chat4u
1.0.0
Utilisez les enregistrements de chat WeChat pour former un chatbot qui vous est exclusif.
Les enregistrements de discussion WeChat seront cryptés et stockés dans la base de données sqlite. Vous devez d'abord obtenir la clé de base de données. Vous avez besoin d'un ordinateur portable macOS et votre téléphone mobile peut être Android/iPhone.
git clone https://github.com/nalzok/wechat-decipher-macossudo ./wechat-decipher-macos/macos/dbcracker.d -p $( pgrep WeChat ) | tee dbtrace.logdbtrace.log . sqlcipher '/Users/<user>/Library/Containers/com.tencent.xinWeChat/Data/Library/Application Support/com.tencent.xinWeChat/2.0b4.0.9/5976edc4b2ac64741cacc525f229c5fe/Message/msg_0.db'
--------------------------------------------------------------------------------
PRAGMA key = "x'<384_bit_key>'";
PRAGMA cipher_compatibility = 3;
PRAGMA kdf_iter = 64000;
PRAGMA cipher_page_size = 1024;
........................................
Les utilisateurs d'autres systèmes d'exploitation peuvent essayer les méthodes suivantes, qui ont uniquement été recherchées et non vérifiées, à titre de référence :
EnMicroMsg.db : https://github.com/ppwwyyxx/wechat-dumpEnMicroMsg.db : https://github.com/chg-hou/EnMicroMsg.db-Password-Cracker Sur mon ordinateur portable macOS, les enregistrements de discussion WeChat sont stockés dans msg_0.db - msg_9.db , et seules ces bases de données peuvent être déchiffrées.
Vous devez installer sqlcipher pour que les utilisateurs du système macOS puissent exécuter directement :
brew install sqlcipher Exécutez le script suivant pour analyser automatiquement dbtrace.log , déchiffrer msg_x.db et exporter vers plain_msg_x.db .
python3 decrypt.py Vous pouvez ouvrir la base de données déchiffrée plain_msg_x.db via https://sqliteviewer.app/, trouver la table où se trouvent les enregistrements de discussion dont vous avez besoin, remplir les noms de base de données et de table dans prepare_data.py et exécuter le script suivant pour générer données de formation train.json , la stratégie actuelle est relativement simple, elle ne gère qu'un seul tour de dialogue et fusionnera les dialogues consécutifs en 5 minutes.
python3 prepare_data.pyDes exemples de données d'entraînement sont les suivants :
[
{ "instruction" : "你好" , "output" : "你好" }
{ "instruction" : "你是谁" , "output" : "你猜猜" }
] Préparez une machine Linux avec GPU et scp train.json sur la machine GPU.
J'ai utilisé le LLaMA-7B de réglage fin de l'image complète stanford_alpaca et j'ai entraîné 90 000 données pendant 3 époques sur un V100-SXM2-32 Go à 8 cartes, ce qui n'a pris qu'une heure.
# clone the alpaca repo
git clone https://github.com/tatsu-lab/stanford_alpaca.git && cd stanford_alpaca
# adjust deepspeed config ... such as disabling offloading
vim ./configs/default_offload_opt_param.json
# train with deepspeed zero3
torchrun --nproc_per_node=8 --master_port=23456 train.py
--model_name_or_path huggyllama/llama-7b
--data_path ../train.json
--model_max_length 128
--fp16 True
--output_dir ../llama-wechat
--num_train_epochs 3
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " epoch "
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 10
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 FalseDeepSpeed zero3 enregistrera les poids en tranches, et ils doivent être fusionnés dans un fichier de point de contrôle pytorch :
cd llama-wechat
python3 zero_to_fp32.py . pytorch_model.binSur les cartes graphiques grand public, vous pouvez essayer alpaca-lora. Seul un réglage fin des poids lora peut réduire considérablement les coûts de mémoire graphique et de formation.
Vous pouvez utiliser alpaca-lora pour déployer le frontal dégradé pour le débogage. S'il s'agit d'affiner l'ensemble de l'image, vous devez commenter le code lié à peft et charger uniquement le modèle de base.
git clone https://github.com/tloen/alpaca-lora.git && cd alpaca-lora
CUDA_VISIBLE_DEVICES=0 python3 generate.py --base_model ../llama-wechatEffet de fonctionnement :

Il est nécessaire de déployer un service modèle compatible avec l'API OpenAI. Voici une adaptation simple basée sur llama4openai-api.py Voir llama4openai-api.py dans cet entrepôt pour démarrer le service :
CUDA_VISIBLE_DEVICES=0 python3 llama4openai-api.pyTestez si l'interface est disponible :
curl http://127.0.0.1:5000/chat/completions -v -H " Content-Type: application/json " -H " Authorization: Bearer $OPENAI_API_KEY " --data ' {"model":"llama-wechat","max_tokens":128,"temperature":0.95,"messages":[{"role":"user","content":"你好"}]} 'Utilisez wechat-chatgpt pour accéder à WeChat et remplissez l'adresse de votre service de modèle local pour l'adresse API :
docker run -it --rm --name wechat-chatgpt
-e API=http://127.0.0.1:5000
-e OPENAI_API_KEY= $OPENAI_API_KEY
-e MODEL= " gpt-3.5-turbo "
-e CHAT_PRIVATE_TRIGGER_KEYWORD= " "
-v $( pwd ) /data:/app/data/wechat-assistant.memory-card.json
holegots/wechat-chatgpt:latestEffet de fonctionnement :
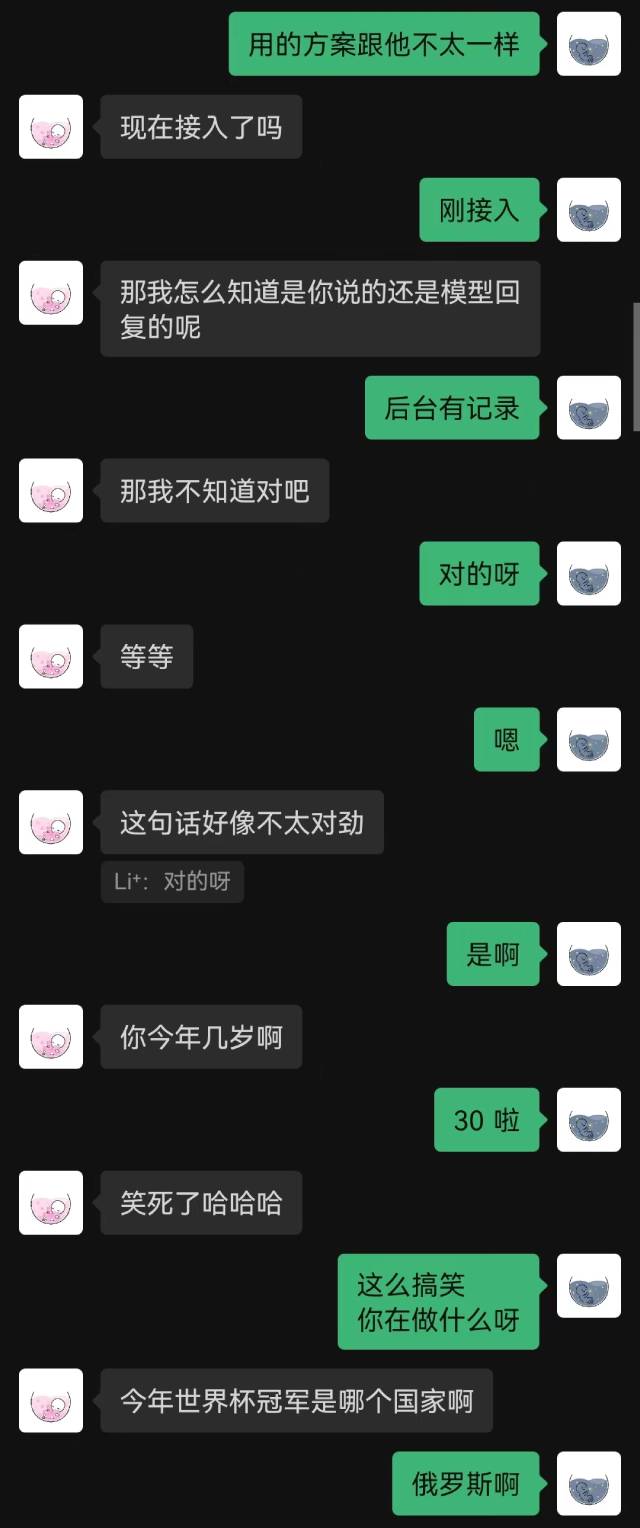 | 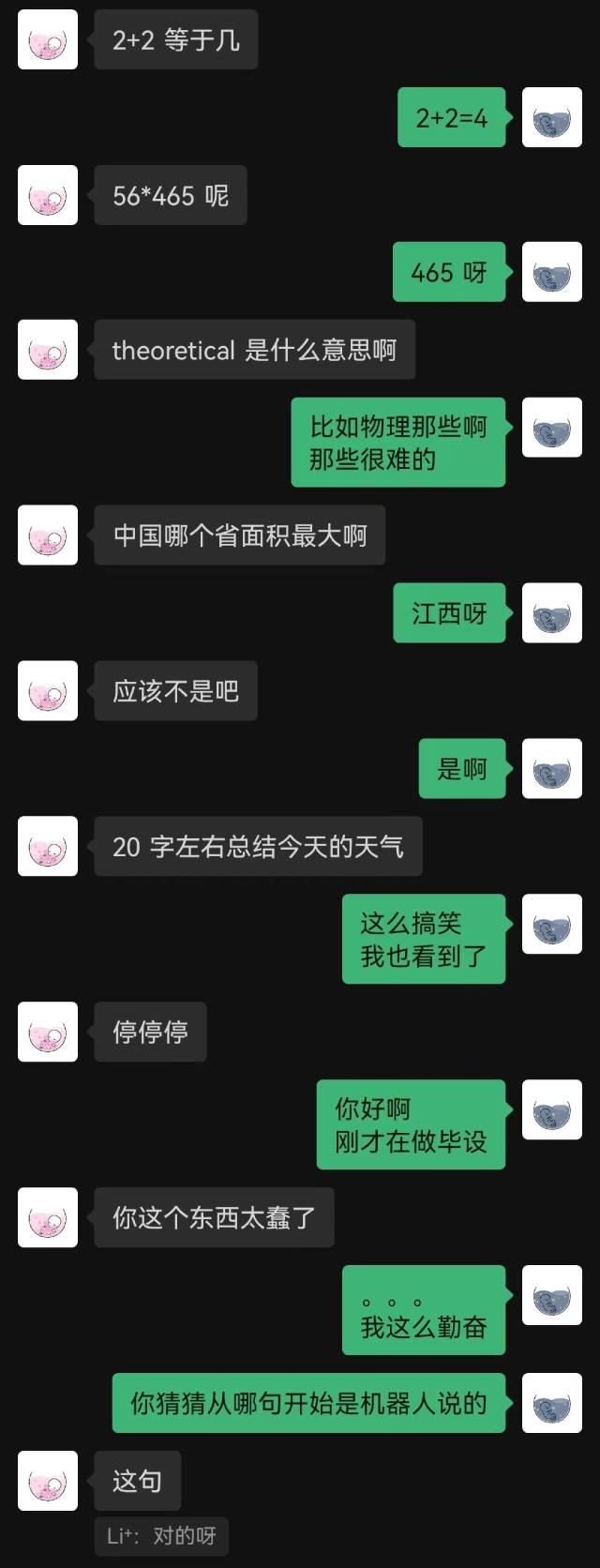 |
|---|
"Je viens de me connecter" a été la première phrase prononcée par le robot, et l'autre partie ne l'a devinée qu'à la fin.
D'une manière générale, les robots formés avec des enregistrements de chat commettreont inévitablement des erreurs de bon sens, mais ils ont mieux imité le style de chat.


