BLIVA
1.0.0
Wenbo Hu*, Yifan Xu*, Yi Li, Weiyue Li, Zeyuan Chen et Zhuowen Tu. *Contribution égale
Université de Californie à San Diego , Coinbase Global, Inc.
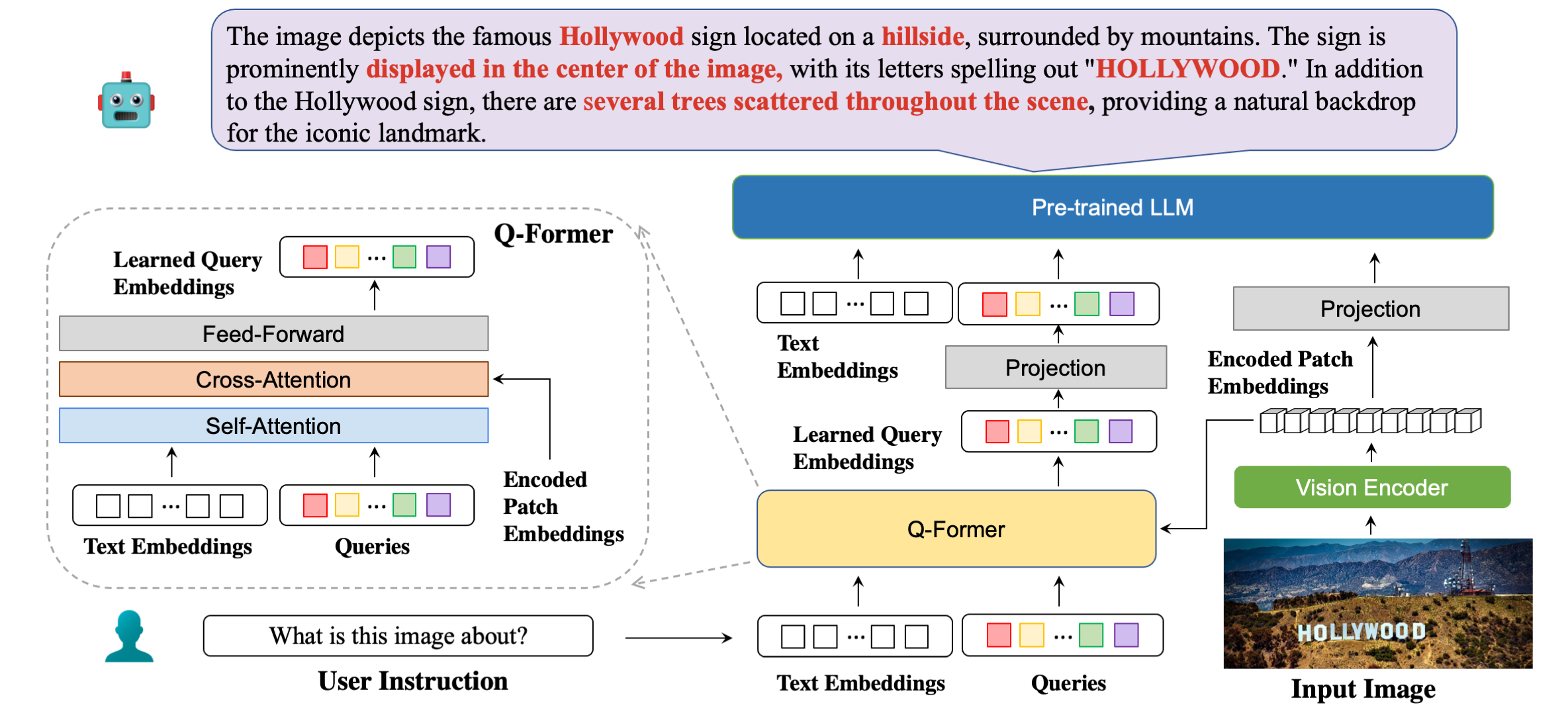
Notre architecture de modèle en détail avec des exemples de réponses.
| Méthode | STVQA | OCRVQA | TexteVQA | DocVQA | InfoVQA | GraphiqueQA | ESTVQA | FONDS | SROIE | POIE | Moyenne |
|---|---|---|---|---|---|---|---|---|---|---|---|
| OuvrirFlamingo | 19h32 | 27.82 | 29.08 | 5.05 | 14,99 | 9.12 | 28h20 | 0,85 | 0,12 | 2.12 | 13.67 |
| BLIP2-OPT | 13.36 | 10.58 | 21h18 | 0,82 | 8,82 | 7.44 | 27.02 | 0,00 | 0,00 | 0,02 | 8,92 |
| BLIP2-FLanT5XXL | 21h38 | 30.28 | 30.62 | 16h00 | 10.17 | 7h20 | 42.46 | 1.19 | 0,20 | 2,52 | 15h00 |
| MiniGPT4 | 14.02 | 11h52 | 18.72 | 2,97 | 13h32 | 4.32 | 28.36 | 1.19 | 0,04 | 1.31 | 9.58 |
| LLaVA | 22.93 | 15.02 | 28h30 | 4h40 | 13.78 | 7.28 | 33.48 | 1.02 | 0,12 | 2.09 | 12.84 |
| mPLUG-Chouette | 26h32 | 35h00 | 37.44 | 6.17 | 16h46 | 9.52 | 49,68 | 1.02 | 0,64 | 3.26 | 18h56 |
| InstruireBLIP (FLANT5XXL) | 26.22 | 55.04 | 36,86 | 4,94 | 10.14 | 8.16 | 43,84 | 1,36 | 0,50 | 1,91 | 18h90 |
| InstructBLIP (Vicuna-7B) | 28.64 | 47.62 | 39.60 | 5,89 | 13h10 | 5.52 | 47,66 | 0,85 | 0,64 | 2,66 | 19.22 |
| BLIVA (FLANT5XXL) | 28.24 | 61.34 | 39.36 | 5.22 | 10.82 | 9.28 | 45,66 | 1,53 | 0,50 | 2,39 | 20h43 |
| BLIVA (Vigogne-7B) | 29.08 | 65.38 | 42.18 | 6.24 | 13h50 | 8.16 | 48.14 | 1.02 | 0,88 | 2,91 | 21h75 |
| Méthode | VSR | IcôneQA | TexteVQA | Cadran visuel | Flickr30K | HM | Visualisation | MSRVTT |
|---|---|---|---|---|---|---|---|---|
| Flamant-3B | - | - | 30.1 | - | 60,6 | - | - | - |
| Flamant-9B | - | - | 31,8 | - | 61,5 | - | - | - |
| Flamant-80B | - | - | 35,0 | - | 67.2 | - | - | - |
| MiniGPT-4 | 50,65 | - | 18h56 | - | - | 29,0 | 34,78 | - |
| LLaVA | 56.3 | - | 37,98 | - | - | 9.2 | 36,74 | - |
| BLIP-2 (Vigogne-7B) | 50,0 | 39,7 | 40.1 | 44,9 | 74,9 | 50,2 | 49.34 | 4.17 |
| InstructBLIP (Vicuna-7B) | 54.3 | 43.1 | 50,1 | 45.2 | 82,4 | 54,8 | 43.3 | 18.7 |
| BLIVA (Vigogne-7B) | 62.2 | 44,88 | 57,96 | 45.63 | 87.1 | 55,6 | 42,9 | 23.81 |
conda create -n bliva python=3.9
conda activate blivagit clone https://github.com/mlpc-ucsd/BLIVA
cd BLIVA
pip install -e . BLIVA Vigogne 7B
Notre modèle version Vicuna est publié ici. Téléchargez notre poids de modèle et spécifiez le chemin dans la configuration du modèle ici à la ligne 8.
Le LLM que nous avons utilisé est la version v0.1 de Vicuna-7B. Pour préparer le poids de Vicuna, veuillez vous référer à nos instructions ici. Ensuite, définissez le chemin d'accès au poids de la vigogne dans le fichier de configuration du modèle ici, sur la ligne 21.
BLIVA FlanT5 XXL (disponible pour un usage commercial)
Le modèle de la version FlanT5 est publié ici. Téléchargez notre poids de modèle et spécifiez le chemin dans la configuration du modèle ici à la ligne 8.
Le poids LLM pour Flant5 commencera automatiquement à être téléchargé depuis huggingface lors de l'exécution de notre code d'inférence.
Pour répondre à une question de l’image, exécutez le code d’évaluation suivant. Par exemple,
python evaluate.py --answer_qs
--model_name bliva_vicuna
--img_path images/example.jpg
--question " what is this image about? "Nous prenons également en charge les réponses aux questions à choix multiples, qui sont les mêmes que celles que nous avons utilisées pour les tâches d'évaluation sur papier. Pour fournir une liste de choix, il doit s'agir d'une chaîne divisée par une virgule. Par exemple,
python evaluate.py --answer_mc
--model_name bliva_vicuna
--img_path images/mi6.png
--question " Which genre does this image belong to? "
--candidates " play, tv show, movie " Notre démo est accessible au public ici. Pour exécuter notre démo localement sur votre machine. Courir:
python demo.pyAprès avoir téléchargé les ensembles de données de formation et spécifié leur chemin dans les configurations des ensembles de données, nous sommes prêts pour la formation. Nous avons utilisé 8x A6000 Ada dans nos expériences. Veuillez ajuster les hyperparamètres en fonction de vos ressources GPU. Le chargement du modèle peut prendre environ 2 minutes aux transformateurs, ce qui laisse un peu de temps au modèle pour commencer l'entraînement. Nous donnons ici un exemple de formation de la version BLIVA Vicuna, la version Flant5 suit le même format.
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/pretrain_bliva_vicuna.yamltorchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_vicuna.yamlOu bien, nous prenons également en charge la formation de Vicuna7b avec BLIVA en utilisant LoRA au cours de la deuxième étape, par défaut nous n'utilisons pas cette version.
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_and_vicuna.yamlSi vous trouvez BLIVA utile pour vos recherches et applications, veuillez citer en utilisant ce BibTeX :
@misc { hu2023bliva ,
title = { BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions } ,
author = { Wenbo Hu and Yifan Xu and Yi Li and Weiyue Li and Zeyuan Chen and Zhuowen Tu } ,
publisher = { arXiv:2308.09936 } ,
year = { 2023 } ,
}Le code de ce référentiel est sous licence BSD à 3 clauses. De nombreux codes sont basés sur Lavis avec une licence BSD à 3 clauses ici.
Pour nos paramètres de modèle de BLIVA Vicuna Version, il doit être utilisé sous la licence de modèle de LLaMA. Pour le poids du modèle BLIVA FlanT5, il est sous licence Apache 2.0. Pour nos données YTTB-VQA, c'est sous CC BY NC 4.0


