcentage peuvent être calculés à l'aide d'un script appelé compute_BD_rates.py . Le script prend un argument :
python3 compute_BD_rates.py [db file name]
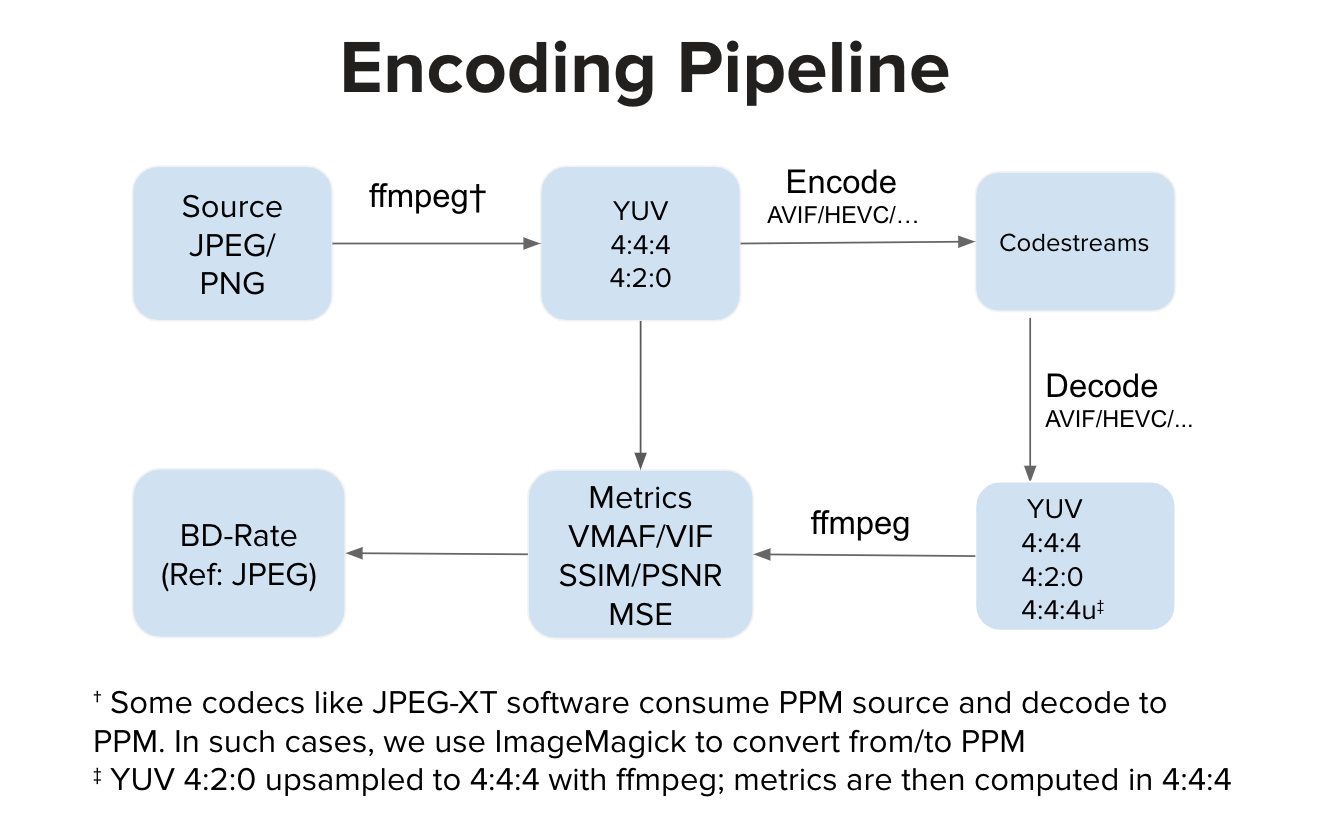
et imprime les valeurs pour BD Rate VMAF , BD Rate SSIM , BDRate MS_SSIM , BDRate VIF , BDRate PSNR_Y et BDRate PSNR_AVG pour chaque image source ainsi que la moyenne sur l'ensemble de données source. Les taux BD sont imprimés pour le sous-échantillonnage 420 ainsi que pour le sous-échantillonnage 444 . PSNR_AVG est dérivé de MSE_AVG qui est pondéré MSE sur toutes les composantes de couleur, pondéré en fonction du nombre d'échantillons dans les composantes de couleur respectives.
Un script appelé analyze_encoding_results.py est également inclus.
Le script prend deux arguments :
python3 analyze_encoding_results.py [metric_name like vmaf OR ssim] [db file name]
Il convient de noter que le taux BD fournit un nombre agrégé sur toute la gamme des qualités cibles. En regardant uniquement le taux BD, certaines informations peuvent passer inaperçues, par exemple, comment l'efficacité de la compression se compare-t-elle, par exemple spécifiquement, au point de fonctionnement VMAF=95 ?
Un autre exemple est, disons que le taux BD est nul. Il est tout à fait possible que les courbes débit-qualité se croisent et qu'un codec soit nettement meilleur que l'autre, par exemple au point de fonctionnement VMAF = 95, et pire dans la région du débit binaire inférieur.
Idéalement, lorsque les ressources d'image sont codées pour être utilisées dans l'interface utilisateur, on souhaiterait avoir une qualité de fonctionnement bien définie telle que VMAF=95. Et sans doute, les résultats de la région de moindre qualité pourraient être sans importance. Les informations décrites en (b) augmentent ainsi l'information « globale » fournie par le taux de BD.
Le nombre de processus de travail simultanés peut être spécifié dans
pool = multiprocessing.Pool(processes=4, initializer=initialize_worker)
Compte tenu du système sur lequel vous utilisez, une concurrence raisonnable peut être limitée par le nombre de cœurs de processeur ou la quantité de RAM disponible par rapport à la mémoire consommée par le processus d'encodeur le plus exigeant dans l'ensemble des codecs testés. Par exemple, si une instance encoder_A consomme généralement 5 Go de RAM et que vous disposez de 32 Go de RAM au total, la concurrence raisonnable peut être limitée à 6 (32/5), même si vous disposez de 24 cœurs de processeur (ou de plus de 6).
Idéalement, une implémentation d'encodeur consomme une entrée YUV et génère un flux codé. Idéalement, une implémentation de décodeur consomme le flux codé et décode en sortie YUV. Nous calculons ensuite les métriques dans l'espace YUV. Cependant, il existe des implémentations telles que le logiciel JPEG-XT qui consomment une entrée PPM et produisent une sortie PPM. Dans de tels cas, il peut y avoir une conversion PPM source en YUV ainsi qu'une conversion PPM décodée en YUV avant le calcul de la qualité dans l'espace YUV. Les étapes de conversion supplémentaires, par rapport au pipeline normal, peuvent introduire une légère distorsion, mais dans nos expériences, ces étapes n'entraînent aucune altération notable du score VMAF.