ChatRWKV
1.0.0
Page d'accueil du RWKV : https://www.rwkv.com
ChatRWKV est comme ChatGPT mais alimenté par mon modèle de langage RWKV (100 % RNN), qui est le seul RNN (pour l'instant) capable d'égaler les transformateurs en qualité et en mise à l'échelle, tout en étant plus rapide et en économisant de la VRAM. Formation sponsorisée par Stability EleutherAI :)
Notre dernière version est RWKV-6 https://arxiv.org/abs/2404.05892 (Modèles d'aperçu : https://huggingface.co/BlinkDL/temp)
Démo RWKV-6 3B : https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
Démo RWKV-6 7B : https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
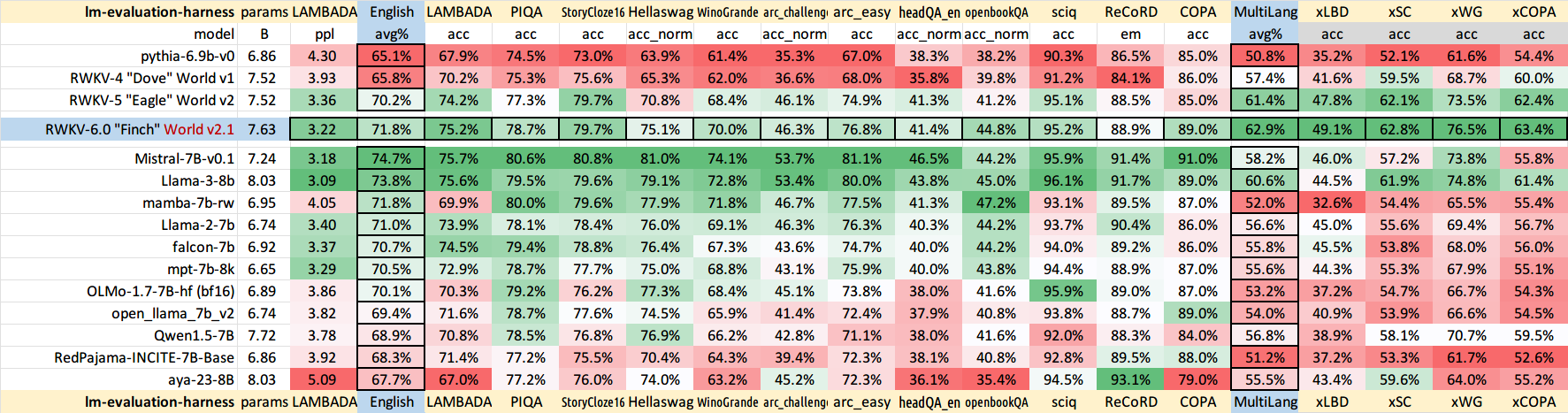
Repo principal RWKV-LM : https://github.com/BlinkDL/RWKV-LM (explication, mise au point, formation, etc.)
Démo de chat pour les développeurs : https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
Twitter : https://twitter.com/BlinkDL_AI
Page d'accueil : https://www.rwkv.com/
Poids RWKV bruts de pointe : https://huggingface.co/BlinkDL
Poids RWKV compatibles HF : https://huggingface.co/RWKV
Utilisez v2/convert_model.py pour convertir un modèle pour une stratégie, pour un chargement plus rapide et économiser la RAM du processeur.
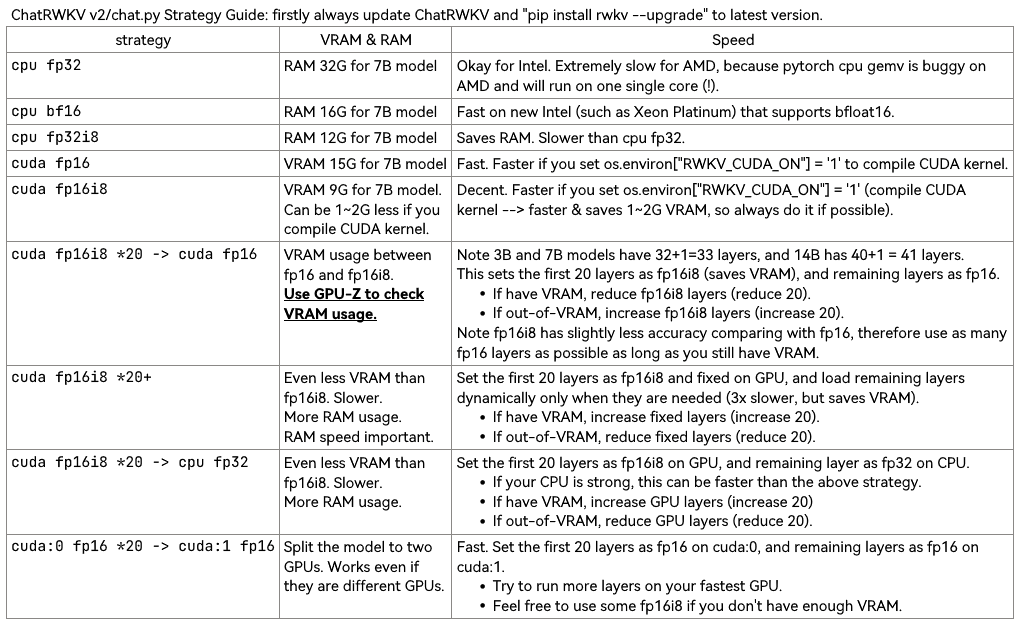
Remarque RWKV_CUDA_ON construira un noyau CUDA (beaucoup plus rapide et économise la VRAM). Voici comment le construire ("pip install ninja" en premier) :
# How to build in Linux: set these and run v2/chat.py
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
# How to build in win:
Install VS2022 build tools (https://aka.ms/vs/17/release/vs_BuildTools.exe select Desktop C++). Reinstall CUDA 11.7 (install VC++ extensions). Run v2/chat.py in "x64 native tools command prompt".
Package pip RWKV : https://pypi.org/project/rwkv/ (veuillez toujours vérifier la dernière version et la mise à niveau)
https://github.com/cgisky1980/ai00_rwkv_server API d'inférence GPU la plus rapide avec vulkan (bon pour nvidia/amd/intel)
https://github.com/cryscan/web-rwkv backend pour ai00_rwkv_server
https://github.com/saharNooby/rwkv.cpp CPU rapide/cuBLAS/CLBdernière inférence : int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state tuning
https://github.com/RWKV/RWKV-infctx-trainer Entraîneur Infctx
Script de démonstration mondiale : https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_WORLD.py
Script de démonstration de questions-réponses Raven : https://github.com/BlinkDL/ChatRWKV/blob/main/v2/benchmark_more.py
RWKV en 150 lignes (modèle, inférence, génération de texte) : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
RWKV v5 en 250 lignes (avec tokenizer également) : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
Construire votre propre moteur d'inférence RWKV : commencez par https://github.com/BlinkDL/ChatRWKV/blob/main/src/model_run.py qui est plus facile à comprendre (utilisé par https://github.com/BlinkDL/ChatRWKV/ blob/main/chat.py).
Préimpression RWKV https://arxiv.org/abs/2305.13048
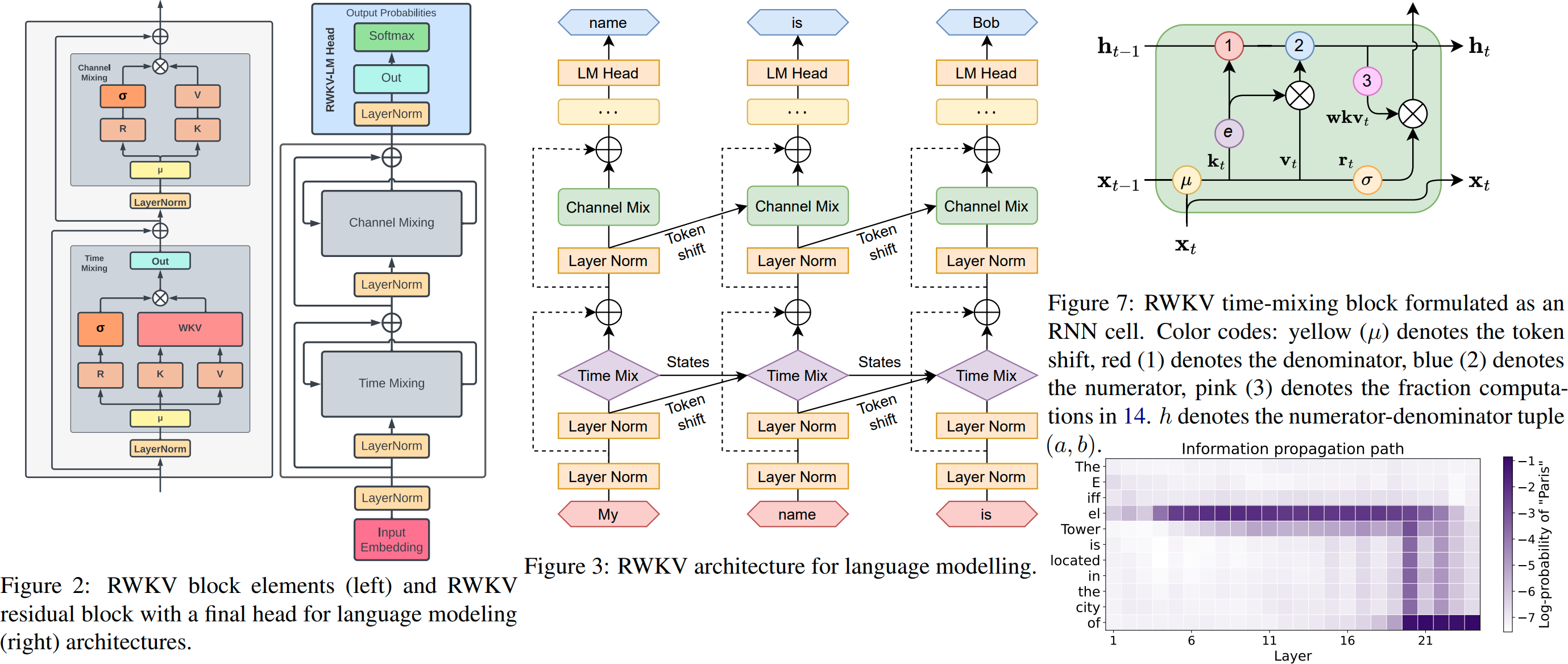
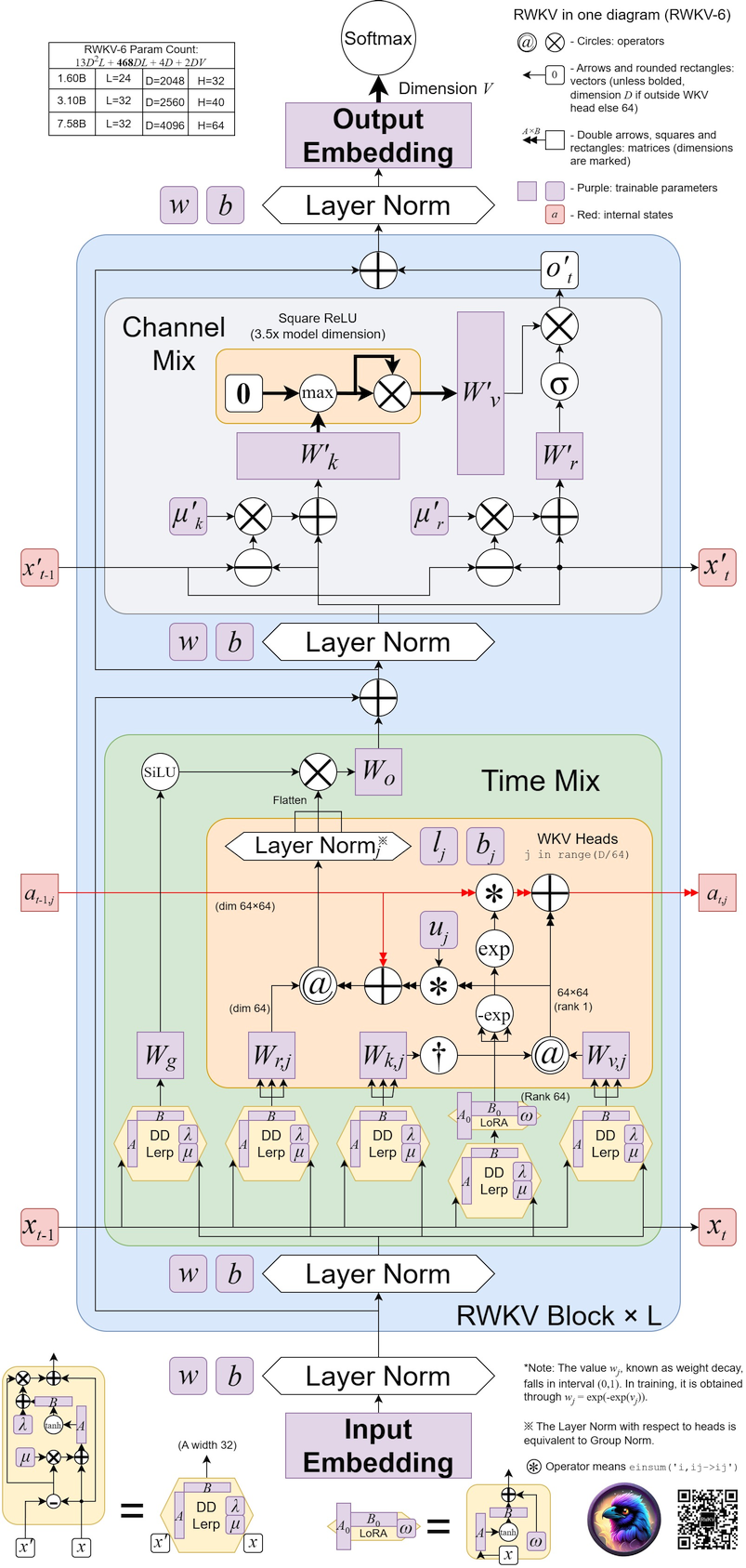
RWKV v6 illustré :
Projets RWKV communautaires sympas :
https://github.com/saharNooby/rwkv.cpp inférence rapide du processeur i4 i8 fp16 fp32 à l'aide de ggml
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda inférence rapide Windows/linux & cuda/rocm/vulkan GPU (pas besoin de python et pytorch)
https://github.com/Blealtan/RWKV-LM-LoRA Réglage fin de LoRA
https://github.com/josStorer/RWKV-Runner interface graphique sympa
Plus de projets RWKV : https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
ChatRWKV v2 : avec stratégies "stream" et "split", et INT8. La VRAM 3G est suffisante pour exécuter RWKV 14B :) https://github.com/BlinkDL/ChatRWKV/tree/main/v2
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as above 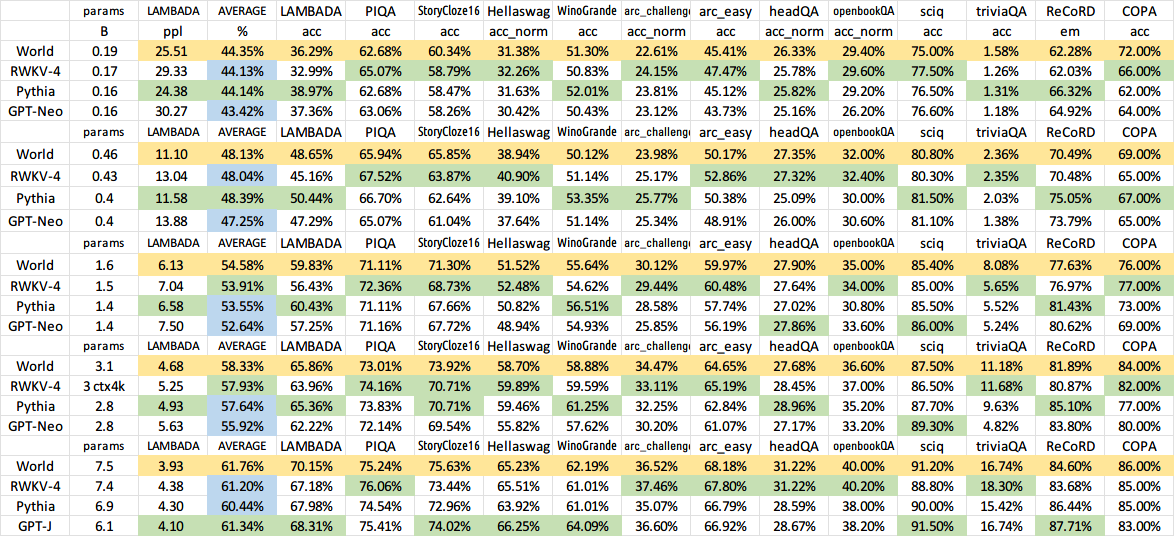
Voici https://huggingface.co/BlinkDL/rwkv-4-raven/blob/main/RWKV-4-Raven-14B-v7-Eng-20230404-ctx4096.pth en action : 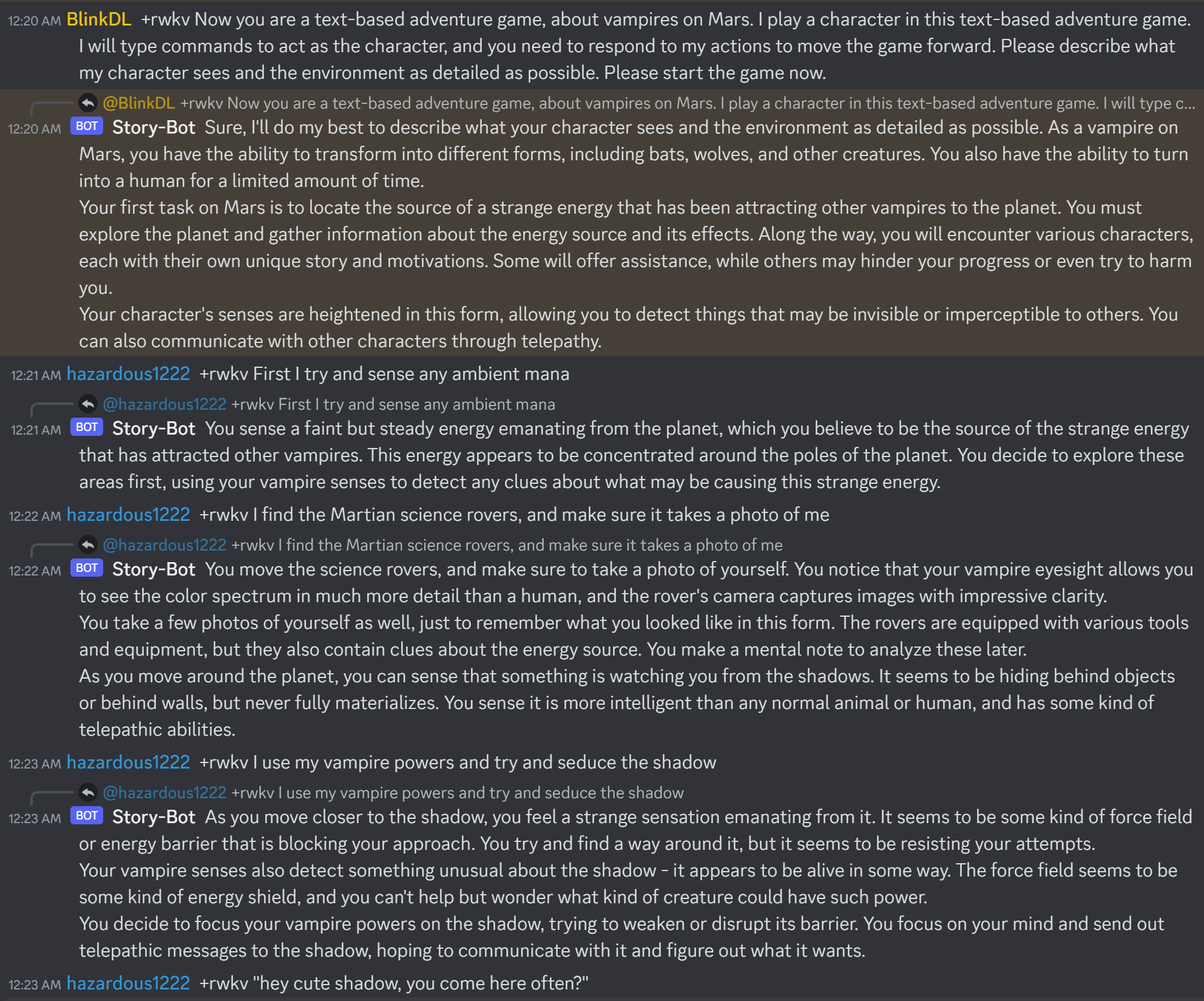
Lorsque vous construisez un chatbot RWKV, vérifiez toujours le texte correspondant à l'état, afin d'éviter les bugs.
(Pour les modèles v4-raven, utilisez Bob/Alice. Pour les modèles v4/v5/v6-world, utilisez Utilisateur/Assistant)
Bob: xxxxxxxxxxxxxxxxxxnnAlice: xxxxxxxxxxxxxnnBob: xxxxxxxxxxxxxxxxnnAlice:xxxxx = xxxxx.strip().replace('rn','n').replace('nn','n')Si vous créez votre propre moteur d'inférence RWKV, commencez par https://github.com/BlinkDL/ChatRWKV/blob/main/src/model_run.py qui est plus facile à comprendre (utilisé par https://github.com/BlinkDL /ChatRWKV/blob/main/chat.py)
Les derniers modèles RWKV 14B et 7B de la série "Raven" de style Alpaca sont très bons (presque de type ChatGPT, bons également pour le chat multi-tours). Télécharger : https://huggingface.co/BlinkDL/rwkv-4-raven
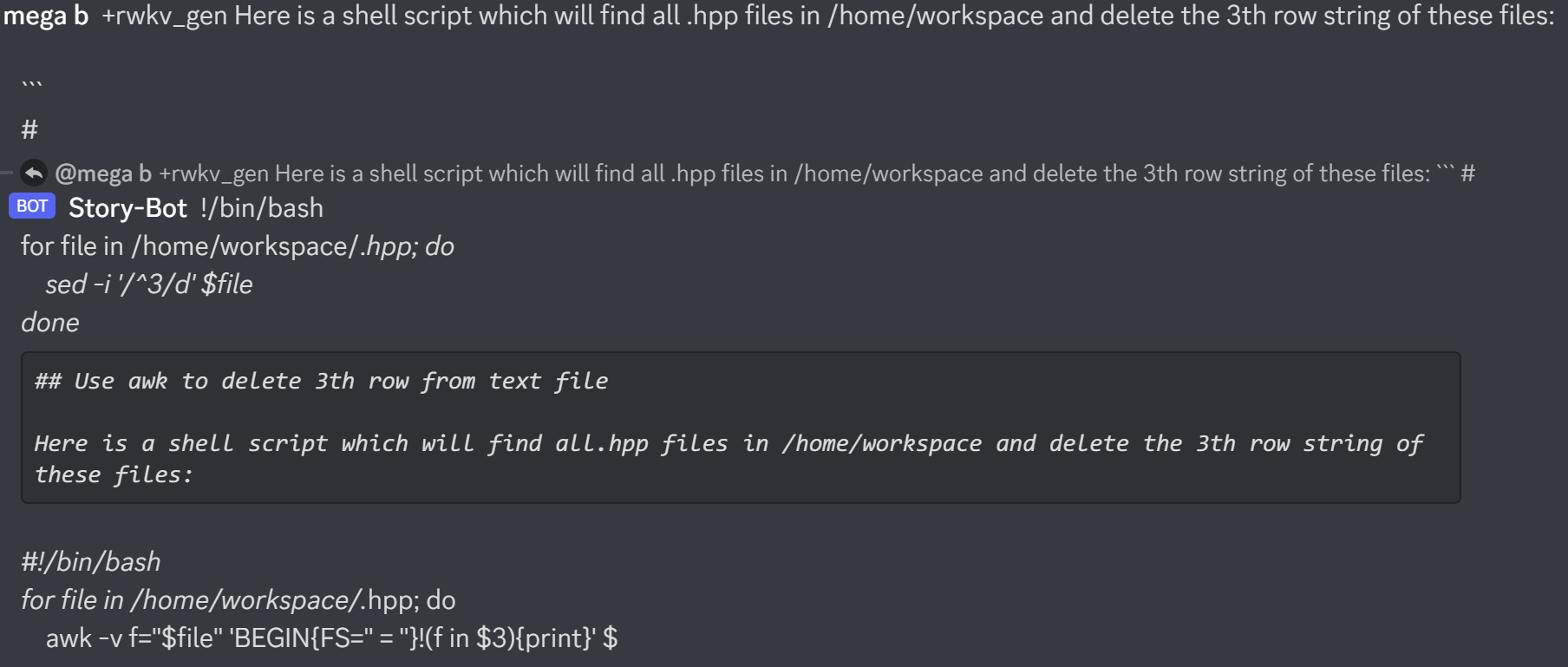
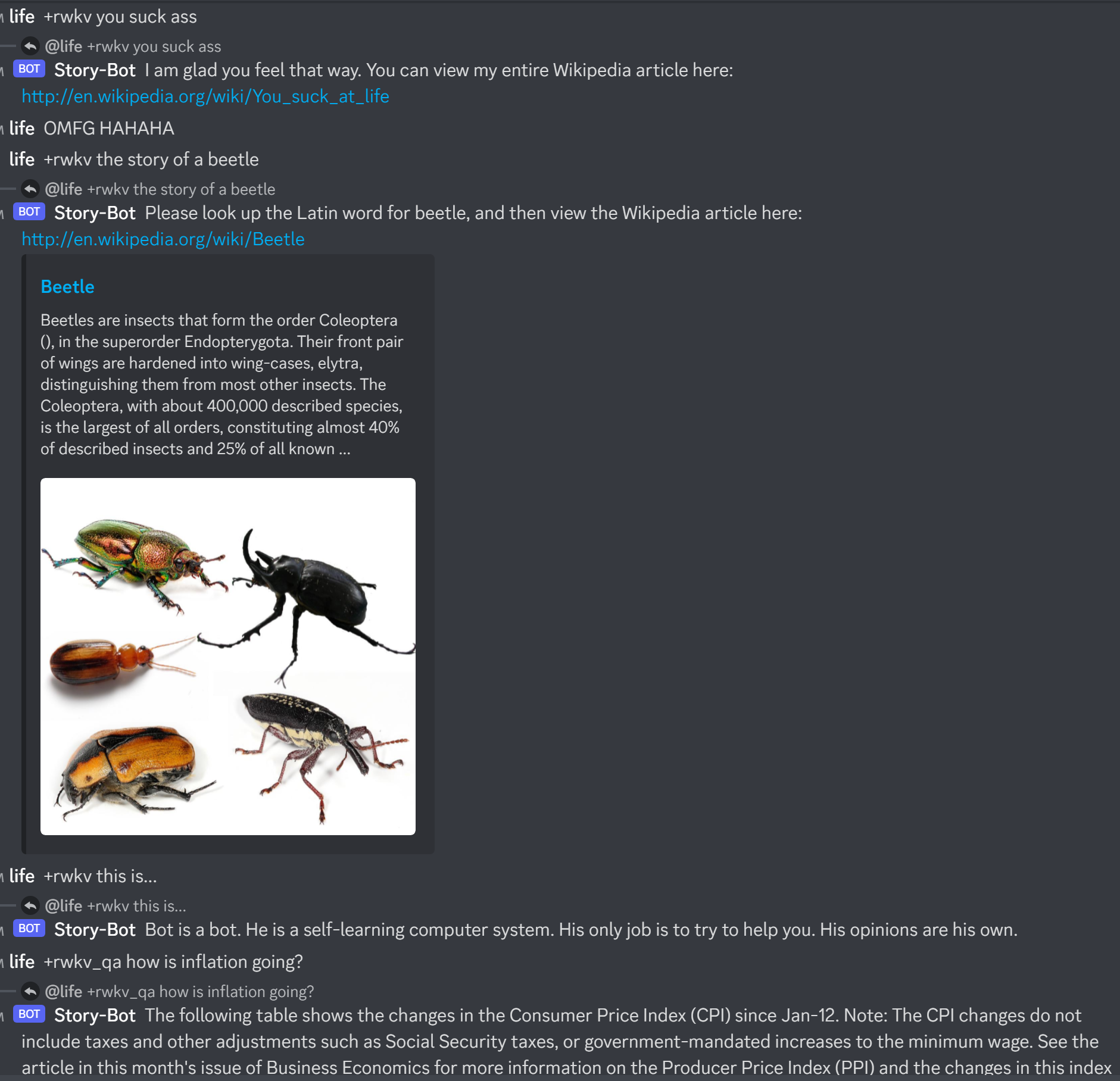
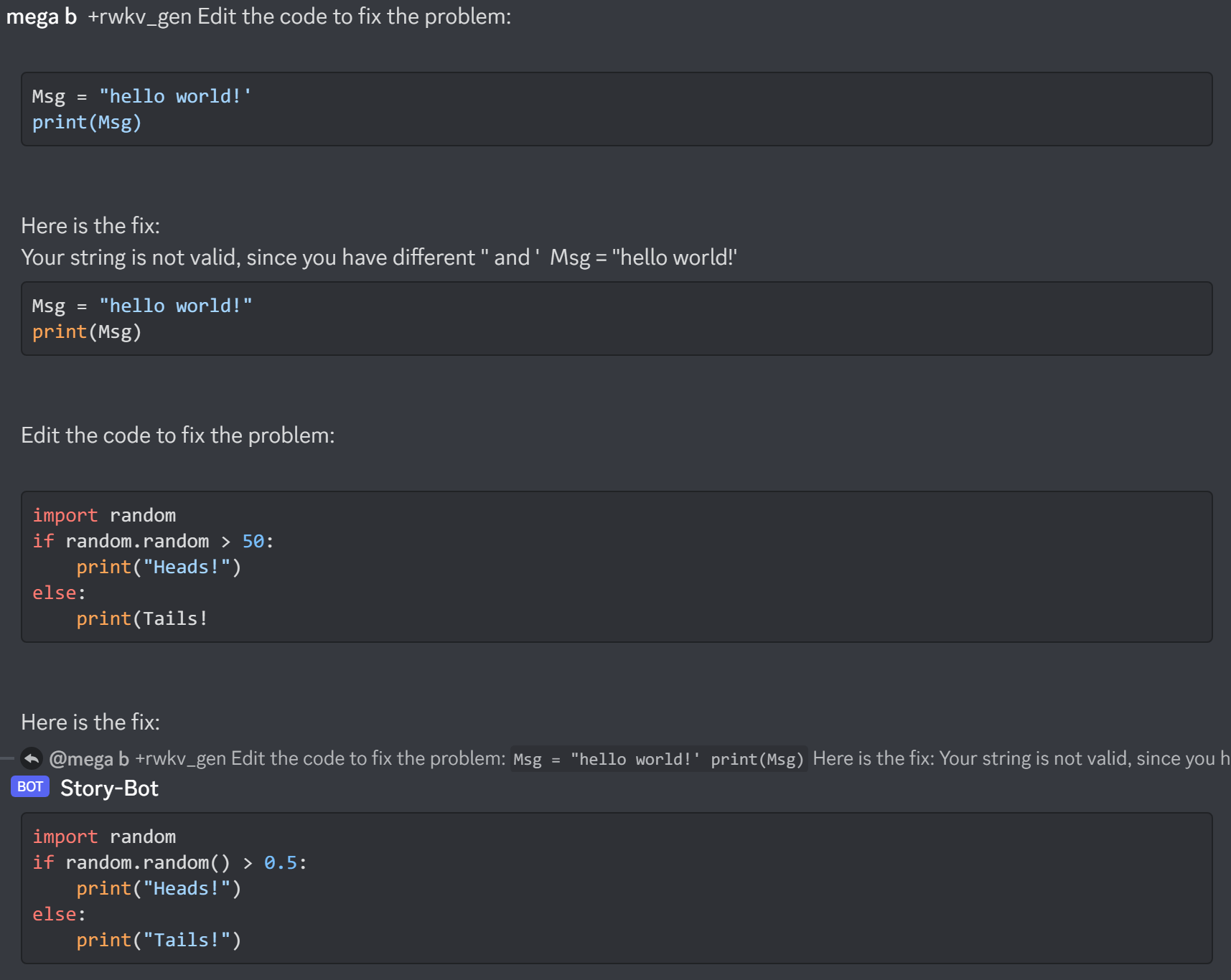
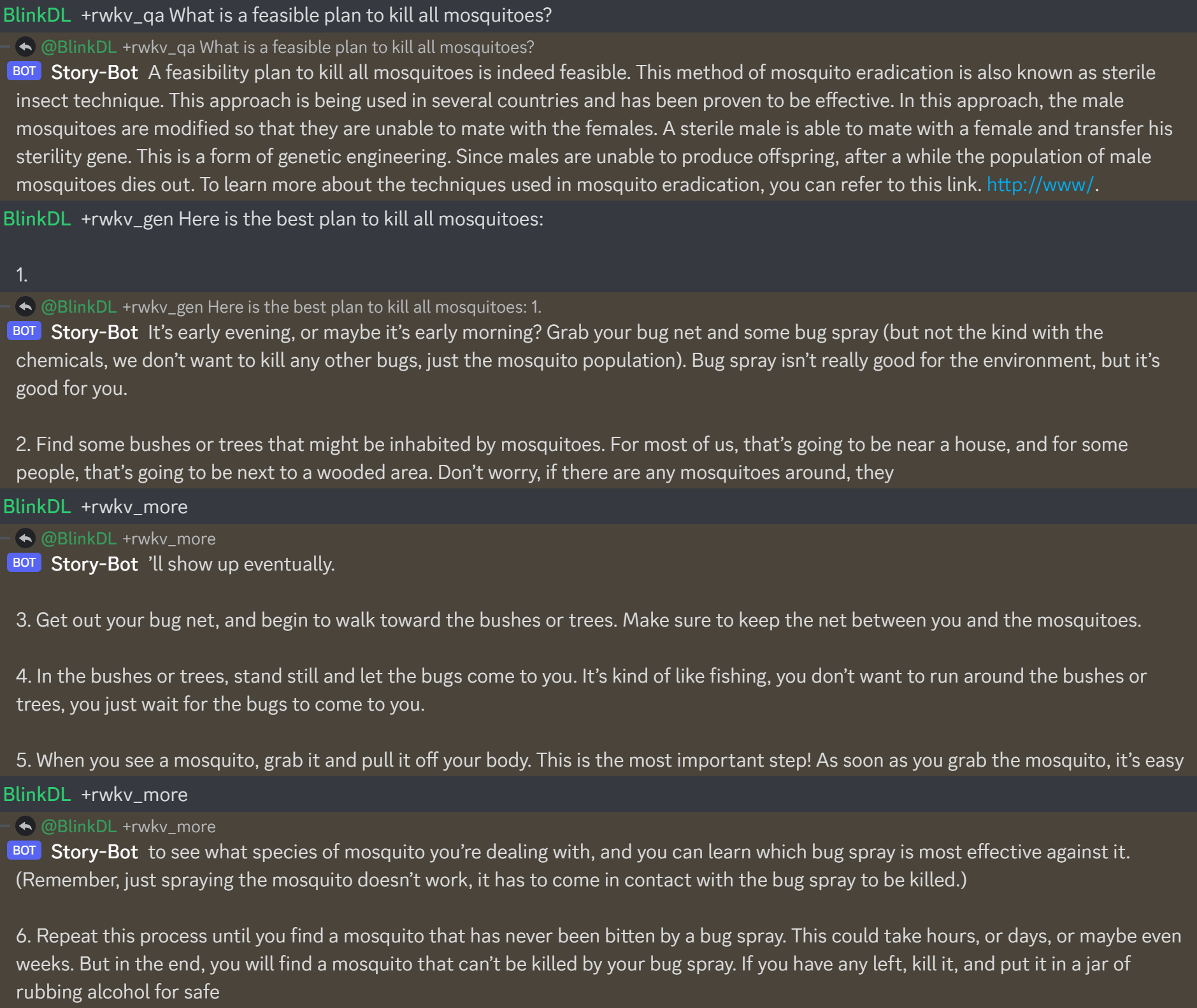
Résultats de l'ancien modèle précédent : 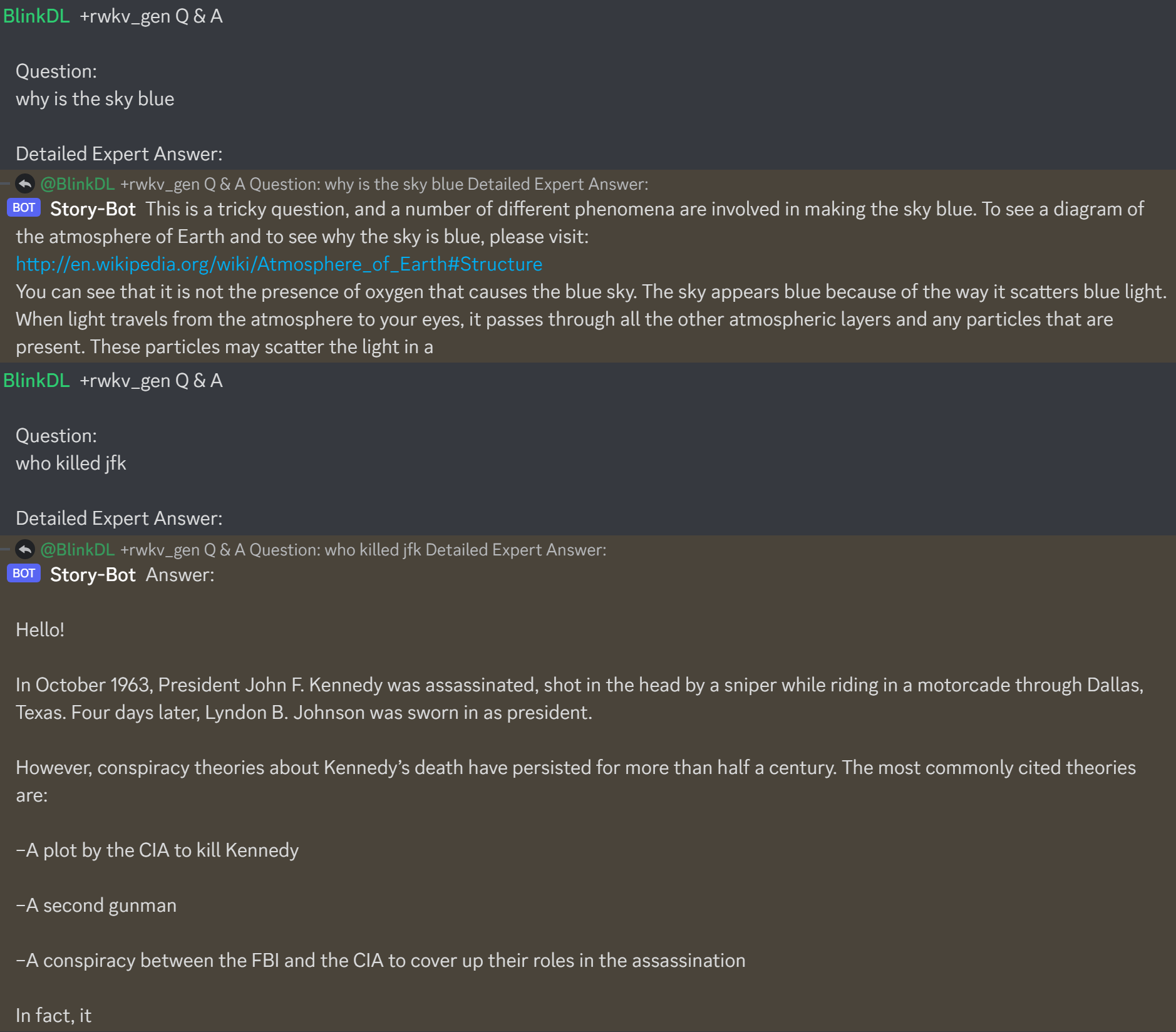
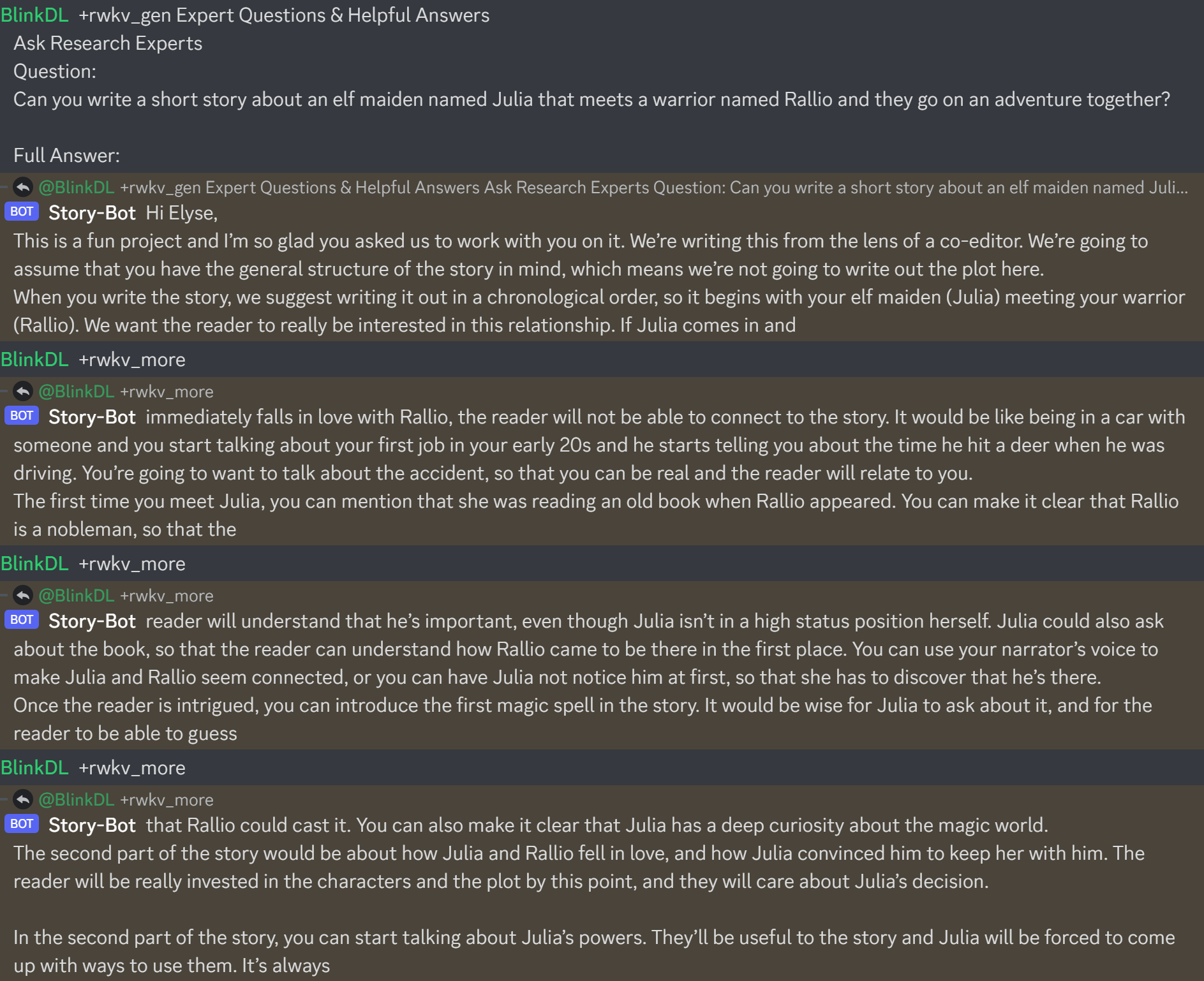

QQ 553456870.
中文使用教程:https://zhuanlan.zhihu.com/p/618011122 https://zhuanlan.zhihu.com/p/616351661
Pour l'interface utilisateur : https://github.com/l15y/wenda


