Synonyms
Synonyms
Synonymes chinois pour le traitement et la compréhension du langage naturel.
De meilleurs synonymes chinois : chatbot, boîte à outils intelligente de questions et réponses.
synonyms peuvent être utilisés pour de nombreuses tâches de compréhension du langage naturel : alignement de texte, algorithmes de recommandation, calculs de similarité, décalage sémantique, extraction de mots-clés, extraction de concepts, synthèse automatique, moteurs de recherche, etc.
Afin de fournir des services stables, fiables et optimisés à long terme, Synonyms a changé pour utiliser la licence Chunsong, v1.0 et les frais de téléchargement des modèles d'apprentissage automatique, consultez le magasin de certificats pour plus de détails. Les contributeurs précédents (contributeurs de code avec des contributions exceptionnelles) peuvent nous contacter pour discuter des problèmes de facturation. -- Chatopera Inc. @ octobre 2023
Suivez les étapes ci-dessous pour installer et activer les packages.
pip install -U synonymsLa version stable actuelle est la v3.x.
Le ou les packages de modèles d'apprentissage automatique de Synonyms nécessitent une licence du magasin de licences Chatopera. Achetez d'abord une licence et obtenez l' license id sur la page Licences du magasin de licences Chatopera ( license id : dans le magasin de certificats, sur la page de détails du certificat, cliquez sur [Copier Identité du certificat] ).
Deuxièmement, définissez la variable d'environnement dans votre terminal ou vos scripts shell comme ci-dessous.
par exemple Shell, scripts CMD sous Linux, Windows, macOS.
# Linux / macOS
export SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # e.g. if your license id is `FOOBAR`, run `export SYNONYMS_DL_LICENSE=FOOBAR`
# Windows
# # 1/2 Command Prompt
set SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # 2/2 PowerShell
$env :SYNONYMS_DL_LICENSE= ' YOUR_LICENSE 'Carnet Jupyter, etc.
import os
os . environ [ "SYNONYMS_DL_LICENSE" ] = "YOUR_LICENSE"
_licenseid = os . environ . get ( "SYNONYMS_DL_LICENSE" , None )
print ( "SYNONYMS_DL_LICENSE=" , _licenseid )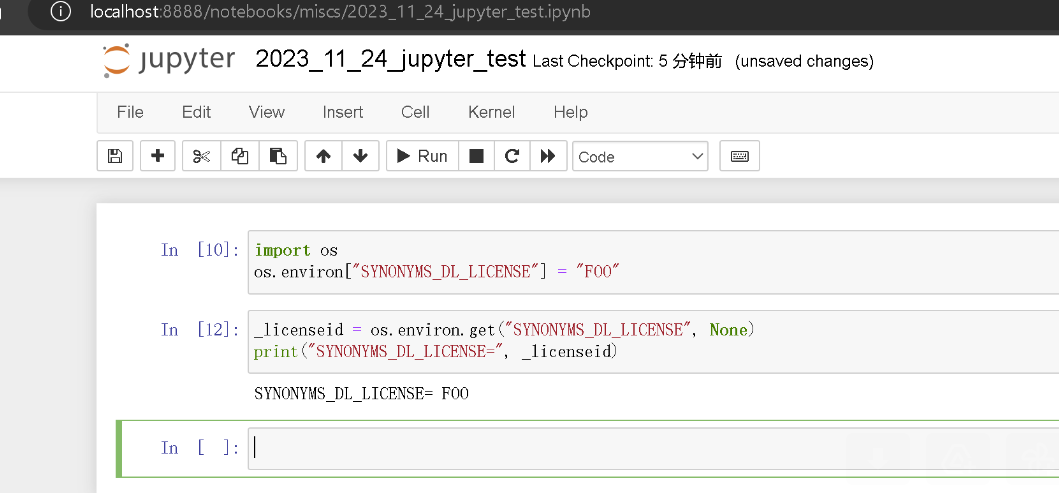
Astuce : Le fichier vectoriel de mots sera téléchargé pour la première fois après l'installation et la vitesse de téléchargement dépend des conditions du réseau.
Enfin, téléchargez le package de modèle par commande ou script -
python -c " import synonyms; synonyms.display('能量') " # download word vectors file 
Prend en charge l'utilisation de variables d'environnement pour configurer le vocabulaire de segmentation de mots et les fichiers vectoriels de mots word2vec.
| variables d'environnement | décrire |
|---|---|
| SYNONYMS_WORD2VEC_BIN_MODEL_ZH_CN | Fichier vectoriel Word formé à l'aide de word2vec, format binaire. |
| SYNONYMS_WORDSEG_DICT | Dictionnaire principal de segmentation de mots chinois, référence de format et d'utilisation |
| SYNONYMS_DEBUG | ["TRUE"|"FALSE"], s'il faut afficher les journaux de débogage, défini sur la sortie "TRUE", la valeur par défaut est "FALSE" |
import synonyms
print ( "人脸: " , synonyms . nearby ( "人脸" ))
print ( "识别: " , synonyms . nearby ( "识别" ))
print ( "NOT_EXIST: " , synonyms . nearby ( "NOT_EXIST" )) synonyms.nearby(WORD [,SIZE]) renvoie un tuple. Le tuple contient deux éléments : ([ nearby_words ([nearby_words], [nearby_words_score]) . distance. Les longueurs sont disposées du proche au lointain, nearby_words_score est le score de la distance entre les mots à la position correspondante dans nearby_words . Le score est dans l'intervalle (0-1), plus il est proche de 1, plus il est SIZE du nombre de mots renvoyés ; la valeur par défaut est 10. Par exemple:
synonyms . nearby (人脸, 10 ) = (
[ "图片" , "图像" , "通过观察" , "数字图像" , "几何图形" , "脸部" , "图象" , "放大镜" , "面孔" , "Mii" ],
[ 0.597284 , 0.580373 , 0.568486 , 0.535674 , 0.531835 , 0.530
095 , 0.525344 , 0.524009 , 0.523101 , 0.516046 ]) En cas d'OOV, ([], []) est renvoyé, taille actuelle du dictionnaire : 435 729.
Comparaison de similarité entre deux phrases
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms . compare ( sen1 , sen2 , seg = True )Parmi eux, le paramètre seg indique si synonyms.compare effectue une segmentation de mots sur sen1 et sen2, et la valeur par défaut est True. Valeur de retour : [0-1], et plus elle est proche de 1, plus les deux phrases sont similaires.
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0 Imprimer les synonymes de manière conviviale pour faciliter le débogage display(WORD [, SIZE]) appelle synonyms#nearby .
>> > synonyms . display ( "飞机" )
'飞机'近义词:
1. 飞机: 1.0
2. 直升机: 0.8423391
3. 客机: 0.8393003
4. 滑翔机: 0.7872388
5. 军用飞机: 0.7832081
6. 水上飞机: 0.77857226
7. 运输机: 0.7724742
8. 航机: 0.7664748
9. 航空器: 0.76592904
10. 民航机: 0.74209654 SIZE est le nombre de listes de vocabulaire imprimées, la valeur par défaut est 10.
Imprimez les informations de description du package actuel :
>>> synonyms.describe()
Vocab size in vector model: 435729
model_path: /Users/hain/chatopera/Synonyms/synonyms/data/words.vector.gz
version: 3.18.0
{'vocab_size': 435729, 'version': '3.18.0', 'model_path': '/chatopera/Synonyms/synonyms/data/words.vector.gz'}
Obtenez un vecteur de mot, qui est un tableau numpy. Lorsque le mot est un mot non enregistré, une exception KeyError est levée.
>> > synonyms . v ( "飞机" )
array ([ - 2.412167 , 2.2628384 , - 7.0214124 , 3.9381874 , 0.8219283 ,
- 3.2809453 , 3.8747153 , - 5.217062 , - 2.2786229 , - 1.2572327 ],
dtype = float32 )Obtenez un vecteur de la phrase après segmentation des mots. Le vecteur est composé en mode BoW.
sentence : 句子是分词后通过空格联合起来
ignore : 是否忽略OOV , False时,随机生成一个向量Segmentation des mots chinois
synonyms . seg ( "中文近义词工具包" )Le résultat de la segmentation des mots est un tuple composé de deux listes, qui sont des mots et des parties de discours correspondantes.
([ '中文' , '近义词' , '工具包' ], [ 'nz' , 'n' , 'n' ])Ce participe ne supprime pas les mots vides et la ponctuation.
Extraire les mots-clés Par défaut, les mots-clés sont extraits en fonction de leur importance.
keywords = synonyms.keywords("9月15日以来,台积电、高通、三星等华为的重要合作伙伴,只要没有美国的相关许可证,都无法供应芯片给华为,而中芯国际等国产芯片企业,也因采用美国技术,而无法供货给华为。目前华为部分型号的手机产品出现货少的现象,若该形势持续下去,华为手机业务将遭受重创。")
Obtenez plus de journaux pour le débogage, définissez la variable d'environnement.
SYNONYMS_DEBUG=TRUE
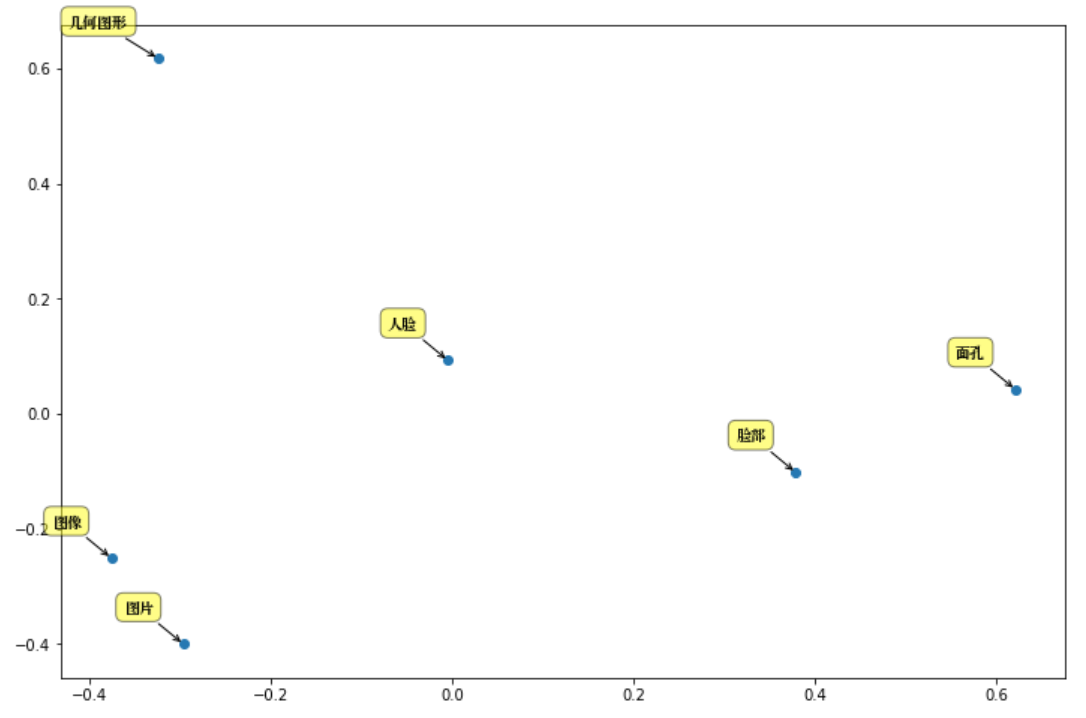
En prenant comme exemple « visage humain » pour analyser les principales composantes :
$ pip install -r Requirements.txt
$ python demo.pyDéclaration de statut mise à jour.
Ce que disent les utilisateurs :
les données sont construites sur la base du corpus wikidata.
"Synonymes Ci Lin" a été compilé par Mei Jiaju et d'autres en 1983. De nos jours, la version largement utilisée est "Synonymes Ci Lin Expanded Edition" maintenue par le Centre de recherche en informatique sociale et en recherche d'informations de l'Institut de technologie de Harbin. Elle divise finement le vocabulaire chinois. en grandes catégories et sous-catégories trient la relation entre les mots. La version étendue de Synonymes Cilin contient plus de 70 000 mots, dont plus de 30 000 sont partagés sous forme de données ouvertes.
HowNet, également connu sous le nom de HowNet, n'est pas seulement un dictionnaire sémantique, mais un système de connaissances. La relation entre les mots est l'un de ses scénarios d'utilisation de base. CNKI contient plus de 8 mots.
La norme internationale d'évaluation des algorithmes de similarité de mots adopte généralement la valeur de jugement manuel de l'ensemble de paires de mots anglais publié par Miller&Charles. L'ensemble de paires de mots se compose de dix paires de paires de mots anglais très liés, dix paires de mots modérément liés et dix paires de paires de mots anglais faiblement liés, puis il est demandé à 38 sujets de juger de la pertinence sémantique de ces 30 paires, et enfin de prendre leur moyenne. la valeur sert de critère manuel. Ensuite, différents outils de synonymes notent également la similarité de ces mots et les comparent à des critères de jugement manuel, comme l'utilisation du coefficient de corrélation de Pearson. Dans le domaine chinois, il est également courant d'utiliser la version traduite de cette liste de vocabulaire pour comparer les synonymes chinois.
La capacité de la liste de vocabulaire des synonymes est de 435 729. Ci-dessous, nous sélectionnons quelques mots qui existent dans les synonymes Cilin, CNKI et Synonymes pour comparer leur similarité :
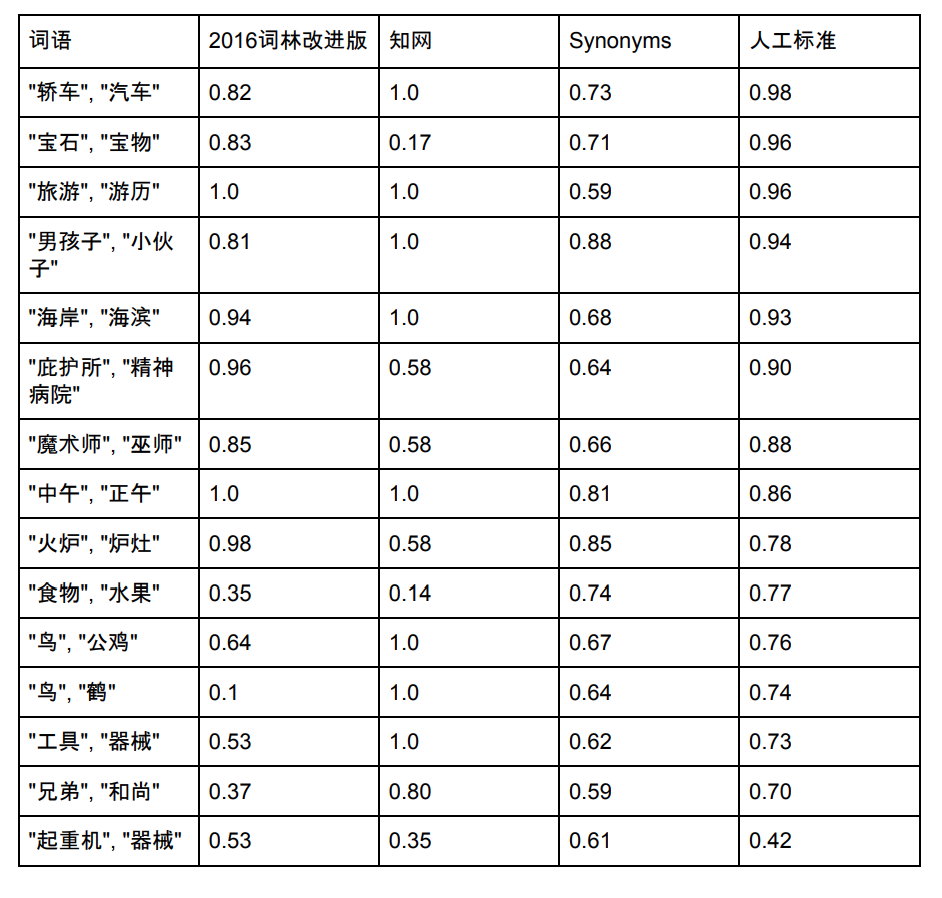
Remarque : Sources des données et scores de Synonym Forest et CNKI. Les synonymes sont également constamment optimisés et les nouveaux scores peuvent ne pas correspondre à l'image ci-dessus.
Plus de résultats de comparaison.
Liste des utilisateurs associés à Github
Testez avec py3, MacBook Pro.
python benchmark.py
++++++++++ Nom et version du système d'exploitation ++++++++++
Plateforme : Darwin
Noyau : 16.7.0
Architecture : ("64 bits", ")
++++++++++ Cœurs de processeur ++++++++++
Noyaux : 4
Charge CPU : 60
++++++++++ Mémoire système ++++++++++
mémoire d'informations 8 Go
synonyms#nearby: 100000 loops, best of 3 epochs: 0.209 usec per loop
52nlp.cn
Cœur de la machine
Enregistrement de partage en ligne : Boîte à outils de synonymes chinois @ 2018-02-07
Synonymes publie le certificat MIT. Les données et procédures peuvent être utilisées dans la recherche et dans des produits commerciaux et doivent être citées et abordées, par exemple dans tous les médias, revues, magazines ou blogs publiés.
@online{Synonyms:hain2017,
author = {Hai Liang Wang, Hu Ying Xi},
title = {中文近义词工具包Synonyms},
year = 2017,
url = {https://github.com/chatopera/Synonyms},
urldate = {2017-09-27}
}
corpus wikidata
Dérivation du principe word2vec et analyse du code
Non pris en charge, voir #5 pour plus d'informations
Word2vec publiée par Google, cette bibliothèque est écrite en langage C, a une efficacité d'utilisation de la mémoire élevée et une vitesse de formation rapide. gensim peut charger les fichiers de modèle générés par word2vec.
Voir #64 pour plus de détails
Hai Liang Wang
Hu Yingxi
Ce livre a été co-écrit par les auteurs de Synonyms.
Lien d'achat rapide du livre 
"Réponse intelligente aux questions et apprentissage profond" Ce livre est destiné aux étudiants et aux ingénieurs logiciels qui se préparent à se lancer dans l'apprentissage automatique et le traitement du langage naturel. Il présente de nombreux principes et algorithmes théoriques et fournit également de nombreux exemples de programmes pour accroître leur praticité. sont résumés dans l'exemple de bibliothèque de codes de programme. Ces programmes sont principalement destinés à aider tout le monde à comprendre les principes et les algorithmes. Vous êtes invités à les télécharger et à les exécuter. L'adresse de la base de code est :
https://github.com/l11x0m7/book-of-qna-code
Word2vec par Google
Wikimédia : source du corpus de formation
gensim : word2vec.py
SentenceSim : Corpus d'évaluation de similarité
jieba : segmentation des mots chinois
Licence publique Chunsong, version 1.0
https://bot.chatopera.com/
Le service cloud Chatopera est un service cloud unique pour la mise en œuvre de robots de chat et est facturé en fonction du nombre d'appels d'interface. Chatopera Cloud Service est une instance Software-as-a-Service de la plateforme de robots Chatopera. Basé sur le cloud computing, le service cloud Chatopera est un service cloud chatbot-as-a-service .
La plate-forme robotique Chatopera comprend des composants tels qu'une base de connaissances, un dialogue multi-tours, une reconnaissance d'intention et une reconnaissance vocale, un développement de robot de chat standardisé et prend en charge des scénarios tels que des questions et réponses intelligentes en OA d'entreprise, des questions et réponses intelligentes en matière de RH, un service client intelligent et un marketing en ligne. Les services informatiques d'entreprise et les services commerciaux utilisent les services cloud Chatopera pour mettre rapidement les chatbots en ligne !


