msg_reply
1.0.0
Avez-vous déjà vu ou utilisé Google Smart Reply ? C'est un service qui fournit des suggestions de réponses automatiques aux messages des utilisateurs. Voir ci-dessous.
Il s'agit d'une application utile du chatbot basé sur la récupération. Pensez-y. Combien de fois envoyons-nous un message du type merci , hé ou à plus tard ? Dans ce projet, nous construisons un système simple de suggestion de réponse aux messages.
Parc Kyubyong
Révision du code par Yj Choe
Nous devons définir la liste des suggestions à afficher. Naturellement, la fréquence est considérée en premier. Mais qu’en est-il des phrases dont le sens est similaire ? Par exemple, merci beaucoup et merci d'être traité de manière indépendante ? Nous ne le pensons pas. Nous souhaitons les regrouper et sauvegarder nos créneaux. Comment? Nous utilisons un corpus parallèle. Merci beaucoup et merci seront probablement traduits dans le même texte. Sur la base de cette hypothèse, nous construisons des groupes de synonymes anglais partageant la même traduction.
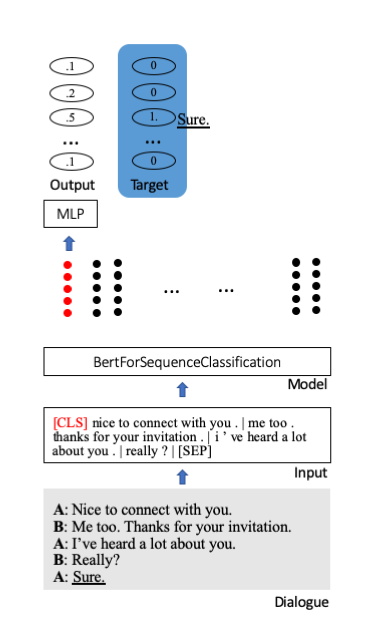
Nous affinons le modèle pré-entraîné de Bert de Huggingface pour la classification des séquences. Dans celui-ci, un jeton de départ spécial [CLS] stocke toutes les informations d'une phrase. Des couches supplémentaires sont attachées pour projeter les informations condensées vers les unités de classification (ici 100).
Nous utilisons le corpus parallèle espagnol-anglais OpenSubtitles 2018 pour construire des groupes de synonymes. OpenSubtitles est une vaste collection de sous-titres de films traduits. Les données en-es se composent de plus de 61 millions de lignes alignées.
Idéalement, un (très) grand corpus de dialogue est nécessaire pour la formation, ce que nous n'avons pas réussi à trouver. Nous utilisons plutôt le Cornell Movie Dialogue Corpus. Il est composé de 83 097 dialogues soit 304 713 lignes.
python>=3.6
tqdm>=4.30.0
pytorche>=1.0
pytorch_pretrained_bert>=0.6.1
nltk>=3.4
ÉTAPE 0. Téléchargez les données parallèles OpenSubtitles 2018 espagnol-anglais.
bash download.sh
ÉTAPE 1. Construisez des groupes de synonymes à partir du corpus.
python construct_sg.py
ÉTAPE 2. Créez les dictionnaires phr2sg_id et sg_id2phr.
python make_phr2sg_id.py
ÉTAPE 3. Convertissez un texte anglais monolingue en identifiants.
python encode.py
ÉTAPE 4. Créez des données d'entraînement et enregistrez-les sous forme de cornichon.
python prepro.py
ÉTAPE 5. Entraînez-vous.
python train.py
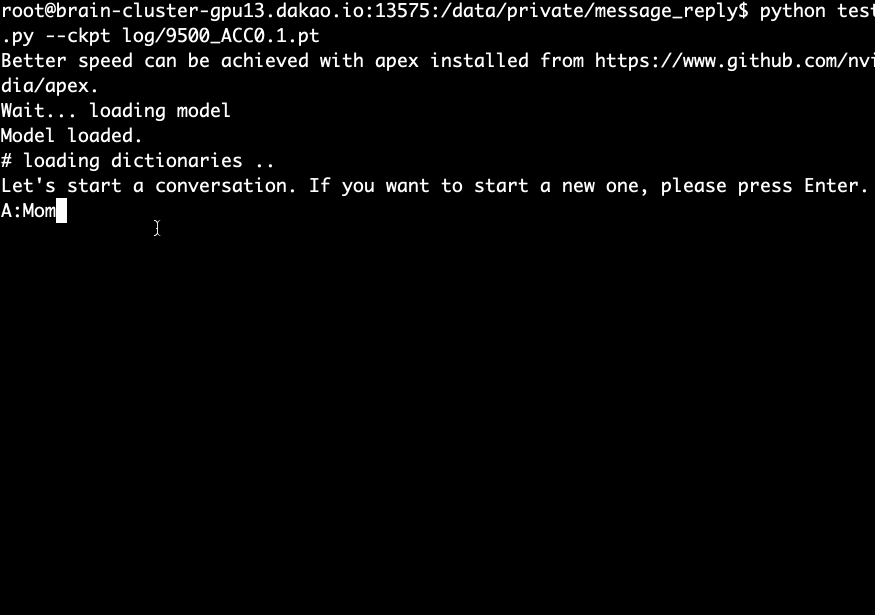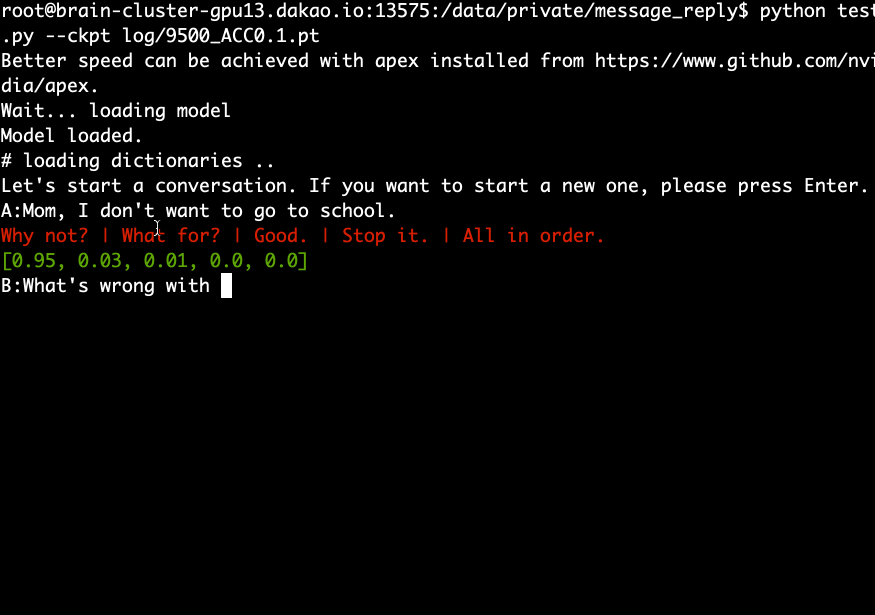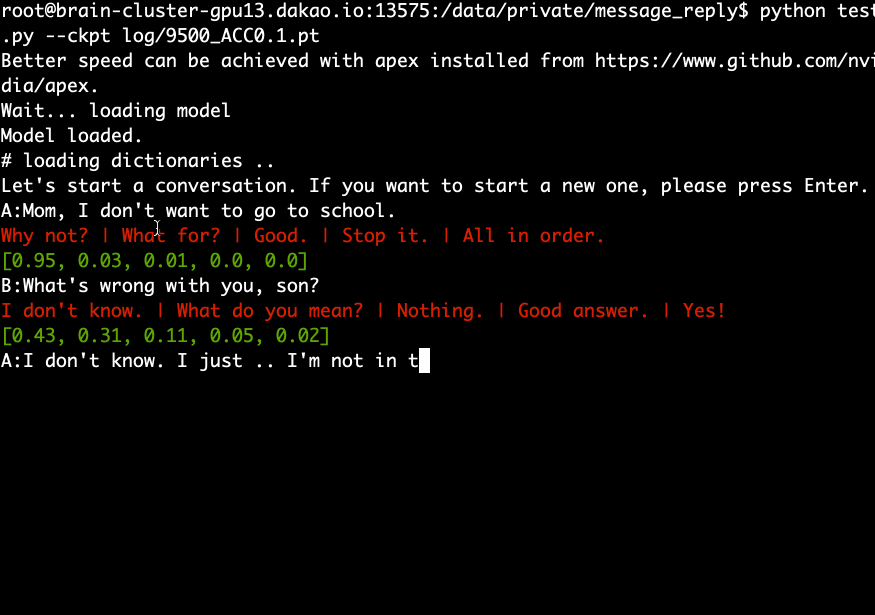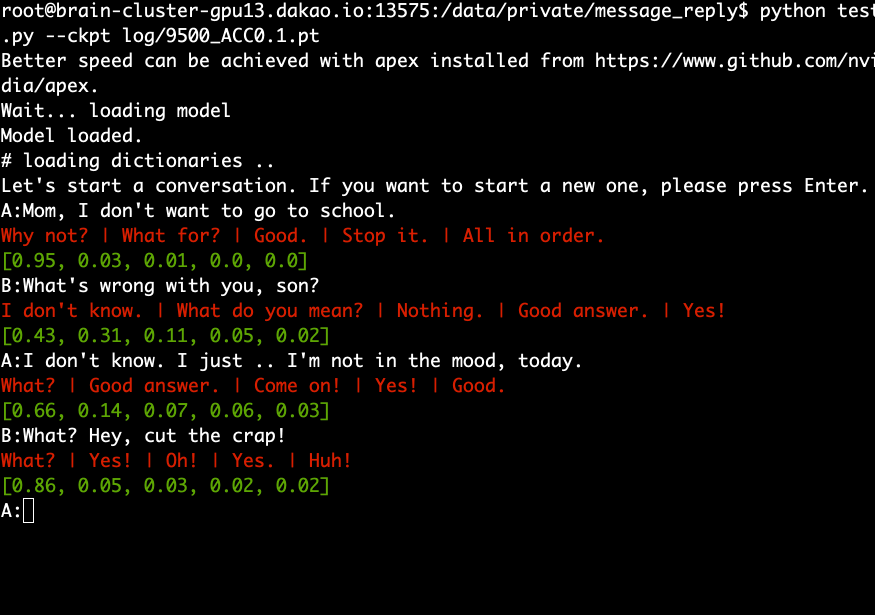
Téléchargez et extrayez le modèle pré-entraîné et exécutez la commande suivante.
python test.py --ckpt log/9500_ACC0.1.pt
La perte d’entraînement diminue lentement mais régulièrement.
La précision@5 sur les données d'évaluation est de 10 à 20 pour cent.
Pour une application réelle, un corpus beaucoup plus vaste est nécessaire.
Je ne sais pas à quel point les scripts de films ressemblent aux dialogues de messages.
Une meilleure stratégie pour construire des groupes de synonymes est nécessaire.
Un chatbot basé sur la récupération est une application réaliste car il est plus sûr et plus simple qu'un chatbot basé sur la génération.


