ThinkRAG
1.0.0
Anglais | Chinois simplifié
Le système de génération d'améliorations de récupération de grands modèles ThinkRAG peut être facilement déployé sur un ordinateur portable pour réaliser des réponses intelligentes aux questions dans une base de connaissances locale.
Le système est construit sur la base de LlamaIndex et Streamlit et a été optimisé pour les utilisateurs nationaux dans de nombreux domaines tels que la sélection de modèles et le traitement de texte.
ThinkRAG est un système d'application de grande taille développé pour les professionnels, les chercheurs, les étudiants et autres travailleurs du savoir. Il peut être utilisé directement sur des ordinateurs portables et les données de la base de connaissances sont enregistrées localement sur l'ordinateur.
ThinkRAG possède les fonctionnalités suivantes :
En particulier, ThinkRAG a également effectué de nombreuses personnalisations et optimisations pour les utilisateurs nationaux :
ThinkRAG peut utiliser tous les modèles pris en charge par la trame de données LlamaIndex. Pour obtenir des informations sur la liste des modèles, veuillez vous référer à la documentation correspondante.
ThinkRAG s'engage à créer un système d'application directement utilisable, utile et facile à utiliser.
C’est pourquoi nous avons fait des choix et des compromis prudents entre différents modèles, composants et technologies.
Premièrement, en utilisant de grands modèles, ThinkRAG prend en charge l'API OpenAI et toutes les API LLM compatibles, y compris les grands fabricants nationaux de grands modèles, tels que :
Si vous souhaitez déployer de grands modèles localement, ThinkRAG choisit Ollama, simple et facile à utiliser. Nous pouvons télécharger de grands modèles pour les exécuter localement via Ollama.
Actuellement, Ollama prend en charge le déploiement localisé de presque tous les grands modèles grand public, notamment Llama, Gemma, GLM, Mistral, Phi, Llava, etc. Pour plus de détails, veuillez visiter le site officiel d'Ollama ci-dessous.
Le système utilise également des modèles intégrés et des modèles réorganisés, et prend en charge la plupart des modèles de Hugging Face. Actuellement, ThinkRAG utilise principalement les modèles de la série BGE de BAAI. Les utilisateurs nationaux peuvent visiter le site Web miroir pour apprendre et télécharger.
Après avoir téléchargé le code depuis Github, utilisez pip pour installer les composants requis.
pip3 install -r requirements.txtPour exécuter le système hors ligne, veuillez d'abord télécharger Ollama depuis le site officiel. Ensuite, utilisez la commande Ollama pour télécharger des modèles volumineux tels que GLM, Gemma et QWen.
De manière synchrone, téléchargez le modèle d'intégration (BAAI/bge-large-zh-v1.5) et le modèle de reclassement (BAAI/bge-reranker-base) de Hugging Face vers le répertoire localmodels.
Pour des étapes spécifiques, veuillez vous référer au document dans le répertoire docs : HowToDownloadModels.md
Afin d’obtenir de meilleures performances, il est recommandé d’utiliser l’API commerciale LLM grand modèle avec des centaines de milliards de paramètres.
Tout d’abord, obtenez la clé API auprès du fournisseur de services LLM et configurez les variables d’environnement suivantes.
ZHIPU_API_KEY = " "
MOONSHOT_API_KEY = " "
DEEPSEEK_API_KEY = " "
OPENAI_API_KEY = " "Vous pouvez ignorer cette étape et configurer la clé API via l'interface de l'application une fois le système exécuté.
Si vous choisissez d'utiliser une ou plusieurs API LLM, veuillez supprimer le fournisseur de services que vous n'utilisez plus dans le fichier de configuration config.py.
Bien entendu, vous pouvez également ajouter d'autres fournisseurs de services compatibles avec l'API OpenAI dans le fichier de configuration.
ThinkRAG s'exécute en mode développement par défaut. Dans ce mode, le système utilise le stockage de fichiers local et vous n'avez pas besoin d'installer de base de données.
Pour passer en mode production, vous pouvez configurer les variables d'environnement comme suit.
THINKRAG_ENV = productionEn mode production, le système utilise la base de données vectorielles Chroma et la base de données clé-valeur Redis.
Si Redis n'est pas installé, il est recommandé de l'installer via Docker ou d'utiliser une instance Redis existante. Veuillez configurer les informations sur les paramètres de l'instance Redis dans le fichier config.py.
Vous êtes maintenant prêt à exécuter ThinkRAG.
Veuillez exécuter la commande suivante dans le répertoire contenant le fichier app.py.
streamlit run app.pyLe système s'exécutera et ouvrira automatiquement l'URL suivante sur le navigateur pour afficher l'interface de l'application.
http://localhost:8501/
La première exécution peut prendre un certain temps. Si le modèle intégré sur Hugging Face n'est pas téléchargé à l'avance, le système téléchargera automatiquement le modèle et vous devrez attendre plus longtemps.
ThinkRAG prend en charge la configuration et la sélection de grands modèles dans l'interface utilisateur, y compris l'URL de base et la clé API de l'API LLM des grands modèles, et vous pouvez sélectionner le modèle spécifique à utiliser, tel que glm-4 de ThinkRAG.
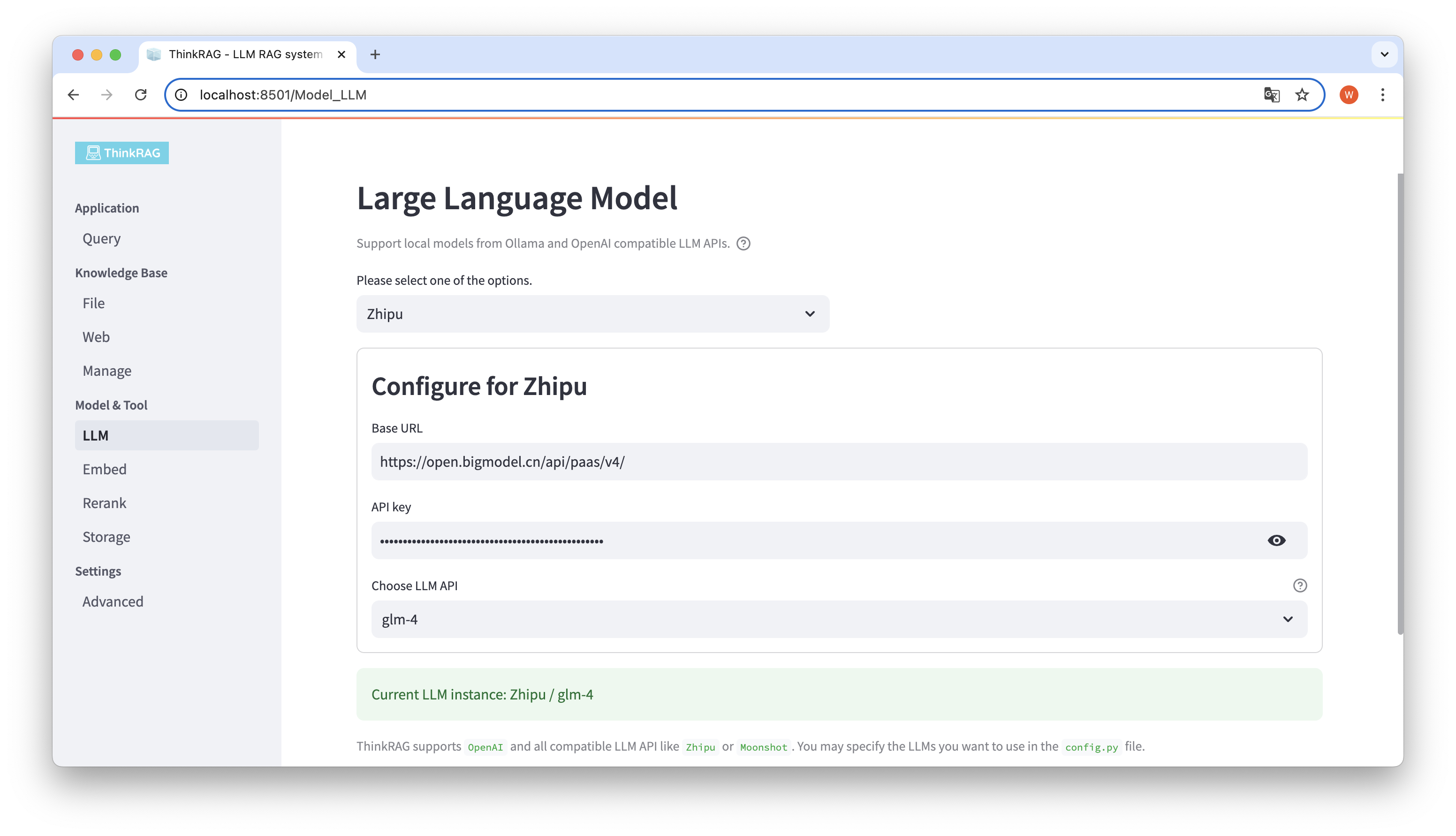
Le système détectera automatiquement si l'API et la clé sont disponibles. Si elles sont disponibles, la grande instance de modèle actuellement sélectionnée sera affichée en texte vert en bas.
De même, le système peut obtenir automatiquement les modèles téléchargés par Ollama, et l'utilisateur peut sélectionner le modèle souhaité sur l'interface utilisateur.
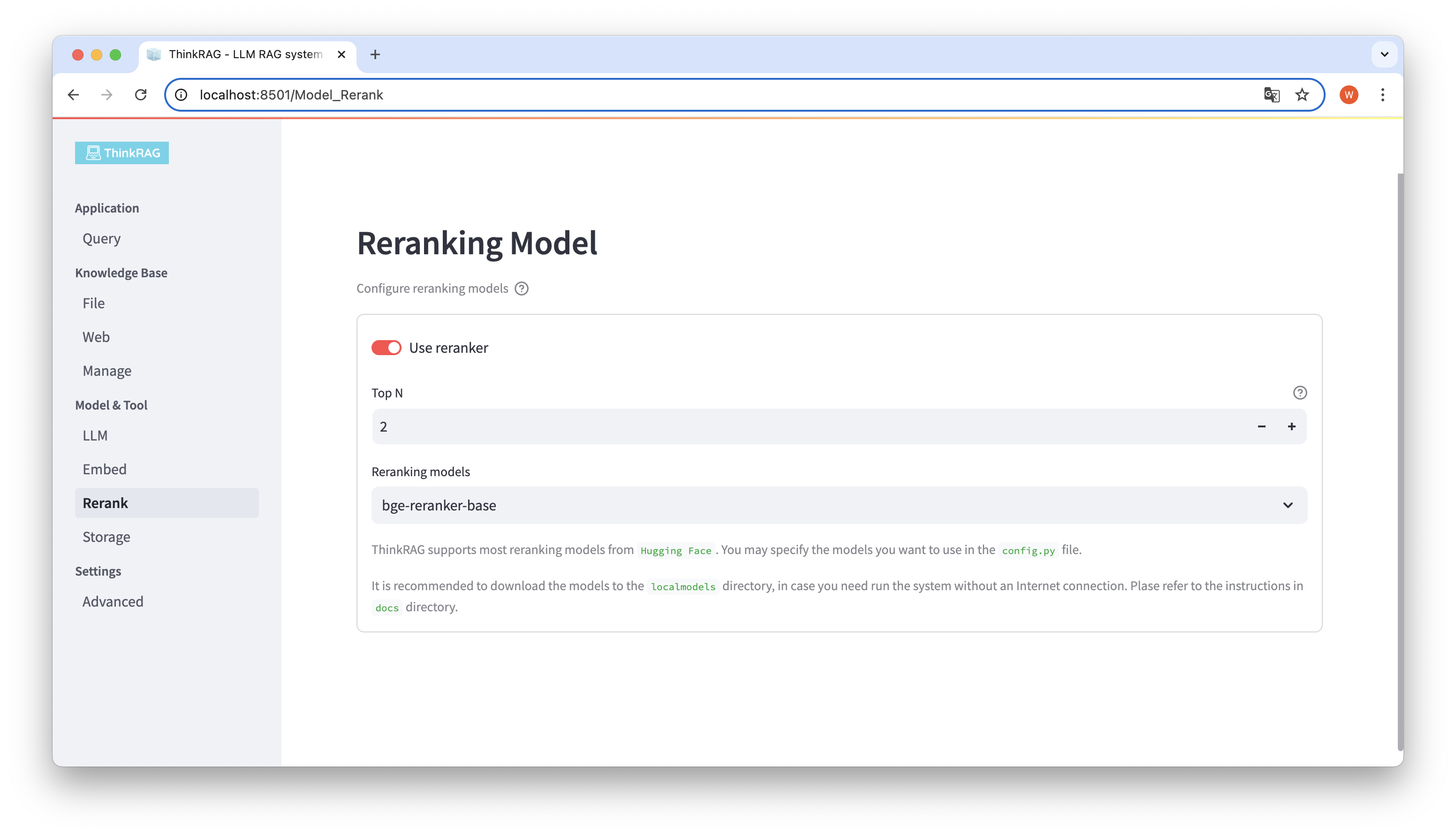
Si vous avez téléchargé le modèle intégré et réorganisé le modèle dans le répertoire local localmodels. Sur l'interface utilisateur, vous pouvez changer le modèle sélectionné et définir les paramètres du modèle réorganisé, tel que Top N.
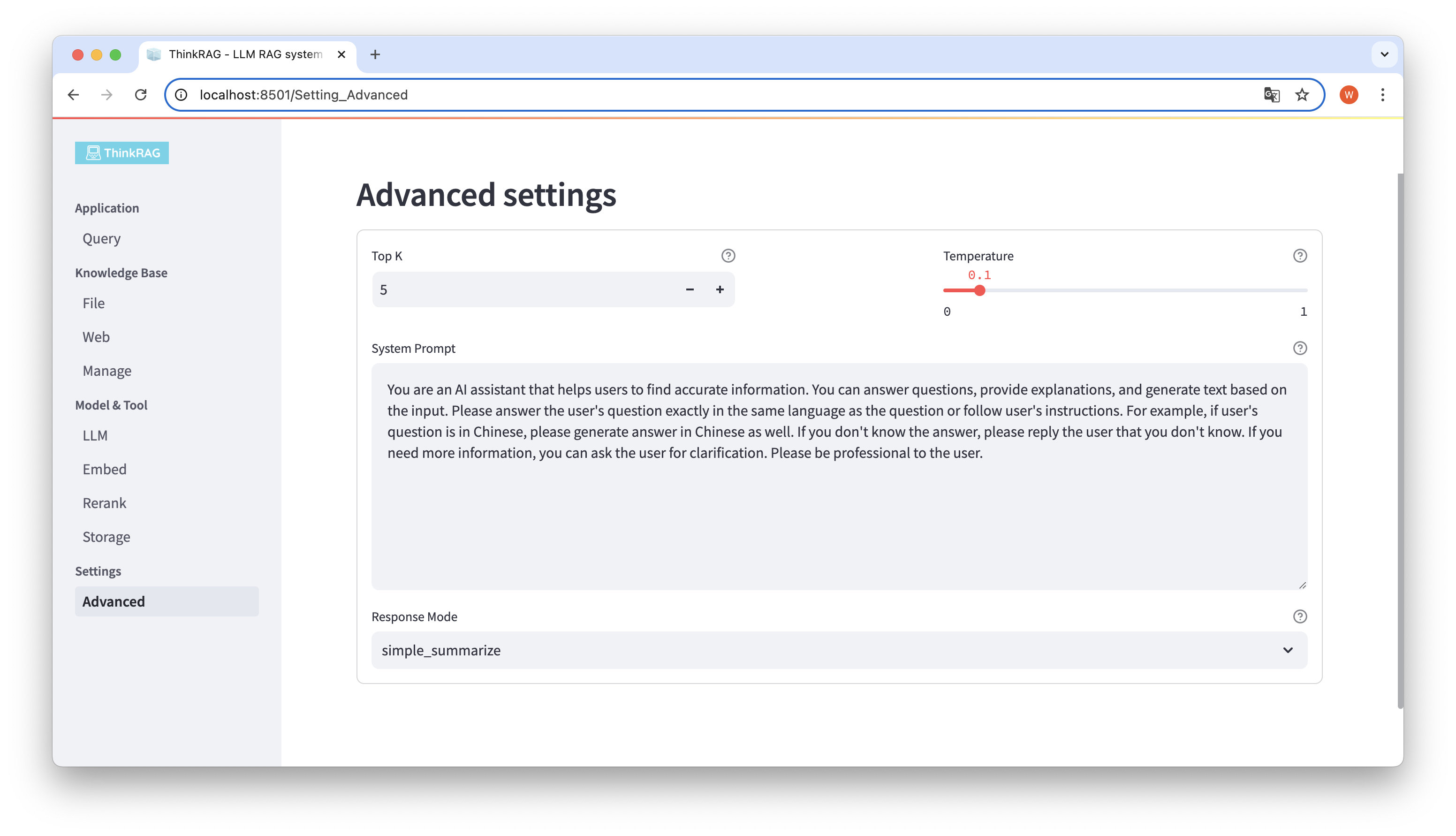
Dans la barre de navigation de gauche, cliquez sur Paramètres avancés (Paramètres-Avancé). Vous pouvez également définir les paramètres suivants :
En utilisant différents paramètres, nous pouvons comparer les résultats de grands modèles et trouver la combinaison de paramètres la plus efficace.
ThinkRAG prend en charge le téléchargement de divers fichiers tels que PDF, DOCX, PPTX, etc., ainsi que le téléchargement d'URL de pages Web.
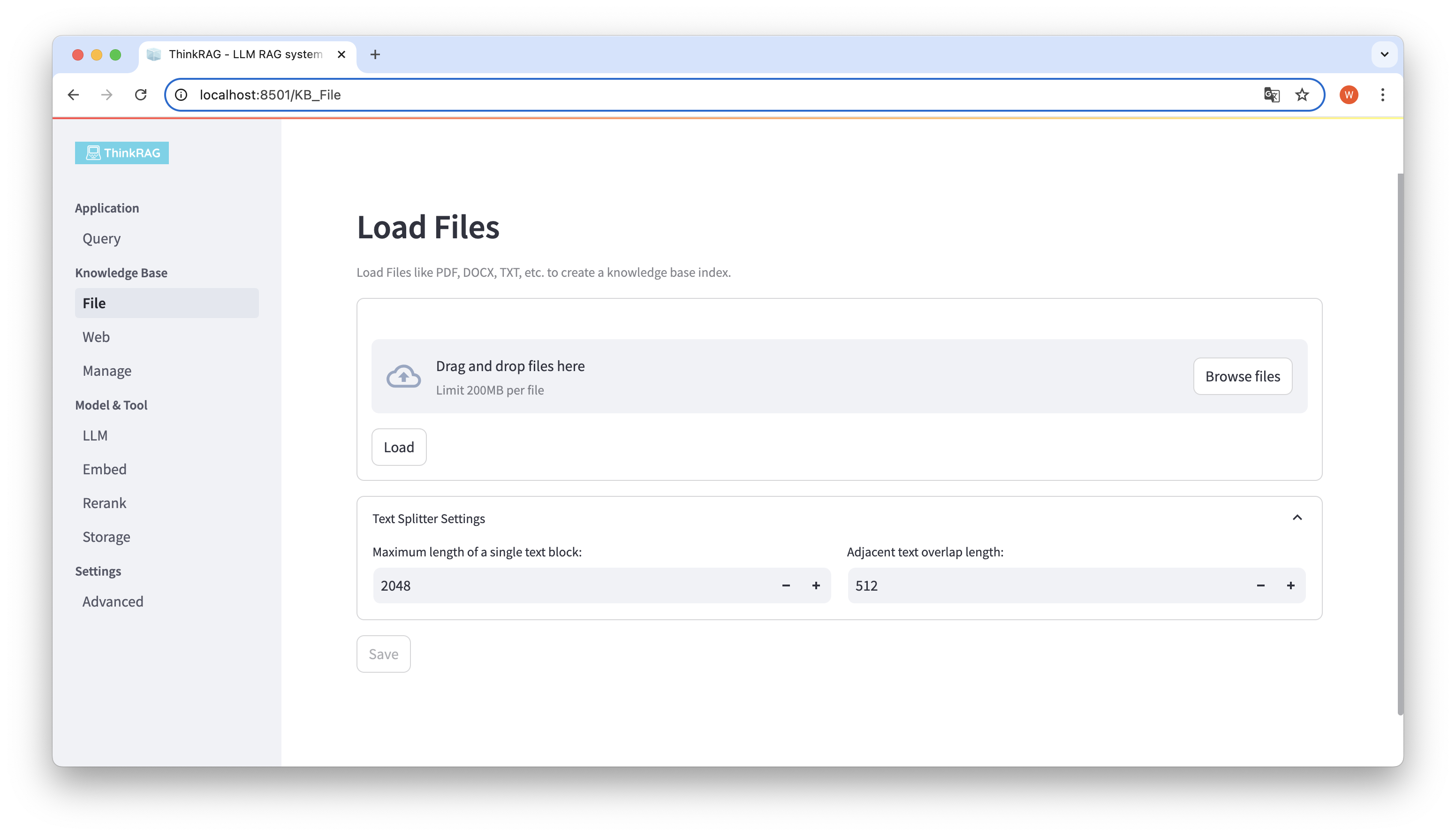
Cliquez sur le bouton Parcourir les fichiers, sélectionnez le fichier sur votre ordinateur, puis cliquez sur le bouton Charger pour charger. Tous les fichiers chargés seront répertoriés.
Ensuite, cliquez sur le bouton Enregistrer et le système traitera le fichier, y compris la segmentation et l'intégration du texte, et l'enregistrera dans la base de connaissances.
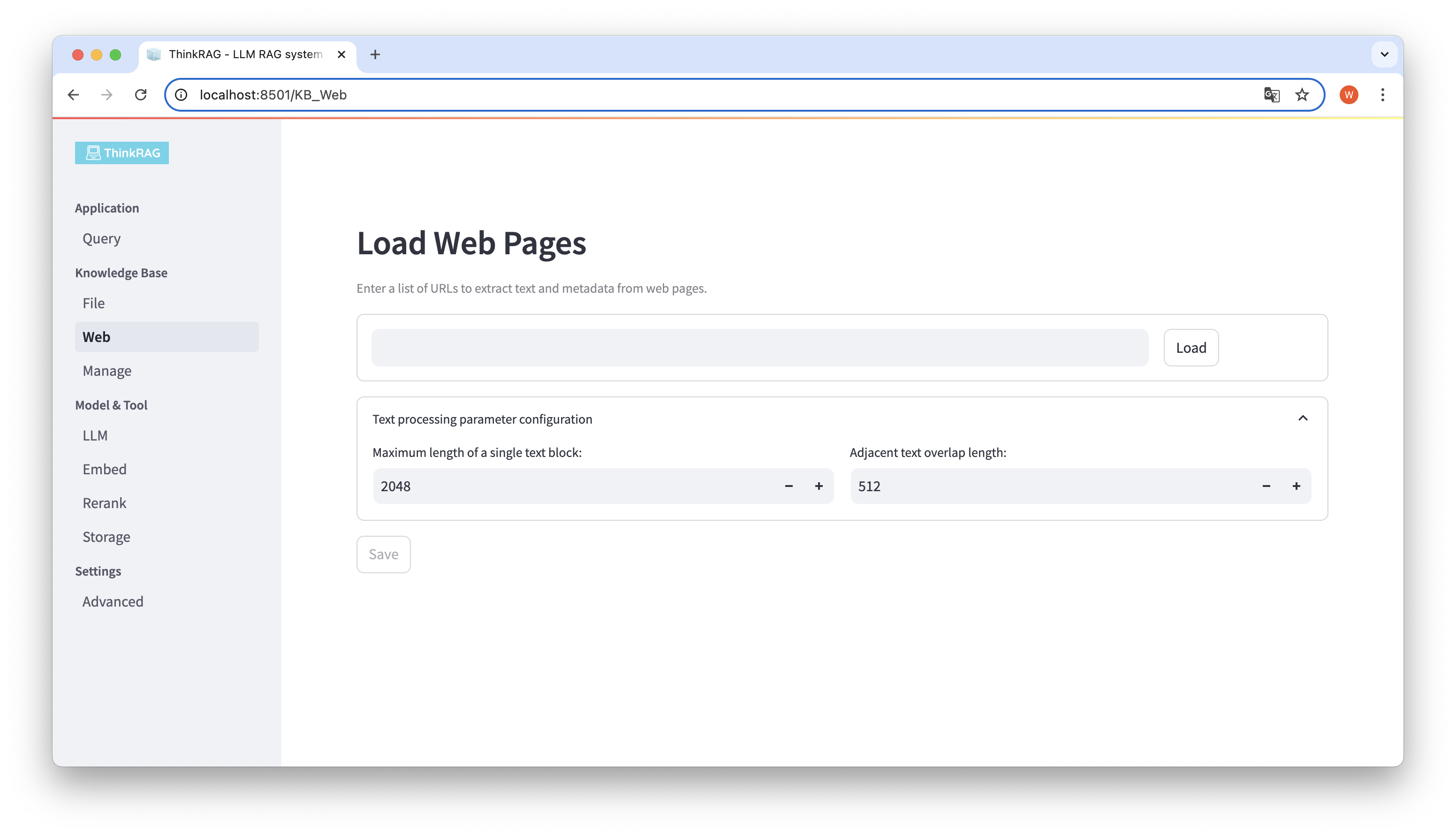
De même, vous pouvez saisir ou coller l'URL de la page Web, obtenir les informations de la page Web et les enregistrer dans la base de connaissances après le traitement.
Le système prend en charge la gestion de la base de connaissances.
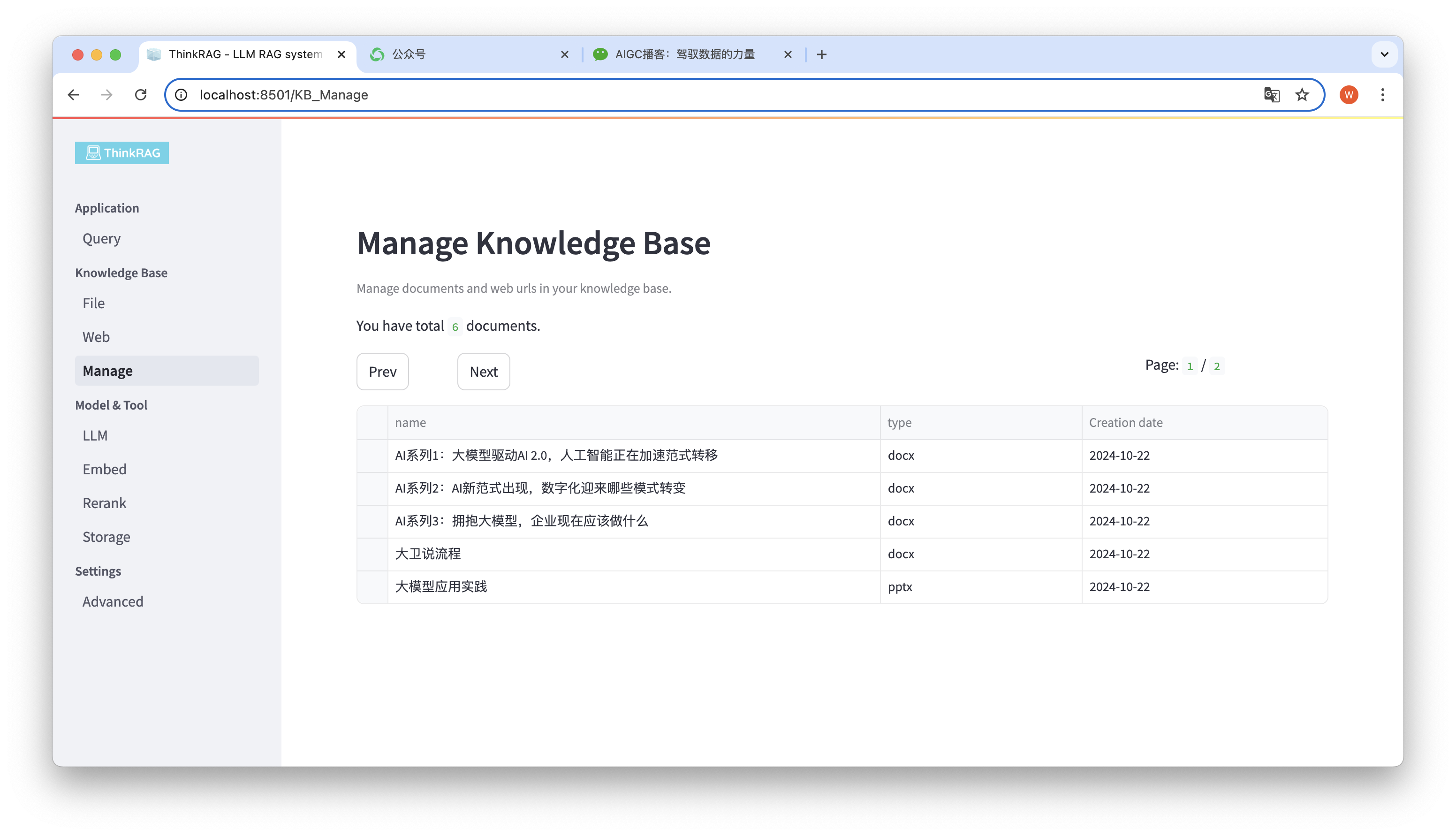
Comme le montre la figure ci-dessus, ThinkRAG peut répertorier tous les documents de la base de connaissances en pages.
Sélectionnez les documents à supprimer et le bouton Supprimer les documents sélectionnés apparaîtra. Cliquez sur ce bouton pour supprimer les documents de la base de connaissances.
Dans la barre de navigation de gauche, cliquez sur Requête et la page intelligente de questions et réponses apparaîtra.
Après avoir saisi la question, le système recherchera dans la base de connaissances et fournira une réponse. Au cours de ce processus, le système utilisera des technologies telles que la récupération hybride et le réarrangement pour obtenir un contenu précis à partir de la base de connaissances.
Par exemple, nous avons mis en ligne un document Word dans la base de connaissances : « David Says Process.docx ».
Posez maintenant la question : « Quelles sont les trois caractéristiques d’un processus ? »
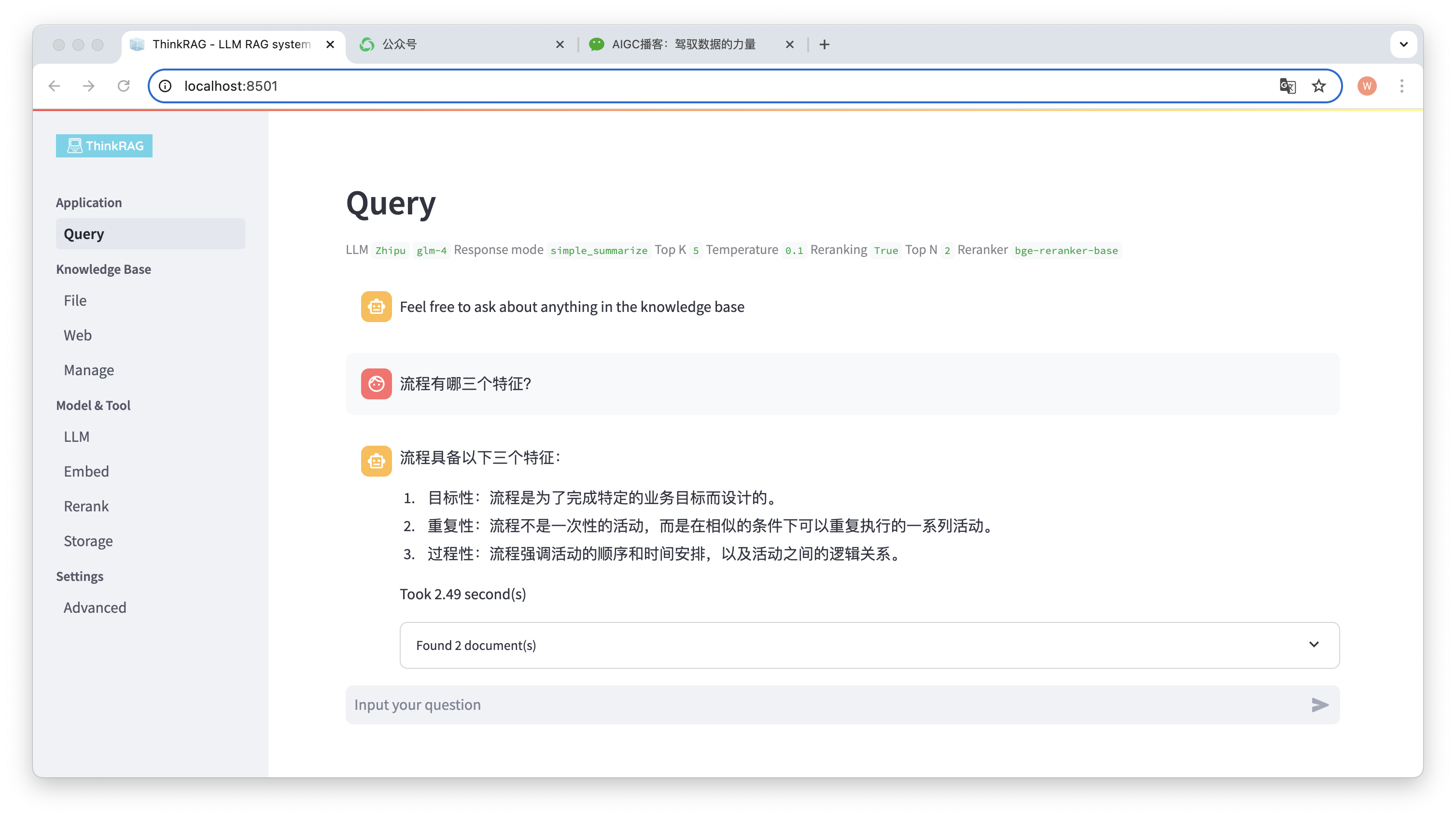
Comme le montre la figure, le système a mis 2,49 secondes pour donner une réponse précise : le processus est ciblé, répétitif et procédural. Parallèlement, le système fournit également 2 documents associés extraits de la base de connaissances.
On peut voir que ThinkRAG implémente complètement et efficacement la fonction de génération améliorée de récupération de grands modèles basée sur la base de connaissances locale.
ThinkRAG est développé à l'aide du framework de données LlamaIndex et utilise Streamlit pour le front-end. Le mode de développement et le mode de production du système utilisent respectivement des composants techniques différents, comme indiqué dans le tableau suivant :
| mode de développement | mode de fabrication | |
|---|---|---|
| Cadre RAG | LamaIndex | LamaIndex |
| cadre frontal | Rationalisé | Rationalisé |
| modèle embarqué | BAAI/bge-small-zh-v1.5 | BAAI/bge-large-zh-v1.5 |
| réorganiser le modèle | BAAI/bge-reranker-base | BAAI/bge-reranker-large |
| séparateur de texte | Séparateur de phrases | SpacyTextSplitter |
| Stockage des conversations | SimpleChatStore | Rédis |
| Stockage de documents | SimpleDocumentStore | Rédis |
| Stockage d'index | SimpleIndexStore | Rédis |
| stockage vectoriel | SimpleVectorStore | LanceDB |
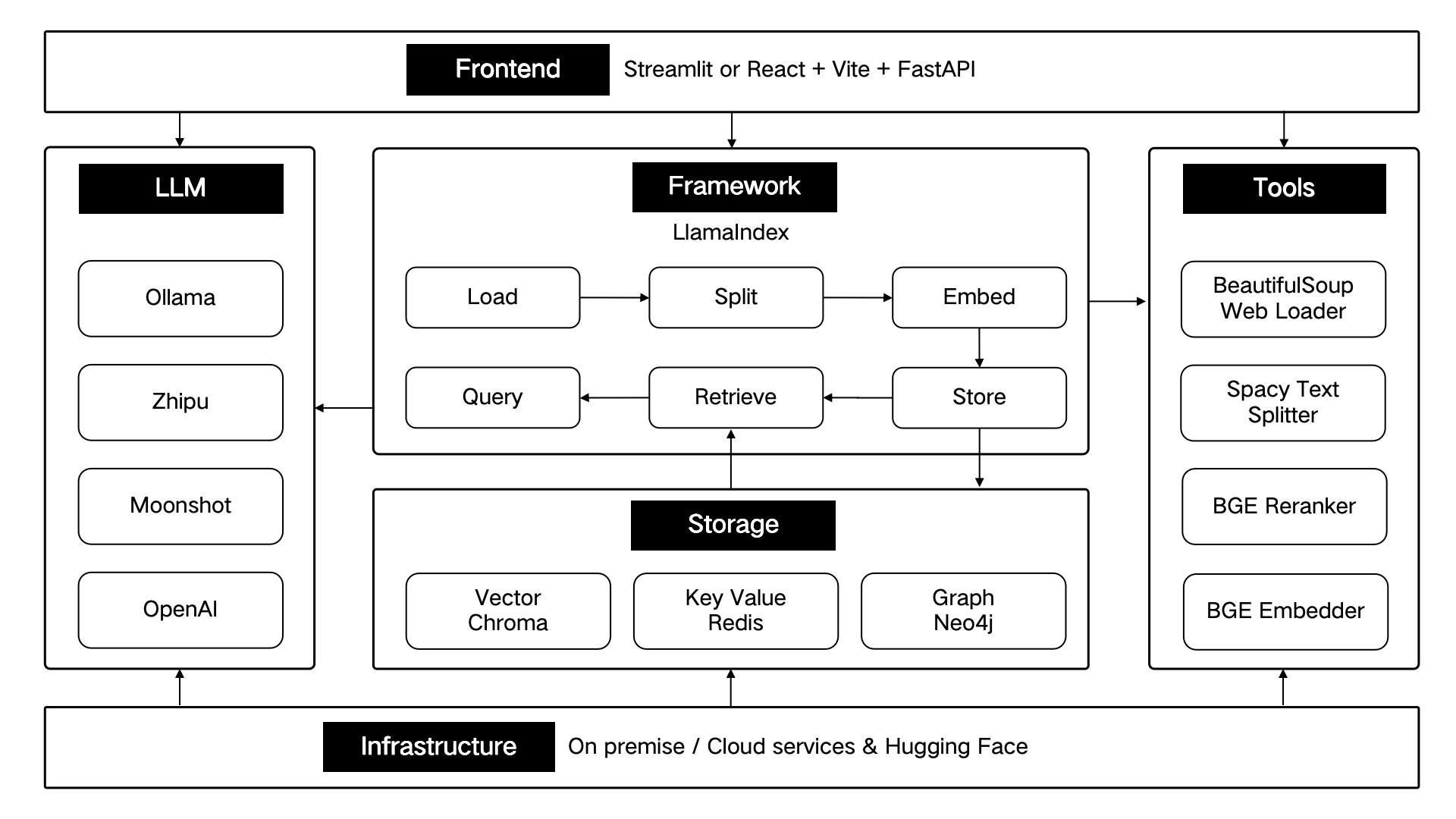
Ces composants techniques sont conçus architecturalement selon six parties : front-end, framework, grand modèle, outils, stockage et infrastructure.
Comme indiqué ci-dessous :
ThinkRAG continuera d'optimiser les fonctions de base et d'améliorer l'efficacité et la précision de la récupération, notamment :
Dans le même temps, nous améliorerons encore l’architecture des applications et améliorerons l’expérience utilisateur, notamment :
Vous êtes invités à rejoindre le projet open source ThinkRAG et à travailler ensemble pour créer des produits d'IA que les utilisateurs adorent !
ThinkRAG utilise la licence MIT.


