instructor php
1.0.0
Extraction de données structurées en PHP, optimisée par des LLM. Conçu pour la simplicité, la transparence et le contrôle.
Instructor est une bibliothèque qui vous permet d'extraire des données structurées et validées à partir de plusieurs types d'entrées : texte, images ou tableaux de séquences de discussion de style OpenAI. Il est alimenté par des modèles de langage étendus (LLM).
L'instructeur simplifie l'intégration LLM dans les projets PHP. Il gère la complexité de l'extraction de données structurées à partir des sorties LLM, afin que vous puissiez vous concentrer sur la création de votre logique d'application et itérer plus rapidement.
Instructor for PHP est inspiré de la bibliothèque Instructor pour Python créée par Jason Liu.
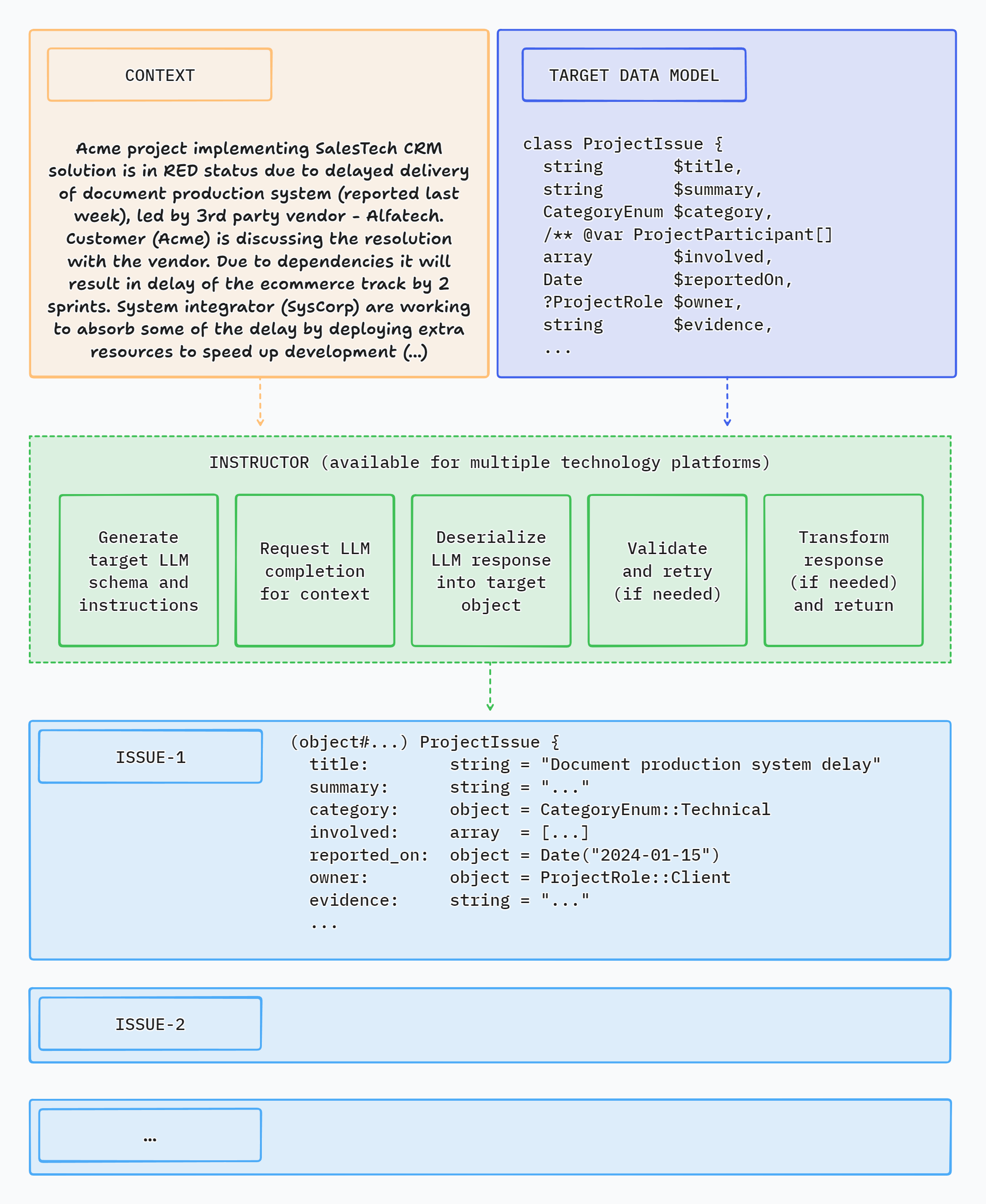
Voici une application de démonstration CLI simple utilisant Instructor pour extraire des données structurées à partir d'un texte :

Structure .Découvrez les implémentations dans d’autres langues ci-dessous :
Si vous souhaitez porter Instructor dans une autre langue, veuillez nous contacter sur Twitter, nous serions ravis de vous aider à démarrer !
L'instructeur introduit trois améliorations clés par rapport à l'utilisation directe de l'API.
Il vous suffit de spécifier une classe PHP dans laquelle extraire les données via la « magie » de la complétion du chat LLM. Et c'est tout.
L'instructeur réduit la fragilité du code en extrayant les informations des données textuelles en tirant parti des réponses LLM structurées.
Instructor vous aide à écrire du code plus simple et plus facile à comprendre : vous n'avez plus besoin de définir de longues définitions d'appel de fonction ou d'écrire du code pour attribuer le JSON renvoyé aux objets de données cibles.
Le modèle de réponse généré par LLM peut être automatiquement validé, selon un ensemble de règles. Actuellement, Instructor ne prend en charge que la validation Symfony.
Vous pouvez également fournir un objet contextuel pour utiliser les fonctionnalités améliorées du validateur.
Vous pouvez définir le nombre de nouvelles tentatives pour les demandes.
L'instructeur répétera les demandes en cas d'erreur de validation ou de désérialisation jusqu'au nombre de fois spécifié, en essayant d'obtenir une réponse valide de LLM.
L’installation d’Instructor est simple. Exécutez la commande suivante dans votre terminal et vous êtes sur la bonne voie vers une expérience de gestion des données plus fluide !
composer require cognesy/instructor-phpIl s'agit d'un exemple simple démontrant comment l'instructeur récupère des informations structurées à partir du texte fourni (ou d'une séquence de messages de discussion).
La classe de modèle de réponse est une classe PHP simple avec des indications de type spécifiant les types de champs de l'objet.
use Cognesy Instructor Instructor ;
// Step 0: Create .env file in your project root:
// OPENAI_API_KEY=your_api_key
// Step 1: Define target data structure(s)
class Person {
public string $ name ;
public int $ age ;
}
// Step 2: Provide content to process
$ text = " His name is Jason and he is 28 years old. " ;
// Step 3: Use Instructor to run LLM inference
$ person = ( new Instructor )-> respond (
messages: $ text ,
responseModel: Person ::class,
);
// Step 4: Work with structured response data
assert ( $ person instanceof Person ); // true
assert ( $ person -> name === ' Jason ' ); // true
assert ( $ person -> age === 28 ); // true
echo $ person -> name ; // Jason
echo $ person -> age ; // 28
var_dump ( $ person );
// Person {
// name: "Jason",
// age: 28
// } REMARQUE : L'instructeur prend en charge les classes/objets comme modèles de réponse. Si vous souhaitez extraire des types simples ou des énumérations, vous devez les envelopper dans un adaptateur scalaire - voir la section ci-dessous : Extraction de valeurs scalaires.
L'instructeur vous permet de définir plusieurs connexions API dans le fichier llm.php . Ceci est utile lorsque vous souhaitez utiliser différents LLM ou fournisseurs d'API dans votre application.
La configuration par défaut se trouve dans /config/llm.php dans le répertoire racine de la base de code de l'instructeur. Il contient un ensemble de connexions prédéfinies à toutes les API LLM prises en charge par l'instructeur.
Le fichier de configuration définit les connexions aux API LLM et leurs paramètres. Il spécifie également la connexion par défaut à utiliser lors de l'appel d'Instructor sans spécifier la connexion client.
// This is fragment of /config/llm.php file
' defaultConnection ' => ' openai ' ,
// . . .
' connections ' => [
' anthropic ' => [ ... ],
' azure ' => [ ... ],
' cohere1 ' => [ ... ],
' cohere2 ' => [ ... ],
' fireworks ' => [ ... ],
' gemini ' => [ ... ],
' grok ' => [ ... ],
' groq ' => [ ... ],
' mistral ' => [ ... ],
' ollama ' => [
' providerType ' => LLMProviderType :: Ollama -> value ,
' apiUrl ' => ' http://localhost:11434/v1 ' ,
' apiKey ' => Env :: get ( ' OLLAMA_API_KEY ' , '' ),
' endpoint ' => ' /chat/completions ' ,
' defaultModel ' => ' qwen2.5:0.5b ' ,
' defaultMaxTokens ' => 1024 ,
' httpClient ' => ' guzzle-ollama ' , // use custom HTTP client configuration
],
' openai ' => [ ... ],
' openrouter ' => [ ... ],
' together ' => [ ... ],
// ...Pour personnaliser les connexions disponibles, vous pouvez soit modifier les entrées existantes, soit ajouter les vôtres.
La connexion à l'API LLM via une connexion prédéfinie est aussi simple que d'appeler la méthode withClient avec le nom de la connexion.
<?php
// ...
$ user = ( new Instructor )
-> withConnection ( ' ollama ' )
-> respond (
messages: " His name is Jason and he is 28 years old. " ,
responseModel: Person ::class,
);
// ... Vous pouvez modifier l'emplacement des fichiers de configuration que l'instructeur doit utiliser via la variable d'environnement INSTRUCTOR_CONFIG_PATH . Vous pouvez utiliser des copies des fichiers de configuration par défaut comme point de départ.
L'instructeur propose un moyen d'utiliser des données structurées comme entrée. Ceci est utile lorsque vous souhaitez utiliser des données d'objet comme entrée et obtenir un autre objet avec le résultat de l'inférence LLM.
Le champ input des méthodes respond() et request() de l'instructeur peut être un objet, mais aussi un tableau ou simplement une chaîne.
<?php
use Cognesy Instructor Instructor ;
class Email {
public function __construct (
public string $ address = '' ,
public string $ subject = '' ,
public string $ body = '' ,
) {}
}
$ email = new Email (
address: ' joe@gmail ' ,
subject: ' Status update ' ,
body: ' Your account has been updated. '
);
$ translation = ( new Instructor )-> respond (
input: $ email ,
responseModel: Email ::class,
prompt: ' Translate the text fields of email to Spanish. Keep other fields unchanged. ' ,
);
assert ( $ translation instanceof Email ); // true
dump ( $ translation );
// Email {
// address: "joe@gmail",
// subject: "Actualización de estado",
// body: "Su cuenta ha sido actualizada."
// }
?>L'instructeur valide les résultats de la réponse LLM par rapport aux règles de validation spécifiées dans votre modèle de données.
Pour plus de détails sur les règles de validation disponibles, consultez les contraintes de validation Symfony.
use Symfony Component Validator Constraints as Assert ;
class Person {
public string $ name ;
#[ Assert PositiveOrZero ]
public int $ age ;
}
$ text = " His name is Jason, he is -28 years old. " ;
$ person = ( new Instructor )-> respond (
messages: [[ ' role ' => ' user ' , ' content ' => $ text ]],
responseModel: Person ::class,
);
// if the resulting object does not validate, Instructor throws an exceptionSi le paramètre maxRetries est fourni et que la réponse LLM ne répond pas aux critères de validation, l'instructeur effectuera des tentatives d'inférence ultérieures jusqu'à ce que les résultats répondent aux exigences ou que maxRetries soit atteint.
L'instructeur utilise les erreurs de validation pour informer LLM des problèmes identifiés dans la réponse, afin que LLM puisse essayer de s'auto-corriger lors de la prochaine tentative.
use Symfony Component Validator Constraints as Assert ;
class Person {
#[ Assert Length (min: 3 )]
public string $ name ;
#[ Assert PositiveOrZero ]
public int $ age ;
}
$ text = " His name is JX, aka Jason, he is -28 years old. " ;
$ person = ( new Instructor )-> respond (
messages: [[ ' role ' => ' user ' , ' content ' => $ text ]],
responseModel: Person ::class,
maxRetries: 3 ,
);
// if all LLM's attempts to self-correct the results fail, Instructor throws an exception Vous pouvez appeler la méthode request() pour définir les paramètres de la requête, puis appeler get() pour obtenir la réponse.
use Cognesy Instructor Instructor ;
$ instructor = ( new Instructor )-> request (
messages: " His name is Jason, he is 28 years old. " ,
responseModel: Person ::class,
);
$ person = $ instructor -> get ();Instructor prend en charge la diffusion en continu de résultats partiels, vous permettant de commencer à traiter les données dès qu'elles sont disponibles.
<?php
use Cognesy Instructor Instructor ;
$ stream = ( new Instructor )-> request (
messages: " His name is Jason, he is 28 years old. " ,
responseModel: Person ::class,
options: [ ' stream ' => true ]
)-> stream ();
foreach ( $ stream as $ partialPerson ) {
// process partial person data
echo $ partialPerson -> name ;
echo $ partialPerson -> age ;
}
// after streaming is done you can get the final, fully processed person object...
$ person = $ stream -> getLastUpdate ()
// . . . to, for example, save it to the database
$ db -> save ( $ person );
?> Vous pouvez définir le rappel onPartialUpdate() pour recevoir des résultats partiels qui peuvent être utilisés pour démarrer la mise à jour de l'interface utilisateur avant que LLM ne termine l'inférence.
REMARQUE : Les mises à jour partielles ne sont pas validées. La réponse n'est validée qu'après sa réception complète.
use Cognesy Instructor Instructor ;
function updateUI ( $ person ) {
// Here you get partially completed Person object update UI with the partial result
}
$ person = ( new Instructor )-> request (
messages: " His name is Jason, he is 28 years old. " ,
responseModel: Person ::class,
options: [ ' stream ' => true ]
)-> onPartialUpdate (
fn( $ partial ) => updateUI ( $ partial )
)-> get ();
// Here you get completed and validated Person object
$ this -> db -> save ( $ person ); // ...for example: save to DB Vous pouvez fournir une chaîne au lieu d'un tableau de messages. Ceci est utile lorsque vous souhaitez extraire des données d’un seul bloc de texte et que votre code reste simple.
// Usually, you work with sequences of messages:
$ value = ( new Instructor )-> respond (
messages: [[ ' role ' => ' user ' , ' content ' => " His name is Jason, he is 28 years old. " ]],
responseModel: Person ::class,
);
// ...but if you want to keep it simple, you can just pass a string:
$ value = ( new Instructor )-> respond (
messages: " His name is Jason, he is 28 years old. " ,
responseModel: Person ::class,
);Parfois, nous souhaitons simplement obtenir des résultats rapides sans définir de classe pour le modèle de réponse, surtout si nous essayons d'obtenir une réponse directe et simple sous forme de chaîne, d'entier, de booléen ou de flottant. L'instructeur fournit une API simplifiée pour de tels cas.
use Cognesy Instructor Extras Scalar Scalar ;
use Cognesy Instructor Instructor ;
$ value = ( new Instructor )-> respond (
messages: " His name is Jason, he is 28 years old. " ,
responseModel: Scalar :: integer ( ' age ' ),
);
var_dump ( $ value );
// int(28) Dans cet exemple, nous extrayons une seule valeur entière du texte. Vous pouvez également utiliser Scalar::string() , Scalar::boolean() et Scalar::float() pour extraire d'autres types de valeurs.
De plus, vous pouvez utiliser l'adaptateur Scalar pour extraire l'une des options fournies à l'aide Scalar::enum() .
use Cognesy Instructor Extras Scalar Scalar ;
use Cognesy Instructor Instructor ;
enum ActivityType : string {
case Work = ' work ' ;
case Entertainment = ' entertainment ' ;
case Sport = ' sport ' ;
case Other = ' other ' ;
}
$ value = ( new Instructor )-> respond (
messages: " His name is Jason, he currently plays Doom Eternal. " ,
responseModel: Scalar :: enum ( ActivityType ::class, ' activityType ' ),
);
var_dump ( $ value );
// enum(ActivityType:Entertainment)Sequence est une classe wrapper qui peut être utilisée pour représenter une liste d'objets à extraire par l'instructeur à partir du contexte fourni.
Il est généralement plus pratique de ne pas créer une classe dédiée avec une seule propriété de tableau uniquement pour gérer une liste d'objets d'une classe donnée.
Une caractéristique supplémentaire et unique des séquences est qu'elles peuvent être diffusées pour chaque élément terminé dans une séquence, plutôt que pour n'importe quelle mise à jour de propriété.
class Person
{
public string $ name ;
public int $ age ;
}
$ text = <<<TEXT
Jason is 25 years old. Jane is 18 yo. John is 30 years old
and Anna is 2 years younger than him.
TEXT ;
$ list = ( new Instructor )-> respond (
messages: [[ ' role ' => ' user ' , ' content ' => $ text ]],
responseModel: Sequence :: of ( Person ::class),
options: [ ' stream ' => true ]
);Pour en savoir plus sur les séquences, consultez la section Séquences.
Utilisez les indicateurs de type PHP pour spécifier le type de données extraites.
Utilisez des types nullables pour indiquer que le champ donné est facultatif.
class Person {
public string $ name ;
public ? int $ age ;
public Address $ address ;
}Vous pouvez également utiliser des commentaires de style PHP DocBlock pour spécifier le type de données extraites. Ceci est utile lorsque vous souhaitez spécifier des types de propriétés pour LLM, mais que vous ne pouvez pas ou ne voulez pas appliquer le type au niveau du code.
class Person {
/** @var string */
public $ name ;
/** @var int */
public $ age ;
/** @var Address $address person's address */
public $ address ;
}Voir la documentation PHPDoc pour plus de détails sur le site Web DocBlock.
PHP ne prend actuellement pas en charge les génériques ou les typeshints pour spécifier les types d'éléments de tableau.
Utilisez les commentaires de style PHP DocBlock pour spécifier le type d'éléments du tableau.
class Person {
// ...
}
class Event {
// ...
/** @var Person[] list of extracted event participants */
public array $ participants ;
// ...
}L'instructeur peut récupérer des structures de données complexes à partir du texte. Votre modèle de réponse peut contenir des objets imbriqués, des tableaux et des énumérations.
use Cognesy Instructor Instructor ;
// define a data structures to extract data into
class Person {
public string $ name ;
public int $ age ;
public string $ profession ;
/** @var Skill[] */
public array $ skills ;
}
class Skill {
public string $ name ;
public SkillType $ type ;
}
enum SkillType {
case Technical = ' technical ' ;
case Other = ' other ' ;
}
$ text = " Alex is 25 years old software engineer, who knows PHP, Python and can play the guitar. " ;
$ person = ( new Instructor )-> respond (
messages: [[ ' role ' => ' user ' , ' content ' => $ text ]],
responseModel: Person ::class,
); // client is passed explicitly, can specify e.g. different base URL
// data is extracted into an object of given class
assert ( $ person instanceof Person ); // true
// you can access object's extracted property values
echo $ person -> name ; // Alex
echo $ person -> age ; // 25
echo $ person -> profession ; // software engineer
echo $ person -> skills [ 0 ]-> name ; // PHP
echo $ person -> skills [ 0 ]-> type ; // SkillType::Technical
// ...
var_dump ( $ person );
// Person {
// name: "Alex",
// age: 25,
// profession: "software engineer",
// skills: [
// Skill {
// name: "PHP",
// type: SkillType::Technical,
// },
// Skill {
// name: "Python",
// type: SkillType::Technical,
// },
// Skill {
// name: "guitar",
// type: SkillType::Other
// },
// ]
// } Si vous souhaitez définir la forme des données pendant l'exécution, vous pouvez utiliser la classe Structure .
Les structures vous permettent de définir et de modifier la forme arbitraire des données à extraire par LLM. Les classes ne sont peut-être pas les mieux adaptées à cet effet, car il n'est pas possible de les déclarer ou de les modifier pendant l'exécution.
Avec les structures, vous pouvez définir dynamiquement des formes de données personnalisées, par exemple en fonction de la saisie de l'utilisateur ou du contexte du traitement, pour spécifier les informations que LLM doit déduire à partir du texte ou des messages de discussion fournis.
L'exemple ci-dessous montre comment définir une structure et l'utiliser comme modèle de réponse :
<?php
use Cognesy Instructor Extras Structure Field ;
use Cognesy Instructor Extras Structure Structure ;
enum Role : string {
case Manager = ' manager ' ;
case Line = ' line ' ;
}
$ structure = Structure :: define ( ' person ' , [
Field :: string ( ' name ' ),
Field :: int ( ' age ' ),
Field :: enum ( ' role ' , Role ::class),
]);
$ person = ( new Instructor )-> respond (
messages: ' Jason is 25 years old and is a manager. ' ,
responseModel: $ structure ,
);
// you can access structure data via field API...
assert ( $ person -> field ( ' name ' ) === ' Jason ' );
// ...or as structure object properties
assert ( $ person -> age === 25 );
?>Pour plus d'informations, consultez la section Structures.
Vous pouvez spécifier le modèle et d'autres options qui seront transmises au point de terminaison OpenAI/LLM.
use Cognesy Instructor Features LLM Data LLMConfig ;
use Cognesy Instructor Features LLM Drivers OpenAIDriver ;
use Cognesy Instructor Instructor ;
// OpenAI auth params
$ yourApiKey = Env :: get ( ' OPENAI_API_KEY ' ); // use your own API key
// Create instance of OpenAI driver initialized with custom parameters
$ driver = new OpenAIDriver ( new LLMConfig (
apiUrl: ' https://api.openai.com/v1 ' , // you can change base URI
apiKey: $ yourApiKey ,
endpoint: ' /chat/completions ' ,
metadata: [ ' organization ' => '' ],
model: ' gpt-4o-mini ' ,
maxTokens: 128 ,
));
/// Get Instructor with the default client component overridden with your own
$ instructor = ( new Instructor )-> withDriver ( $ driver );
$ user = $ instructor -> respond (
messages: " Jason (@jxnlco) is 25 years old and is the admin of this project. He likes playing football and reading books. " ,
responseModel: User ::class,
model: ' gpt-3.5-turbo ' ,
options: [ ' stream ' => true ]
);L'instructeur propose une assistance prête à l'emploi pour les fournisseurs d'API suivants :
Pour obtenir des exemples d'utilisation, consultez la section Hub ou le répertoire examples dans le référentiel de code.
Vous pouvez utiliser PHP DocBlocks (/** */) pour fournir des instructions supplémentaires pour LLM au niveau de la classe ou du champ, par exemple pour clarifier ce que vous attendez ou comment LLM doit traiter vos données.
L'instructeur extrait les commentaires PHP DocBlocks de la classe et de la propriété définies et les inclut dans la spécification du modèle de réponse envoyé à LLM.
L'utilisation des instructions PHP DocBlocks n'est pas obligatoire, mais vous souhaiterez parfois clarifier vos intentions pour améliorer les résultats d'inférence de LLM.
/**
* Represents a skill of a person and context in which it was mentioned.
*/
class Skill {
public string $ name ;
/** @var SkillType $type type of the skill, derived from the description and context */
public SkillType $ type ;
/** Directly quoted, full sentence mentioning person's skill */
public string $ context ;
}Vous pouvez utiliser le trait ValidationMixin pour ajouter la possibilité de valider des objets de données facilement et personnalisés.
use Cognesy Instructor Features Validation Traits ValidationMixin ;
class User {
use ValidationMixin ;
public int $ age ;
public int $ name ;
public function validate () : array {
if ( $ this -> age < 18 ) {
return [ " User has to be adult to sign the contract. " ];
}
return [];
}
}L'instructeur utilise le composant de validation Symfony pour valider les données extraites. Vous pouvez utiliser l'annotation #[Assert/Callback] pour créer une logique de validation entièrement personnalisée.
use Cognesy Instructor Instructor ;
use Symfony Component Validator Constraints as Assert ;
use Symfony

