cambrian
1.0.0
Fait intéressant : la vision est apparue chez les animaux au cours de la période cambrienne ! C'est ce qui a inspiré le nom de notre projet, Cambrian.
eval/ pour plus de détails.dataengine/ pour plus de détails.Actuellement, nous prenons en charge la formation sur TPU à l'aide de TorchXLA
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install -e " .[tpu] " pip install torch~=2.2.0 torch_xla[tpu]~=2.2.0 -f https://storage.googleapis.com/libtpu-releases/index.html
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install " .[gpu] " Voici nos points de contrôle cambriens ainsi que des instructions sur la façon d'utiliser les poids. Nos modèles excellent dans diverses dimensions, aux niveaux de paramètres 8B, 13B et 34B. Ils démontrent des performances compétitives par rapport aux modèles propriétaires à source fermée tels que GPT-4V, Gemini-Pro et Grok-1.4V sur plusieurs benchmarks.
| Modèle | # Vis. Tok. | MMB | SQA-I | MathVistaM | GraphiqueQA | MMVP |
|---|---|---|---|---|---|---|
| GPT-4V | UNK | 75,8 | - | 49,9 | 78,5 | 50,0 |
| Gémeaux-1.0 Pro | UNK | 73,6 | - | 45.2 | - | - |
| Gémeaux-1.5 Pro | UNK | - | - | 52.1 | 81,3 | - |
| Grok-1.5 | UNK | - | - | 52,8 | 76.1 | - |
| MM-1-8B | 144 | 72,3 | 72,6 | 35,9 | - | - |
| MM-1-30B | 144 | 75.1 | 81,0 | 39.4 | - | - |
| LLM de base : Phi-3-3.8B | ||||||
| Cambrien-1-8B | 576 | 74,6 | 79.2 | 48.4 | 66,8 | 40,0 |
| LLM de base : LLaMA3-8B-Instruct | ||||||
| Mini-Gémeaux-HD-8B | 2880 | 72,7 | 75.1 | 37,0 | 59.1 | 18.7 |
| LLaVA-NeXT-8B | 2880 | 72.1 | 72,8 | 36.3 | 69,5 | 38,7 |
| Cambrien-1-8B | 576 | 75,9 | 80,4 | 49,0 | 73.3 | 51.3 |
| LLM de base : Vicuna1.5-13B | ||||||
| Mini-Gémeaux-HD-13B | 2880 | 68,6 | 71,9 | 37,0 | 56,6 | 19.3 |
| LLaVA-NeXT-13B | 2880 | 70,0 | 73,5 | 35.1 | 62.2 | 36,0 |
| Cambrien-1-13B | 576 | 75,7 | 79,3 | 48,0 | 73,8 | 41.3 |
| LLM de base : Hermes2-Yi-34B | ||||||
| Mini-Gémeaux-HD-34B | 2880 | 80,6 | 77,7 | 43.4 | 67,6 | 37.3 |
| LLaVA-NeXT-34B | 2880 | 79,3 | 81,8 | 46,5 | 68,7 | 47.3 |
| Cambrien-1-34B | 576 | 81,4 | 85,6 | 53.2 | 75,6 | 52,7 |
Pour le tableau complet, veuillez vous référer à notre article Cambrian-1.
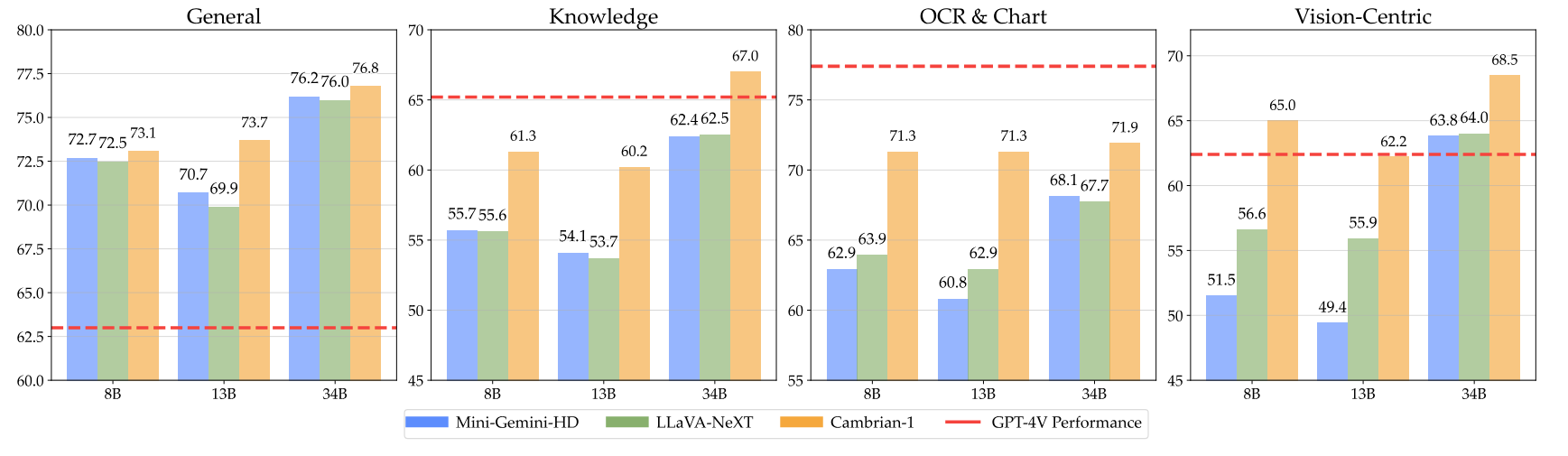
Nos modèles offrent des performances très compétitives tout en utilisant un nombre fixe de jetons visuels plus petit.
Pour utiliser les poids des modèles, téléchargez-les depuis Hugging Face :
Nous fournissons un exemple de script de chargement et de génération de modèle dans inference.py .

Dans ce travail, nous collectons un très grand pool de données de réglage des instructions, Cambrian-10M, pour nous et pour les travaux futurs visant à étudier les données lors de la formation des MLLM. Dans notre étude préliminaire, nous filtrons les données jusqu'à obtenir un ensemble de 7 millions de points de données de haute qualité, que nous appelons Cambrian-7M. Ces deux ensembles de données sont disponibles dans l’ensemble de données Hugging Face suivant : Cambrian-10M.
Nous avons collecté une gamme diversifiée de données de réglage des instructions visuelles provenant de diverses sources, notamment VQA, conversation visuelle et interaction visuelle incarnée. Pour garantir des données de connaissances de haute qualité, fiables et à grande échelle, nous avons conçu un moteur de données Internet.
De plus, nous avons observé que les données VQA ont tendance à générer des résultats très courts, créant un changement de distribution par rapport aux données de formation. Pour résoudre ce problème, nous avons exploité GPT-4v et GPT-4o pour créer des réponses étendues et des données plus créatives.
Pour résoudre l'insuffisance des données scientifiques, nous avons conçu un moteur de données Internet pour collecter des données VQA fiables liées à la science. Ce moteur peut être appliqué pour collecter des données sur n'importe quel sujet. À l'aide de ce moteur, nous avons collecté 161 000 points de données supplémentaires de réglage des instructions visuelles liées à la science, augmentant ainsi le total des données dans ce domaine de 400 % ! Si vous souhaitez utiliser cette partie des données, veuillez utiliser ce jsonl.
Nous avons utilisé GPT-4v pour créer 77 000 points de données supplémentaires. Ces données utilisent GPT-4v pour réécrire le VQA original contenant uniquement des réponses en réponses plus longues avec des réponses plus détaillées ou génèrent des données de réglage des instructions visuelles basées sur l'image donnée. Si vous souhaitez utiliser cette partie des données, veuillez utiliser ce jsonl.
Nous avons utilisé GPT-4o pour créer 60 000 points de données de création supplémentaires. Ces données encouragent le modèle à générer des réponses très longues et contiennent souvent des questions très créatives, comme écrire un poème, composer une chanson, etc. Si vous souhaitez utiliser cette partie des données, veuillez utiliser ce jsonl.
Nous avons mené une première étude sur la curation des données en :
Empiriquement, nous avons constaté que ce paramètre
| Catégorie | Rapport de données |
|---|---|
| Langue | 21,00% |
| Général | 34,52% |
| ROC | 27,22% |
| Compte | 8,71% |
| Mathématiques | 7,20% |
| Code | 0,87% |
| Science | 0,88% |
Par rapport au modèle LLaVA-665K précédent, la mise à l'échelle et l'amélioration de la conservation des données améliorent considérablement les performances du modèle, comme le montre le tableau ci-dessous :
| Modèle | Moyenne | Connaissances générales | ROC | Graphique | Centré sur la vision |
|---|---|---|---|---|---|
| LLaVA-665K | 40.4 | 64,7 | 45.2 | 20,8 | 31,0 |
| Cambrien-10M | 53,8 | 68,7 | 51,6 | 47.1 | 47,6 |
| Cambrien-7M | 54,8 | 69,6 | 52,6 | 47.3 | 49,5 |
Bien que l'entraînement avec Cambrian-7M fournisse des résultats de référence compétitifs, nous avons observé que le modèle a tendance à produire des réponses plus courtes et à agir comme une machine à questions-réponses. Ce comportement, que nous appelons phénomène de « répondeur », peut limiter l'utilité du modèle dans des interactions plus complexes.
Nous avons constaté que l'ajout d'une invite système telle que « Répondez à la question en utilisant un seul mot ou une seule phrase ». peut aider à atténuer le problème. Cette approche encourage le modèle à fournir des réponses aussi concises uniquement lorsque cela est contextuellement approprié. Pour plus de détails, veuillez vous référer à notre article.
Nous avons également organisé un ensemble de données, Cambrian-7M avec invite système, qui inclut l'invite système pour améliorer la créativité et la capacité de discussion du modèle.
Vous trouverez ci-dessous la dernière configuration de formation pour Cambrian-1.
Dans l'article Cambrian-1, nous menons des études approfondies pour démontrer la nécessité d'une formation en deux étapes. La formation Cambrian-1 comprend deux étapes :
Cambrian-1 est formé sur TPU-V4-512 mais peut également être formé sur des TPU à partir de TPU-V4-64. Le code de formation GPU sera bientôt publié. Pour l'entraînement GPU sur moins de GPU, réduisez per_device_train_batch_size et augmentez gradient_accumulation_steps en conséquence, en vous assurant que la taille globale du lot reste la même : per_device_train_batch_size x gradient_accumulation_steps x num_gpus .
Les deux hyperparamètres utilisés dans le pré-entraînement et le réglage fin sont fournis ci-dessous.
| LLM de base | Taille globale du lot | Taux d'apprentissage | Taux d'apprentissage SVA | Époques | Longueur maximale |
|---|---|---|---|---|---|
| LLaMA-3 8B | 512 | 1e-3 | 1e-4 | 1 | 2048 |
| Vigogne-1.5 13B | 512 | 1e-3 | 1e-4 | 1 | 2048 |
| Hermès Yi-34B | 1024 | 1e-3 | 1e-4 | 1 | 2048 |
| LLM de base | Taille globale du lot | Taux d'apprentissage | Époques | Longueur maximale |
|---|---|---|---|---|
| LLaMA-3 8B | 512 | 4e-5 | 1 | 2048 |
| Vigogne-1.5 13B | 512 | 4e-5 | 1 | 2048 |
| Hermès Yi-34B | 1024 | 2e-5 | 1 | 2048 |
Pour affiner l'instruction, nous avons mené des expériences pour déterminer le taux d'apprentissage optimal pour notre formation de modèle. Sur la base de nos conclusions, nous vous recommandons d'utiliser la formule suivante pour ajuster votre taux d'apprentissage en fonction de la disponibilité de votre appareil :
optimal lr = base_lr * sqrt(bs / base_bs)
Pour obtenir le LLM de base et entraîner les modèles 8B, 13B et 34B :
Nous utilisons une combinaison de données d'alignement LLaVA, ShareGPT4V, Mini-Gemini et ALLaVA pour pré-entraîner notre connecteur visuel (SVA). Dans Cambrian-1, nous menons des études approfondies pour démontrer la nécessité et les avantages de l'utilisation de données d'alignement supplémentaires.
Pour commencer, veuillez visiter notre page de données d’alignement du visage câlin pour plus de détails. Vous pouvez télécharger les données d'alignement à partir des liens suivants :
Nous fournissons des exemples de scripts de formation dans :
Si vous souhaitez vous entraîner avec d'autres sources de données ou des données personnalisées, nous prenons en charge le format de données LLaVA couramment utilisé. Pour gérer des fichiers très volumineux, nous utilisons le format JSONL au lieu du format JSON pour le chargement paresseux des données afin d'optimiser l'utilisation de la mémoire.
Semblable à Training SVA, veuillez consulter nos données Cambrian-10M pour plus de détails sur les données de réglage des instructions.
Nous fournissons des exemples de scripts de formation dans :
--mm_projector_type : Pour utiliser notre module SVA, définissez cette valeur sur sva . Pour utiliser le projecteur MLP 2 couches de style LLaVA, définissez cette valeur sur mlp2x_gelu .--vision_tower_aux_list : La liste des modèles de vision à utiliser (par exemple '["siglip/CLIP-ViT-SO400M-14-384", "openai/clip-vit-large-patch14-336", "facebook/dinov2-giant-res378", "clip-convnext-XXL-multi-stage"]' ).--vision_tower_aux_token_len_list : La liste du nombre de jetons de vision pour chaque tour de vision ; chaque nombre doit être un nombre carré (par exemple '[576, 576, 576, 9216]' ). La carte caractéristique de chaque tour de vision sera interpolée pour répondre à cette exigence.--image_token_len : Le nombre final de jetons de vision qui seront fournis à LLM ; le nombre doit être un nombre carré (par exemple 576 ). Notez que si mm_projector_type est mlp, chaque numéro dans vision_tower_aux_token_len_list doit être le même que image_token_len . Les arguments ci-dessous n'ont de sens que pour le projecteur SVA--num_query_group : La valeur G pour le module SVA.--query_num_list : Une liste de numéros de requête pour chaque groupe de requêtes dans SVA (par exemple '[576]' ). La longueur de la liste doit être égale à num_query_group .--connector_depth : La valeur D pour le module SVA.--vision_hidden_size : La taille cachée du module SVA.--connector_only : Si vrai, le module SVA n'apparaîtra qu'avant le LLM, sinon il sera inséré plusieurs fois dans le LLM. Les trois arguments suivants n'ont de sens que lorsque this est défini sur False .--num_of_vision_sampler_layers : Le nombre total de modules SVA insérés dans le LLM.--start_of_vision_sampler_layers : L'index de la couche LLM après lequel l'insertion de SVA commence.--stride_of_vision_sampler_layers : La foulée de l'insertion du module SVA à l'intérieur du LLM. Nous avons publié notre code d'évaluation dans le sous-dossier eval/ . Veuillez consulter le fichier README pour plus de détails.
Les instructions suivantes vous guideront dans le lancement d'une démo Gradio locale avec Cambrian. Nous fournissons une interface Web simple pour vous permettre d'interagir avec le modèle. Vous pouvez également utiliser la CLI pour l'inférence. Cette configuration est fortement inspirée de LLaVA.
Veuillez suivre les étapes ci-dessous pour lancer une démo Gradio locale. Un diagramme du code de desserte local se trouve ci-dessous 1 .
%%{init : {"theme": "base"}}%%
organigramme BT
%% Déclarer les nœuds
style gws fill : #f9f, trait : #333, largeur de trait : 2px
style c remplissage : #bbf, trait : #333, largeur de trait : 2px
style mw8b remplissage : #aff, trait : #333, largeur de trait : 2px
style mw13b remplissage : #aff, trait : #333, largeur de trait : 2px
%% style sglw13b remplissage : #ffa, trait : #333, largeur de trait : 2px
%% style lsglw13b remplissage : #ffa, trait : #333, largeur de trait : 2px
gws["Gradio (serveur d'interface utilisateur)"]
c["Contrôleur (Serveur API) :<br/>PORT : 10000"]
mw8b["Travailleur modèle :<br/><b>Cambrian-1-8B</b><br/>PORT : 40000"]
mw13b["Travailleur modèle :<br/><b>Cambrian-1-13B</b><br/>PORT : 40001"]
%% sglw13b["Backend SGLang :<br/><b>Cambrian-1-34B</b><br/>http://localhost:30000"]
%% lsglw13b["SGLang Worker :<br/><b>Cambrian-1-34B<b><br/>PORT : 40002"]
sous-graphe "Architecture de démonstration"
direction BT
c <--> gws
mw8b <--> c
mw13b <-->c
%% lsglw13b <-->c
%% sglw13b <--> lsglw13b
fin
python -m cambrian.serve.controller --host 0.0.0.0 --port 10000python -m cambrian.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reloadVous venez de lancer l'interface web de Gradio. Maintenant, vous pouvez ouvrir l'interface Web avec l'URL imprimée à l'écran. Vous remarquerez peut-être qu'il n'y a aucun modèle dans la liste des modèles. Ne vous inquiétez pas, car nous n’avons encore lancé aucun modèle de travailleur. Il sera automatiquement mis à jour lorsque vous lancerez un modèle de travail.
À venir.
Il s'agit du véritable travailleur qui effectue l'inférence sur le GPU. Chaque travailleur est responsable d'un seul modèle spécifié dans --model-path .
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bAttendez que le processus ait fini de charger le modèle et que vous voyiez "Uvicorn fonctionnant sur...". Maintenant, actualisez votre interface Web Gradio et vous verrez le modèle que vous venez de lancer dans la liste des modèles.
Vous pouvez lancer autant de travailleurs que vous le souhaitez et comparer différents points de contrôle de modèles dans la même interface Gradio. Veuillez conserver le --controller identique et modifier --port et --worker en un numéro de port différent pour chaque travailleur.
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port < different from 40000, say 40001> --worker http://localhost: < change accordingly, i.e. 40001> --model-path < ckpt 2> Si vous utilisez un appareil Apple avec une puce M1 ou M2, vous pouvez spécifier le périphérique mps en utilisant l'indicateur --device : --device mps .
Si la VRAM de votre GPU est inférieure à 24 Go (par exemple, RTX 3090, RTX 4090, etc.), vous pouvez essayer de l'exécuter avec plusieurs GPU. Notre dernière base de code tentera automatiquement d'utiliser plusieurs GPU si vous disposez de plusieurs GPU. Vous pouvez spécifier les GPU à utiliser avec CUDA_VISIBLE_DEVICES . Vous trouverez ci-dessous un exemple d'exécution avec les deux premiers GPU.
CUDA_VISIBLE_DEVICES=0,1 python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bFAIRE
Si vous trouvez Cambrian utile pour vos recherches et applications, veuillez citer en utilisant ce BibTeX :
@misc { tong2024cambrian1 ,
title = { Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs } ,
author = { Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie } ,
year = { 2024 } ,
eprint = { 2406.16860 } ,
}
Avis d'utilisation et de licence : ce projet utilise certains ensembles de données et points de contrôle qui sont soumis à leurs licences d'origine respectives. Les utilisateurs doivent se conformer à tous les termes et conditions de ces licences originales, y compris, mais sans s'y limiter, les conditions d'utilisation d'OpenAI pour l'ensemble de données et les licences spécifiques pour les modèles de langage de base pour les points de contrôle formés à l'aide de l'ensemble de données (par exemple, licence communautaire Llama pour LLaMA-3, et Vicuna-1.5). Ce projet n'impose aucune contrainte supplémentaire au-delà de celles stipulées dans les licences originales. En outre, il est rappelé aux utilisateurs de s'assurer que leur utilisation de l'ensemble de données et des points de contrôle est conforme à toutes les lois et réglementations applicables.
Copié du diagramme de LLaVA. ↩


