LARS
v2.0-beta8:

LARS est une application qui vous permet d'exécuter des LLM (Large Language Models) localement sur votre appareil, de télécharger vos propres documents et d'engager des conversations dans lesquelles le LLM fonde ses réponses sur votre contenu téléchargé. Cette mise à la terre contribue à accroître la précision et à réduire le problème courant des inexactitudes ou des « hallucinations » générées par l’IA. Cette technique est communément connue sous le nom de « Retrieval Augmented Generation », ou RAG.
Il existe de nombreuses applications de bureau pour exécuter des LLM localement, et LARS vise à être l'application LLM open source ultime centrée sur RAG. À cette fin, LARS pousse le concept de RAG beaucoup plus loin en ajoutant des citations détaillées à chaque réponse, en vous fournissant des noms de documents spécifiques, des numéros de page, des surlignages de texte et des images pertinentes pour votre question, et même en présentant un lecteur de documents directement dans le fenêtre de réponse. Bien que toutes les citations ne soient pas toujours présentes pour chaque réponse, l'idée est d'avoir au moins une combinaison de citations affichées pour chaque réponse RAG, ce qui s'avère généralement être le cas.
Vidéo de démonstration des fonctionnalités LARS
Python v3.10.x ou supérieur : https://www.python.org/downloads/
PyTorch :
Si vous envisagez d'utiliser votre GPU pour exécuter des LLM, assurez-vous d'installer les pilotes GPU et les kits d'outils CUDA/ROCm en fonction de votre configuration, puis procédez ensuite à la configuration de PyTorch ci-dessous.
Téléchargez et installez la version PyTorch appropriée à votre système : https://pytorch.org/get-started/locally/
Clonez le dépôt :
git clone https://github.com/abgulati/LARS
cd LARS
GitHub Settings -> Developer settings (located on the bottom left!) -> Personal access tokensInstallez les dépendances Python :
Windows via PIP :
pip install -r .requirements.txt
Linux via PIP :
pip3 install -r ./requirements.txt
Remarque sur Azure : Certaines bibliothèques Azure requises ne sont PAS disponibles sur la plateforme MacOS ! Un fichier d'exigences distinct est donc inclus pour MacOS, excluant ces bibliothèques :
Mac OS :
pip3 install -r ./requirements_mac.txt
Retour à la table des matières
Après l'installation, exécutez LARS en utilisant :
cd web_app
python app.py # Use 'python3' on Linux/macOS
Accédez à http://localhost:5000/ dans votre navigateur
Tous les répertoires d'applications requis par LARS seront désormais créés sur le disque
Le serveur HF-Waitress démarrera automatiquement et téléchargera un LLM (Microsoft Phi-3-Mini-Instruct-44) lors de la première exécution, ce qui peut prendre un certain temps en fonction de la vitesse de votre connexion Internet.
Lors de la première requête, un modèle d'intégration (all-mpnet-base-v2) sera téléchargé depuis HuggingFace Hub, ce qui devrait prendre un certain temps.
Retour à la table des matières
Sous Windows :
Téléchargez Microsoft Visual Studio Build Tools 2022 depuis le site officiel - "Outils pour Visual Studio"
REMARQUE : lors de l'installation de ce qui précède, assurez-vous de sélectionner les composants suivants :
Desktop development with C++
# Then from the "Optional" category on the right, make sure to select the following:
MSVC C++ x64/x86 build tools
C++ CMake tools for Windows
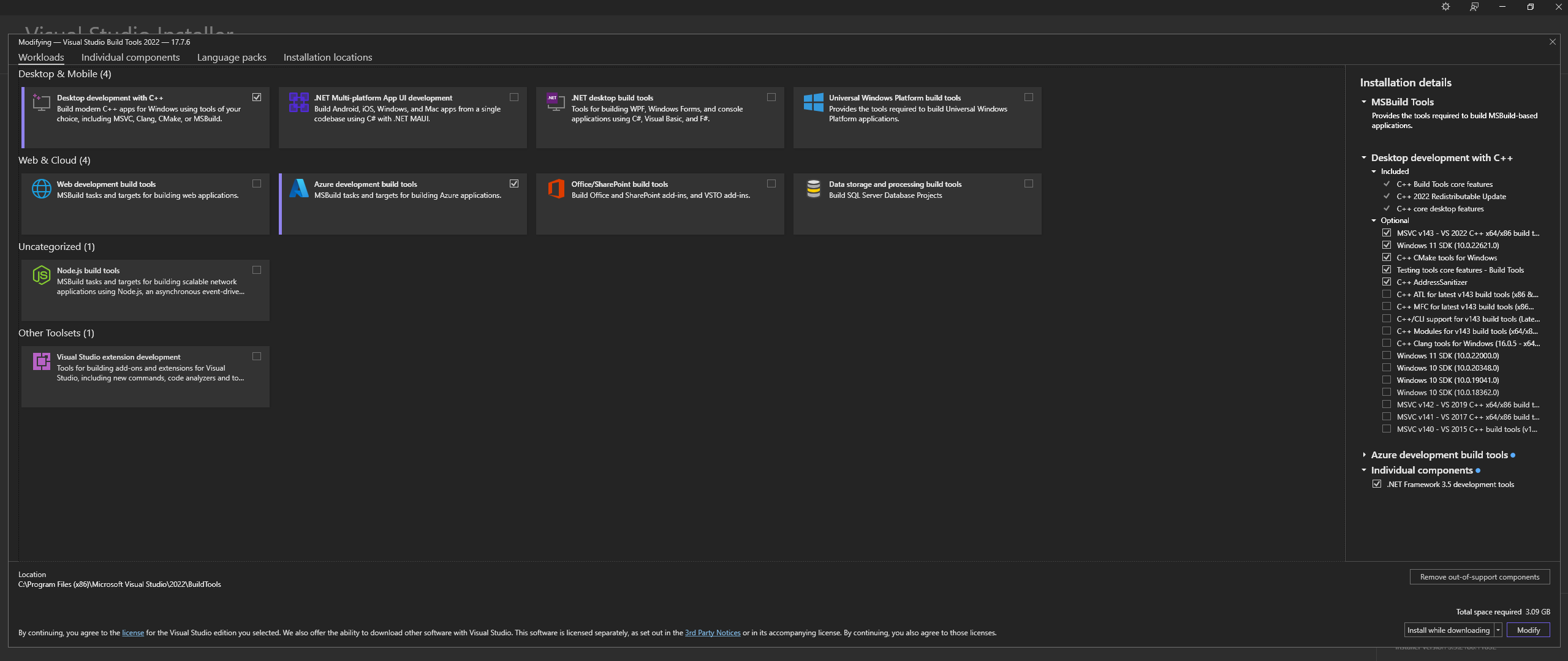
Desktop development with C++ et les options MSVC and C++ CMake sont sélectionnés comme indiqué ci-dessus.Sous Linux (basé sur Ubuntu et Debian), installez les packages suivants :
sudo apt-get update
sudo apt-get install -y software-properties-common build-essential libffi-dev libssl-dev cmake
Télécharger depuis le dépôt officiel :
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
Installez CMAKE sur Windows depuis le site officiel
C:Program FilesCMakebinConstruisez lama.cpp avec CMAKE :
Remarque : Pour une compilation plus rapide, ajoutez l'argument -j pour exécuter plusieurs tâches en parallèle. Par exemple, cmake --build build --config Release -j 8 exécutera 8 tâches en parallèle.
Construire avec CUDA :
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="52;61;70;75;80;86"
cmake --build build --config Release
cmake -B build
cmake --build build --config Release
Si vous rencontrez des problèmes lorsque vous tentez d'exécuter CMake -B build , consultez les étapes détaillées de dépannage de l'installation de CMake ci-dessous.
Ajouter au CHEMIN :
path_to_cloned_repollama.cppbuildbinRelease
Vérifiez l'installation via le terminal :
llama-server
Installer les pilotes GPU Nvidia
Installez Nvidia CUDA Toolkit - LARS construit et testé avec v12.2 et v12.4
Vérifiez l'installation via le terminal :
nvcc -V
nvidia-smi
Correctif CMAKE-CUDA (très important !) :
Copiez les quatre fichiers du répertoire suivant :
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.2extrasvisual_studio_integrationMSBuildExtensions
et collez-les dans le répertoire suivant :
C:Program Files (x86)Microsoft Visual Studio2022BuildToolsMSBuildMicrosoftVCv170BuildCustomizations
Il s'agit d'une dépendance facultative mais fortement recommandée. Seuls les fichiers PDF sont pris en charge si cette configuration n'est pas terminée.
Fenêtres :
Télécharger depuis le site officiel
Ajoutez à PATH, soit via :
Paramètres système avancés -> Variables d'environnement -> Variables système -> Variable EDIT PATH -> Ajoutez ce qui suit (modifiez en fonction de votre emplacement d'installation) :
C:Program FilesLibreOfficeprogram
Ou via PowerShell :
Set PATH=%PATH%;C:Program FilesLibreOfficeprogram
Linux basé sur Ubuntu et Debian - Téléchargez depuis le site officiel ou installez via un terminal :
sudo apt-get update
sudo apt-get install -y libreoffice
Fedora et autres distributions basées sur RPM - Téléchargez depuis le site officiel ou installez via un terminal :
sudo dnf update
sudo dnf install libreoffice
MacOS - Téléchargez depuis le site officiel ou installez via Homebrew :
brew install --cask libreoffice
Vérifier l'installation :
Sous Windows et MacOS : exécutez l'application LibreOffice
Sous Linux via le terminal :
libreoffice --version
LARS utilise la bibliothèque pdf2image Python pour convertir chaque page d'un document en image comme requis pour l'OCR. Cette bibliothèque est essentiellement un wrapper autour de l'utilitaire Poppler qui gère le processus de conversion.
Fenêtres :
Télécharger depuis le dépôt officiel
Ajoutez à PATH, soit via :
Paramètres système avancés -> Variables d'environnement -> Variables système -> Variable EDIT PATH -> Ajoutez ce qui suit (modifiez en fonction de votre emplacement d'installation) :
path_to_installationpoppler_versionLibrarybin
Ou via PowerShell :
Set PATH=%PATH%;path_to_installationpoppler_versionLibrarybin
Linux :
sudo apt-get update
sudo apt-get install -y poppler-utils wget
Il s'agit d'une dépendance facultative - Tesseract-OCR n'est pas activement utilisé dans LARS mais les méthodes pour l'utiliser sont présentes dans le code source
Fenêtres :
Téléchargez Tesseract-OCR pour Windows via UB-Mannheim
Ajoutez à PATH, soit via :
Paramètres système avancés -> Variables d'environnement -> Variables système -> Variable EDIT PATH -> Ajoutez ce qui suit (modifiez en fonction de votre emplacement d'installation) :
C:Program FilesTesseract-OCR
Ou via PowerShell :
Set PATH=%PATH%;C:Program FilesTesseract-OCR
Retour à la table des matières
LARS a été construit et testé avec Python v3.11.x
Installez Python v3.11.x sous Windows :
Téléchargez la v3.11.9 depuis le site officiel
Lors de l'installation, assurez-vous de cocher « Ajouter Python 3.11 à PATH » ou de l'ajouter manuellement plus tard, soit via :
Paramètres système avancés -> Variables d'environnement -> Variables système -> Variable EDIT PATH -> Ajoutez ce qui suit (modifiez en fonction de votre emplacement d'installation) :
C:Usersuser_nameAppDataLocalProgramsPythonPython311
Ou via PowerShell :
Set PATH=%PATH%;C:Usersuser_nameAppDataLocalProgramsPythonPython311
Installez Python v3.11.x sur Linux (basé sur Ubuntu et Debian) :
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt-get update
sudo apt-get install -y python3.11 python3.11-venv python3.11-dev
sudo python3.11 -m ensurepip
Vérifiez l'installation via le terminal :
python3 --version
Si vous rencontrez des erreurs avec pip install , essayez ce qui suit :
Supprimez les numéros de version :
==version.number , par exemple :urllib3==2.0.4urllib3Créez et utilisez un environnement virtuel Python :
Il est conseillé d'utiliser un environnement virtuel pour éviter les conflits avec d'autres projets Python
Fenêtres :
Créez un environnement virtuel Python (venv) :
python -m venv larsenv
Activez, puis utilisez, le venv :
.larsenvScriptsactivate
Désactivez venv une fois terminé :
deactivate
Linux et MacOS :
Créez un environnement virtuel Python (venv) :
python3 -m venv larsenv
Activez, puis utilisez, le venv :
source larsenv/bin/activate
Désactivez venv une fois terminé :
deactivate
Si les problèmes persistent, envisagez d'ouvrir un ticket sur le référentiel LARS GitHub pour obtenir de l'aide.
CMake nmake failed lorsque vous tentez de créer llama.cpp, comme ci-dessous : 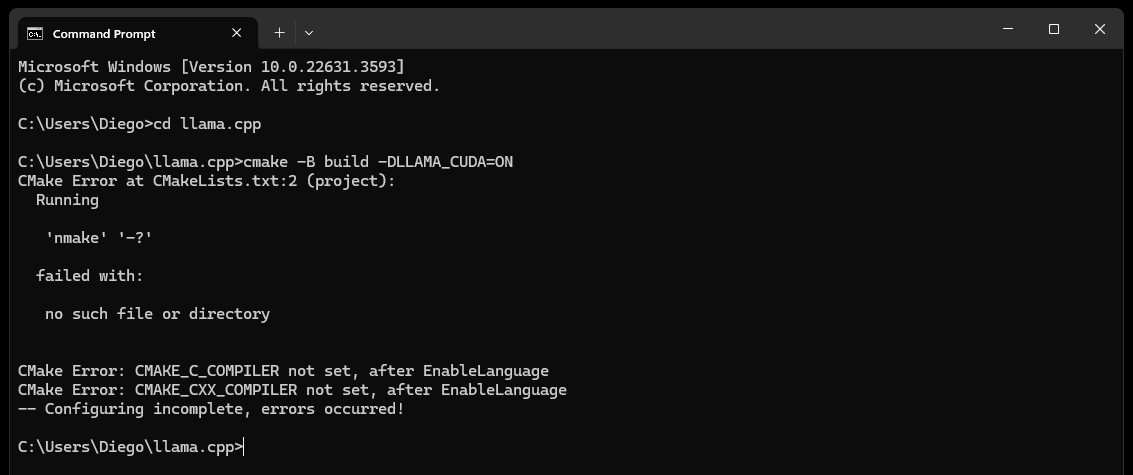
Cela indique généralement un problème avec vos outils de génération Microsoft Visual Studio, car CMake ne parvient pas à trouver l'outil nmake, qui fait partie des outils de génération Microsoft Visual Studio. Essayez les étapes ci-dessous pour résoudre le problème :
Assurez-vous que Visual Studio Build Tools est installé :
Assurez-vous que les outils de génération de Visual Studio sont installés, y compris nmake. Vous pouvez installer ces outils via Visual Studio Installer en sélectionnant le Desktop development with C++ et les options MSVC and C++ CMake
Vérifiez l'étape 0 de la section Dépendances, en particulier la capture d'écran qu'elle contient
Vérifiez les variables d'environnement :
C:Program Files (x86)Microsoft Visual Studio2019CommunityVCAuxiliaryBuild
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7IDE
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7Tools
Utilisez l'invite de commande du développeur :
Ouvrez une "Invite de commandes de développeur pour Visual Studio" qui configure les variables d'environnement nécessaires pour vous
Vous pouvez trouver cette invite dans le menu Démarrer sous Visual Studio
Définir le générateur CMake :
cmake -G "NMake Makefiles" -B build -DLLAMA_CUDA=ON
Si les problèmes persistent, envisagez d'ouvrir un ticket sur le référentiel LARS GitHub pour obtenir de l'aide.
Finalement (après environ 60 secondes), vous verrez une alerte sur la page indiquant une erreur :
Failed to start llama.cpp local-server
Cela indique que la première exécution est terminée, que tous les répertoires d'applications ont été créés, mais qu'aucun LLM n'est présent dans le répertoire models et peut maintenant y être déplacé.
Déplacez vos LLM (n'importe quel format de fichier pris en charge par lama.cpp, de préférence GGUF) vers le répertoire models nouvellement créé, situé par défaut aux emplacements suivants :
C:/web_app_storage/models/app/storage/models/app/models Une fois que vous avez placé vos LLM dans le répertoire models approprié ci-dessus, actualisez http://localhost:5000/
Vous recevrez à nouveau une alerte d'erreur indiquant Failed to start llama.cpp local-server après environ 60 secondes.
En effet, votre LLM doit maintenant être sélectionné dans le menu Settings LARS.
Acceptez l'alerte et cliquez sur l'icône d'engrenage Settings en haut à droite
Dans l'onglet LLM Selection , sélectionnez votre LLM et le format d'invite approprié dans les listes déroulantes appropriées.
Modifiez les paramètres avancés pour définir correctement les options GPU , la Context-Length et éventuellement la limite de génération de jetons ( Maximum tokens to predict ) pour votre LLM sélectionné.
Appuyez sur Save et si une actualisation automatique n'est pas déclenchée, actualisez manuellement la page
Si toutes les étapes ont été exécutées correctement, la première configuration est maintenant terminée et LARS est prêt à être utilisé.
LARS mémorisera également vos paramètres LLM pour une utilisation ultérieure
Retour à la table des matières
Formats de documents pris en charge :
Si LibreOffice est installé et ajouté à PATH comme détaillé à l'étape 4 de la section Dépendances, les formats suivants sont pris en charge :
Si LibreOffice n'est pas configuré, seuls les fichiers PDF sont pris en charge
Options OCR pour l'extraction de texte :
LARS propose trois méthodes pour extraire du texte à partir de documents, s'adaptant à différents types et qualités de documents :
Extraction de texte local : utilise PyPDF2 pour une extraction de texte efficace à partir de PDF non numérisés. Idéal pour un traitement rapide lorsqu’une grande précision n’est pas critique ou qu’un traitement entièrement local est une nécessité.
Azure ComputerVision OCR – Améliore la précision de l’extraction de texte et prend en charge les documents numérisés. Utile pour gérer les mises en page de documents standard. Offre un niveau gratuit adapté aux essais initiaux et à une utilisation à faible volume, plafonné à 5 000 transactions/mois à 20 transactions/minute.
Azure AI Document Intelligence OCR – Idéal pour les documents avec des structures complexes comme les tableaux. Un analyseur personnalisé dans LARS optimise le processus d'extraction.
REMARQUES :
Les options Azure OCR entraînent des coûts d'API dans la plupart des cas et ne sont pas fournies avec LARS.
Un niveau gratuit limité pour ComputerVision OCR est disponible comme lien ci-dessus. Ce service est globalement moins cher mais plus lent et peut ne pas fonctionner pour les mises en page de documents non standard (autres que A4, etc.).
Tenez compte des types de documents et de vos besoins en matière de précision lors de la sélection d'une option OCR.
LLM :
Seuls les LLM locaux sont actuellement pris en charge
Le menu Settings offre de nombreuses options permettant à l'utilisateur expérimenté de configurer et de modifier le LLM via l'onglet LLM Selection
Remarque si vous utilisez llama.cpp : Très important : sélectionnez le format de modèle d'invite approprié pour le LLM que vous exécutez.
Les LLM formés pour les formats de modèles d'invite suivants sont actuellement pris en charge via llama.cpp :
Ajustez les paramètres de configuration de base via Advanced Settings (déclenche le rechargement LLM et l'actualisation de la page) :
Ajustez les paramètres pour modifier le comportement de réponse à tout moment :
Modèles d'intégration et base de données vectorielles :
Quatre modèles d'intégration sont fournis dans LARS :
À l’exception des intégrations Azure-OpenAI, tous les autres modèles s’exécutent entièrement localement et gratuitement. Lors de la première exécution, ces modèles seront téléchargés depuis le HuggingFace Hub. Il s'agit d'un téléchargement unique et ils seront ensuite présents localement.
L'utilisateur peut basculer entre ces modèles d'intégration à tout moment via l'onglet VectorDB & Embedding Models dans le menu Settings .
Table chargée par les documents : dans le menu Settings , une table s'affiche pour le modèle d'intégration sélectionné affichant la liste des documents intégrés à la base de données vectorielles associée. Si un document est chargé plusieurs fois, il aura plusieurs entrées dans ce tableau, ce qui pourrait être utile pour déboguer d'éventuels problèmes.
Effacement de VectorDB : utilisez le bouton Reset et confirmez pour effacer la base de données vectorielles sélectionnée. Cela crée un nouveau vectorDB sur le disque pour le modèle d'intégration sélectionné. L'ancien vectorDB est toujours conservé et peut être rétabli en modifiant manuellement le fichier config.json.
Modifier l'invite système :
L'invite système sert d'instruction au LLM pour toute la conversation.
LARS offre à l'utilisateur la possibilité de modifier l'invite système via le menu Settings en sélectionnant l'option Custom dans la liste déroulante de l'onglet System Prompt .
Les modifications apportées à l'invite système démarreront une nouvelle discussion
Forcer l'activation/la désactivation de RAG :
Via le menu Settings , l'utilisateur peut forcer l'activation ou la désactivation de RAG (Retrieval Augmented Generation – l'utilisation du contenu de vos documents pour améliorer les réponses générées par LLM) chaque fois que nécessaire.
Ceci est souvent utile pour évaluer les réponses LLM dans les deux scénarios.
La désactivation forcée désactivera également les fonctionnalités d'attribution
Le paramètre par défaut, qui utilise le NLP pour déterminer quand RAG doit et ne doit pas être effectué, est l'option recommandée.
Ce paramètre peut être modifié à tout moment
Historique des discussions :
Utilisez le menu de l'historique des discussions en haut à gauche pour parcourir et reprendre les conversations précédentes
Très important : soyez conscient des incohérences entre les modèles d'invite lorsque vous reprenez des conversations précédentes ! Utilisez l'icône Information en haut à droite pour vous assurer que le LLM utilisé dans la conversation précédente et le LLM actuellement utilisé sont tous deux basés sur les mêmes formats de modèle d'invite !
Évaluation des utilisateurs :
Chaque réponse peut être notée sur une échelle de 5 points par l'utilisateur à tout moment
Les données de notation sont stockées dans la base de données chat-history.db SQLite3 située dans le répertoire de l'application :
C:/web_app_storage/app/storage/appLes données d'évaluation sont très précieuses pour l'évaluation et le perfectionnement de l'outil pour vos flux de travail.
À faire et à ne pas faire :
Retour à la table des matières
Si une discussion tourne mal ou si des réponses étranges sont générées, essayez simplement de démarrer une New Chat via le menu en haut à gauche.
Vous pouvez également démarrer une nouvelle discussion en actualisant simplement la page.
Si des problèmes sont rencontrés avec les citations ou les performances du RAG, essayez de réinitialiser le vectorDB comme décrit à l'étape 4 du guide de l'utilisateur général ci-dessus.
Si des problèmes d'application surviennent et ne sont pas résolus simplement en démarrant une nouvelle discussion ou en redémarrant LARS, essayez de supprimer le fichier config.json en suivant les étapes ci-dessous :
CTRL+Cconfig.json situé dans LARS/web_app (même répertoire que app.py )Pour tout problème grave de données et de citation qui n'est pas résolu même en réinitialisant VectorDB comme décrit à l'étape 4 du Guide de l'utilisateur général ci-dessus, effectuez les étapes suivantes :
CTRL+CC:/web_app_storage/app/storage/appSi les problèmes persistent, envisagez d'ouvrir un ticket sur le référentiel LARS GitHub pour obtenir de l'aide.
Retour à la table des matières
LARS a été adapté à un environnement de déploiement de conteneur Docker via deux images distinctes comme ci-dessous :
Les deux ont des exigences différentes, le premier étant un déploiement plus simple, mais souffrant de performances d'inférence beaucoup plus lentes en raison du processeur et de la mémoire DDR agissant comme des goulots d'étranglement.
Bien que cela ne soit pas explicitement requis, une certaine expérience des conteneurs Docker et une familiarité avec les concepts de conteneurisation et de virtualisation seront très utiles dans cette section !
En commençant par les étapes de configuration communes aux deux :
Installation de Docker
Votre processeur doit prendre en charge la virtualisation et doit être activé dans le BIOS/UEFI de votre système.
Téléchargez et installez Docker Desktop
Si vous êtes sous Windows, vous devrez peut-être installer le sous-système Windows pour Linux s'il n'est pas déjà présent. Pour ce faire, ouvrez PowerShell en tant qu'administrateur et exécutez ce qui suit :
wsl --install
Assurez-vous que Docker Desktop est opérationnel, puis ouvrez une invite de commande/un terminal et exécutez la commande suivante pour vous assurer que Docker est correctement installé et opérationnel :
docker ps
Créez un volume de stockage Docker, qui sera attaché aux conteneurs LARS au moment de l'exécution :
La création d'un volume de stockage à utiliser avec le conteneur LARS est très avantageuse car elle vous permettra de mettre à niveau le conteneur LARS vers une version plus récente ou de basculer entre les variantes de conteneur CPU et GPU tout en conservant tous vos paramètres, votre historique de discussion et vos bases de données vectorielles de manière transparente. .
Exécutez la commande suivante dans une invite de commande/un terminal :
docker volume create lars_storage_volue
Ce volume sera attaché au conteneur LARS ultérieurement au moment de l'exécution. Pour l'instant, passez à la création de l'image LARS dans les étapes ci-dessous.
Dans une invite de commande/un terminal, exécutez les commandes suivantes :
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized
docker build -t lars-no-gpu .
# Once the build is complete, run the container:
docker run -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-no-gpu
Une fois terminé, accédez à http://localhost:5000/ dans votre navigateur et suivez le reste des étapes de première exécution et du guide de l'utilisateur.
Les sections de dépannage s'appliquent également à Container-LARS.
Conditions requises (en plus de Docker) :
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Pour Linux, vous êtes tous configurés avec ce qui précède, alors sautez l'étape suivante et passez directement aux étapes de construction et d'exécution ci-dessous.
Si vous êtes sous Windows et si c'est la première fois que vous exécutez un conteneur GPU Nvidia sur Docker, attachez-vous car cela va être tout un voyage (boisson préférée ou trois fortement recommandées !)
Au risque d'une redondance extrême, avant de continuer, assurez-vous que les dépendances suivantes sont présentes :
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Docker Desktop
Windows Subsystem for Linux (WSL)
Reportez-vous à la section Dépendances Nvidia CUDA et à la section Configuration de Docker ci-dessus en cas de doute.
Si les éléments ci-dessus sont présents et configurés, vous pouvez continuer
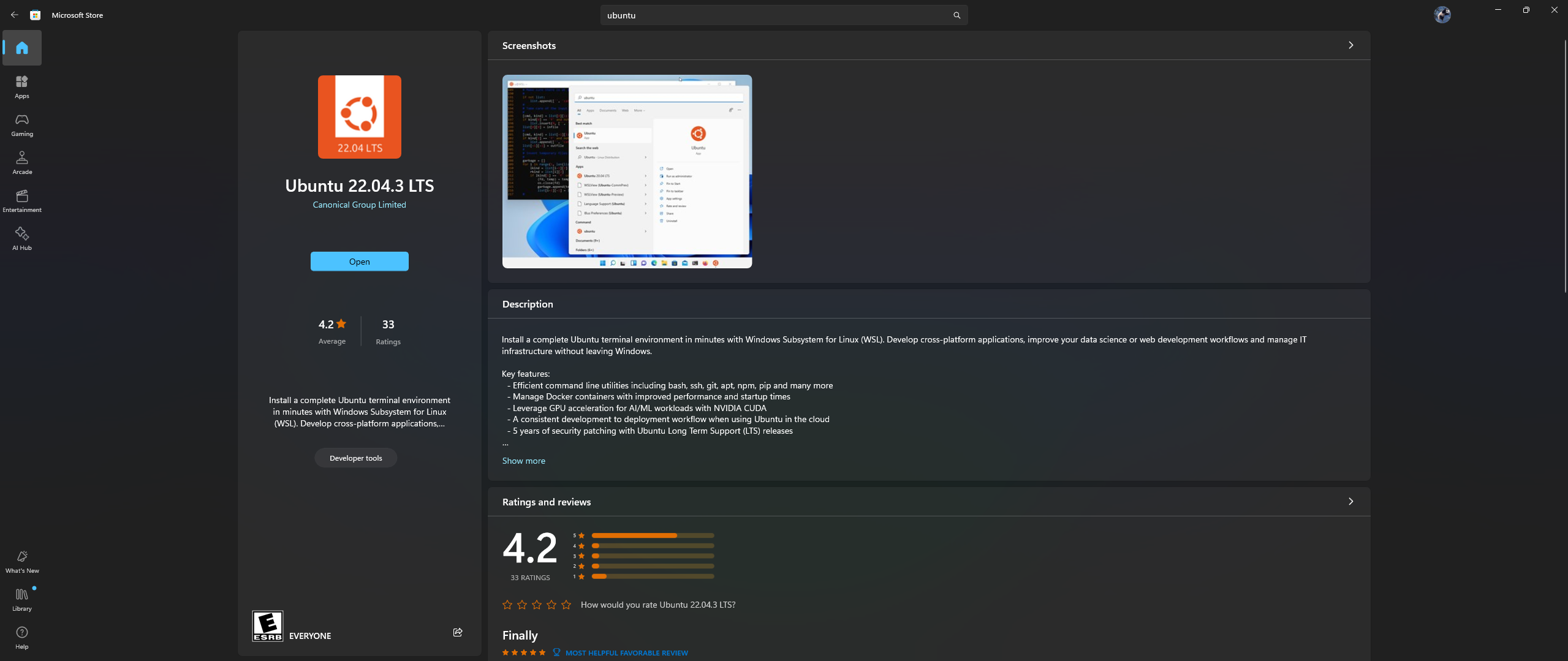
Ouvrez l'application Microsoft Store sur votre PC, puis téléchargez et installez Ubuntu 22.04.3 LTS (doit correspondre à la version à la ligne 2 du fichier docker)
Oui, vous avez bien lu ce qui précède : téléchargez et installez Ubuntu à partir de l'application Microsoft Store, reportez-vous à la capture d'écran ci-dessous :
Il est maintenant temps d'installer Nvidia Container Toolkit dans Ubuntu, suivez les étapes ci-dessous pour ce faire :
Lancez un shell Ubuntu sous Windows en recherchant Ubuntu dans le menu Démarrer une fois l'installation ci-dessus terminée.
Dans cette ligne de commande Ubuntu qui s'ouvre, effectuez les étapes suivantes :
Configurez le référentiel de production :
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
Mettez à jour la liste des packages à partir du référentiel et installez les packages Nvidia Container Toolkit :
sudo apt-get update && apt-get install -y nvidia-container-toolkit
Configurez le runtime du conteneur à l'aide de la commande nvidia-ctk, qui modifie le fichier /etc/docker/daemon.json afin que Docker puisse utiliser le runtime du conteneur Nvidia :
sudo nvidia-ctk runtime configure --runtime=docker
Redémarrez le démon Docker :
sudo systemctl restart docker
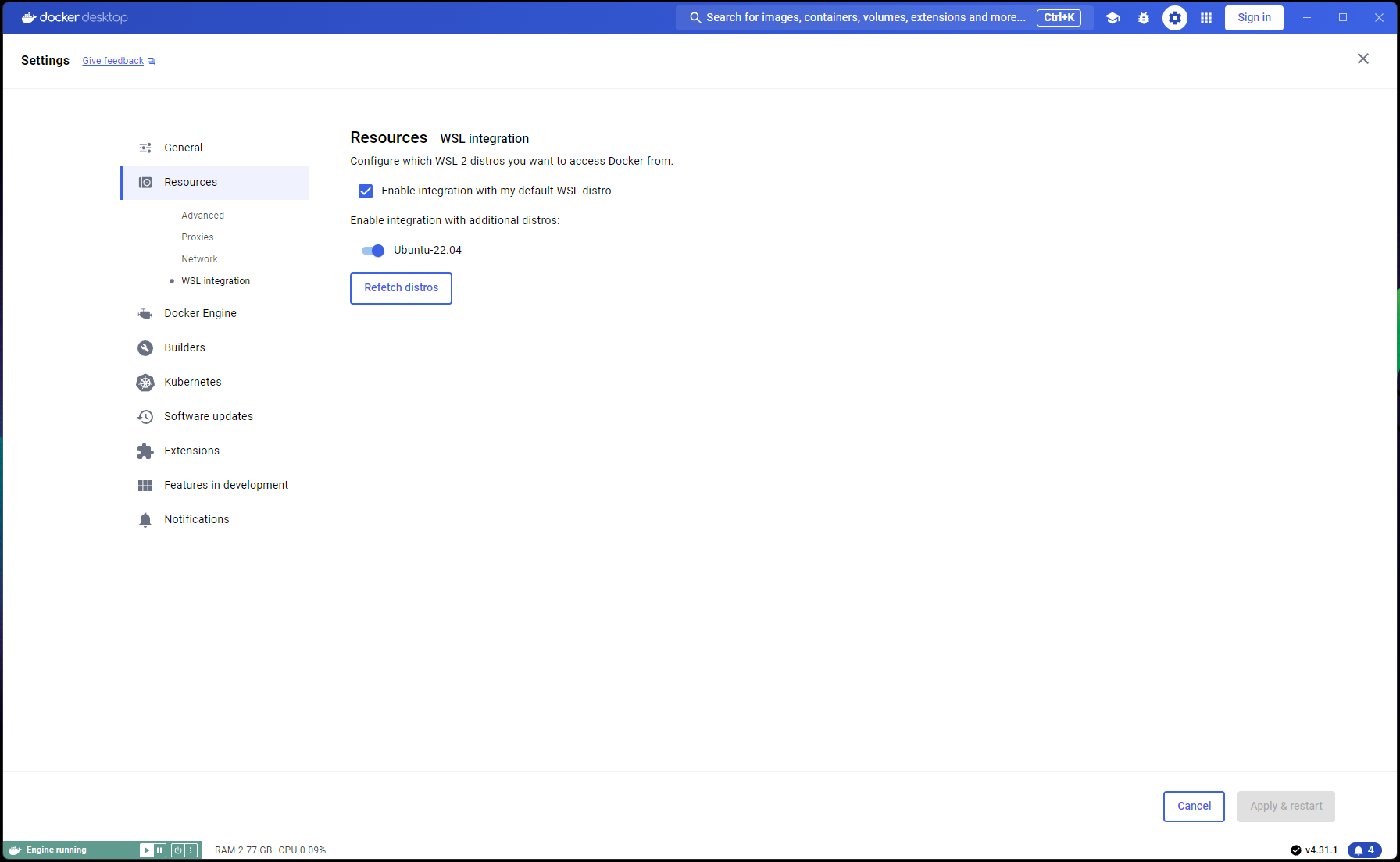
Maintenant que votre configuration Ubuntu est terminée, il est temps de terminer les intégrations WSL et Docker :
Ouvrez une nouvelle fenêtre PowerShell et définissez cette installation Ubuntu comme installation WSL par défaut :
wsl --list
wsl --set-default Ubuntu-22.04 # if not already marked as Default
Accédez à Docker Desktop -> Settings -> Resources -> WSL Integration -> Vérifier les intégrations par défaut et Ubuntu 22.04. Reportez-vous à la capture d'écran ci-dessous :
Maintenant, si tout a été fait correctement, vous êtes prêt à construire et exécuter le conteneur !
Dans une invite de commande/un terminal, exécutez les commandes suivantes :
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized_nvidia_cuda_gpu
docker build -t lars-nvcuda .
# Once the build is complete, run the container:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda
Une fois terminé, accédez à http://localhost:5000/ dans votre navigateur et suivez le reste des étapes de première exécution et du guide de l'utilisateur.
Les sections de dépannage s'appliquent également à Container-LARS.
Si vous rencontrez des erreurs liées au réseau, notamment en ce qui concerne les référentiels de packages indisponibles lors de la création du conteneur, il s'agit d'un problème de réseau de votre part, souvent lié à des problèmes de pare-feu.
Sous Windows, accédez à Control PanelSystem and SecurityWindows Defender FirewallAllowed apps , ou recherchez Firewall dans le menu Démarrer et dirigez-vous vers Allow an app through the firewall et assurez-vous que ```Docker Desktop Backend`` est autorisé à passer.
La première fois que vous exécutez LARS, le modèle d'intégration des transformateurs de phrases sera téléchargé
Dans l'environnement conteneurisé, ce téléchargement peut parfois s'avérer problématique et entraîner des erreurs lorsque vous posez une requête
Si cela se produit, rendez-vous simplement dans le menu Paramètres LARS : Settings->VectorDB & Embedding Models et modifiez le modèle d'intégration en BGE-Base ou BGE-Large, cela forcera un rechargement et un nouveau téléchargement.
Une fois cela fait, posez à nouveau des questions et la réponse devrait générer normalement
Vous pouvez revenir au modèle d'intégration des transformateurs de phrases et le problème devrait être résolu.
Comme indiqué dans la section Dépannage ci-dessus, les modèles d'intégration sont téléchargés lors de la première exécution de LARS.
Il est préférable de sauvegarder l'état du conteneur avant de l'arrêter afin que cette étape de téléchargement n'ait pas besoin d'être répétée à chaque lancement ultérieur du conteneur.
Pour ce faire, ouvrez une autre invite de commande/terminal et validez les modifications AVANT de fermer le conteneur LARS en cours d'exécution :
docker ps # note the container_id here
docker commit <container_ID> <new_image_name> # for new_image_name, I simply add 'pfr', for 'post-first-run' to the current image name, example: lars-nvcuda-pfr
Cela créera une image mise à jour que vous pourrez utiliser lors des exécutions ultérieures :
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda-pfr
REMARQUE : Après avoir effectué ce qui précède, si vous vérifiez l'espace utilisé par les images avec docker images , vous remarquerez beaucoup d'espace utilisé. MAIS, ne prenez pas les tailles ici au pied de la lettre ! La taille affichée pour chaque image inclut la taille totale de tous ses calques, mais bon nombre de ces calques sont partagés entre les images, surtout si ces images sont basées sur la même image de base ou si une image est une version validée d'une autre. Pour voir combien d'espace disque vos images Docker utilisent réellement, utilisez :
docker system df
Retour à la table des matières
| Catégorie | Tâches | Statut |
|---|---|---|
| Corrections de bugs : | Risque de création de fichier texte de zéro octet - Parfois, si l'extraction OCR/texte du document d'entrée échoue, un fichier .txt 0B peut être laissé, ce qui provoque de nouvelles tentatives pour croire que le fichier a déjà été chargé. | ? Tâche future |
| Caractéristiques pratiques : | Centré sur la facilité d’utilisation : | |
| Bascule de l’interface utilisateur de niveau gratuit Azure CV-OCR | ✅ Fait le 8 juin 2024 | |
| Supprimer les discussions | ? Tâche future | |
| Renommer les discussions | ? Tâche future | |
| Script d'installation PowerShell | ? Tâche future | |
| Script d'installation Linux | ? Tâche future | |
| Backend d'inférence Ollama LLM comme alternative à lama.cpp | ? Tâche future | |
| Intégration des services OCR d'autres fournisseurs de cloud (GCP, AWS, OCI, etc.) | ? Tâche future | |
| Bascule de l'interface utilisateur pour ignorer les extraits de texte précédents lors du téléchargement d'un document | ? Tâche future | |
| Popup modal pour les téléchargements de fichiers : miroir des options d'extraction de texte à partir des paramètres, écrasement global des soumissions, bascule pour conserver les paramètres | ? Tâche future | |
| Centré sur les performances : | ||
| Prise en charge de Nvidia TensorRT-LLM AWQ | ? Tâche future | |
| Tâches de recherche : | Enquêter sur Nvidia TensorRT-LLM : nécessite la création de moteurs TRT AWQ-LLM spécifiques au GPU cible, NvTensorRT-LLM est son propre écosystème et ne fonctionne que sur Python v3.10. | ✅ Fait le 13 juin 2024 |
| OCR local avec Vision LLM : MS-TrOCR (terminé), Kosmos-2.5 (haute priorité), Llava, Florence-2 | ? Mise à jour en cours du 5 juillet 2024 | |
| Améliorations RAG : Re-ranker, RAPTOR, T-RAG | ? Tâche future | |
| Étudier l'intégration de GraphDB : utiliser des LLM pour extraire des données sur les relations entre entités à partir de documents et remplir, mettre à jour et maintenir une GraphDB | ? Tâche future |
Retour à la table des matières
J'espère que LARS a été précieux dans votre travail, et je vous invite à soutenir son développement continu ! Si vous appréciez l’outil et souhaitez contribuer à ses futures améliorations, pensez à faire un don. Votre soutien m'aide à continuer à améliorer LARS et à ajouter de nouvelles fonctionnalités.
Comment faire un don Pour faire un don, veuillez utiliser le lien suivant vers mon PayPal :
Faites un don via PayPal
Vos contributions sont grandement appréciées et seront utilisées pour financer d’autres efforts de développement.
Retour à la table des matières


