pathway
v0.16.0
Commencer | Déploiement | Documentation et assistance | Blogue | Licence
Pathway est un framework Python ETL pour le traitement de flux, l'analyse en temps réel, les pipelines LLM et RAG.
Pathway est livré avec une API Python facile à utiliser , vous permettant d'intégrer de manière transparente vos bibliothèques Python ML préférées. Le code Pathway est polyvalent et robuste : vous pouvez l'utiliser à la fois dans des environnements de développement et de production, en gérant efficacement les données par lots et en streaming . Le même code peut être utilisé pour le développement local, les tests CI/CD, l'exécution de tâches par lots, la gestion des rediffusions de flux et le traitement des flux de données.
Pathway est alimenté par un moteur Rust évolutif basé sur Differential Dataflow et effectue des calculs incrémentiels. Votre code Pathway, bien qu'il soit écrit en Python, est exécuté par le moteur Rust, permettant le multithreading, le multitraitement et les calculs distribués. Tout le pipeline est conservé en mémoire et peut être facilement déployé avec Docker et Kubernetes .
Vous pouvez installer Pathway avec pip :
pip install -U pathway
Pour toute question, vous retrouverez la communauté et l'équipe derrière le projet sur Discord.
Prêt à voir ce que Pathway peut faire ?
Essayez l'un de nos exemples faciles à exécuter !
Disponibles au format notebook et docker, ces exemples prêts à l'emploi peuvent être lancés en quelques clics seulement. Choisissez-en un et commencez votre expérience pratique avec Pathway dès aujourd'hui !
Avec son moteur unifié pour le batch et le streaming et sa compatibilité totale avec Python, Pathway rend le traitement des données aussi simple que possible. Il s'agit de la solution idéale pour une large gamme de pipelines de traitement de données, notamment :
Pathway fournit des outils LLM dédiés pour créer des pipelines LLM et RAG en direct. Des wrappers pour les services et utilitaires LLM les plus courants sont inclus, ce qui rend le travail avec les pipelines LLM et RAG incroyablement facile. Consultez notre documentation LLM xpack.
N'hésitez pas à essayer l'un de nos exemples exécutables comportant les outils LLM. Vous pouvez trouver de tels exemples ici.
Pathway nécessite Python 3.10 ou supérieur.
Vous pouvez installer la version actuelle de Pathway en utilisant pip :
$ pip install -U pathway
import pathway as pw
# Define the schema of your data (Optional)
class InputSchema ( pw . Schema ):
value : int
# Connect to your data using connectors
input_table = pw . io . csv . read (
"./input/" ,
schema = InputSchema
)
#Define your operations on the data
filtered_table = input_table . filter ( input_table . value >= 0 )
result_table = filtered_table . reduce (
sum_value = pw . reducers . sum ( filtered_table . value )
)
# Load your results to external systems
pw . io . jsonlines . write ( result_table , "output.jsonl" )
# Run the computation
pw . run ()Exécutez Pathway dans Google Colab.
Vous pouvez trouver plus d’exemples ici.
Pour utiliser Pathway, il vous suffit de l'importer :
import pathway as pwDésormais, vous pouvez facilement créer votre pipeline de traitement et laisser Pathway gérer les mises à jour. Une fois votre pipeline créé, vous pouvez lancer le calcul sur les données en streaming avec une commande sur une seule ligne :
pw . run () Vous pouvez ensuite exécuter votre projet Pathway (par exemple, main.py ) comme un script Python normal : $ python main.py . Pathway est livré avec un tableau de bord de surveillance qui vous permet de suivre le nombre de messages envoyés par chaque connecteur et la latence du système. Le tableau de bord comprend également les messages de journal.
Alternativement, vous pouvez utiliser la version Path'ish :
$ pathway spawn python main.py
Pathway prend en charge nativement le multithreading. Pour lancer votre application avec 3 threads, vous pouvez procéder comme suit :
$ pathway spawn --threads 3 python main.py
Pour lancer un projet Pathway, vous pouvez utiliser notre modèle à l'emporte-pièce.
Vous pouvez facilement exécuter Pathway à l’aide de Docker.
Vous pouvez utiliser l'image Docker Pathway à l'aide d'un Dockerfile :
FROM pathwaycom/pathway:latest
WORKDIR /app
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD [ "python" , "./your-script.py" ]Vous pouvez ensuite créer et exécuter l'image Docker :
docker build -t my-pathway-app .
docker run -it --rm --name my-pathway-app my-pathway-app Lorsqu'il s'agit de projets à fichier unique, la création d'un Dockerfile à part entière peut sembler inutile. Dans de tels scénarios, vous pouvez exécuter un script Python directement à l'aide de l'image Pathway Docker. Par exemple:
docker run -it --rm --name my-pathway-app -v "$PWD":/app pathwaycom/pathway:latest python my-pathway-app.py Vous pouvez également utiliser une image Python standard et installer Pathway en utilisant pip avec un Dockerfile :
FROM --platform=linux/x86_64 python:3.10
RUN pip install -U pathway
COPY ./pathway-script.py pathway-script.py
CMD [ "python" , "-u" , "pathway-script.py" ]Les conteneurs Docker sont parfaitement adaptés au déploiement sur le cloud avec Kubernetes. Si vous souhaitez faire évoluer votre application Pathway, vous pourriez être intéressé par notre Pathway for Enterprise. Pathway for Enterprise est spécialement conçu pour le traitement des données de bout en bout et l'analyse intelligente en temps réel. Il évolue grâce à l'informatique distribuée sur le cloud et prend en charge le déploiement distribué de Kubernetes, avec une configuration de persistance externe.
Vous pouvez facilement déployer Pathway à l'aide de services comme Render : découvrez comment déployer Pathway en quelques clics.
Si vous êtes intéressé, n'hésitez pas à nous contacter pour en savoir plus.
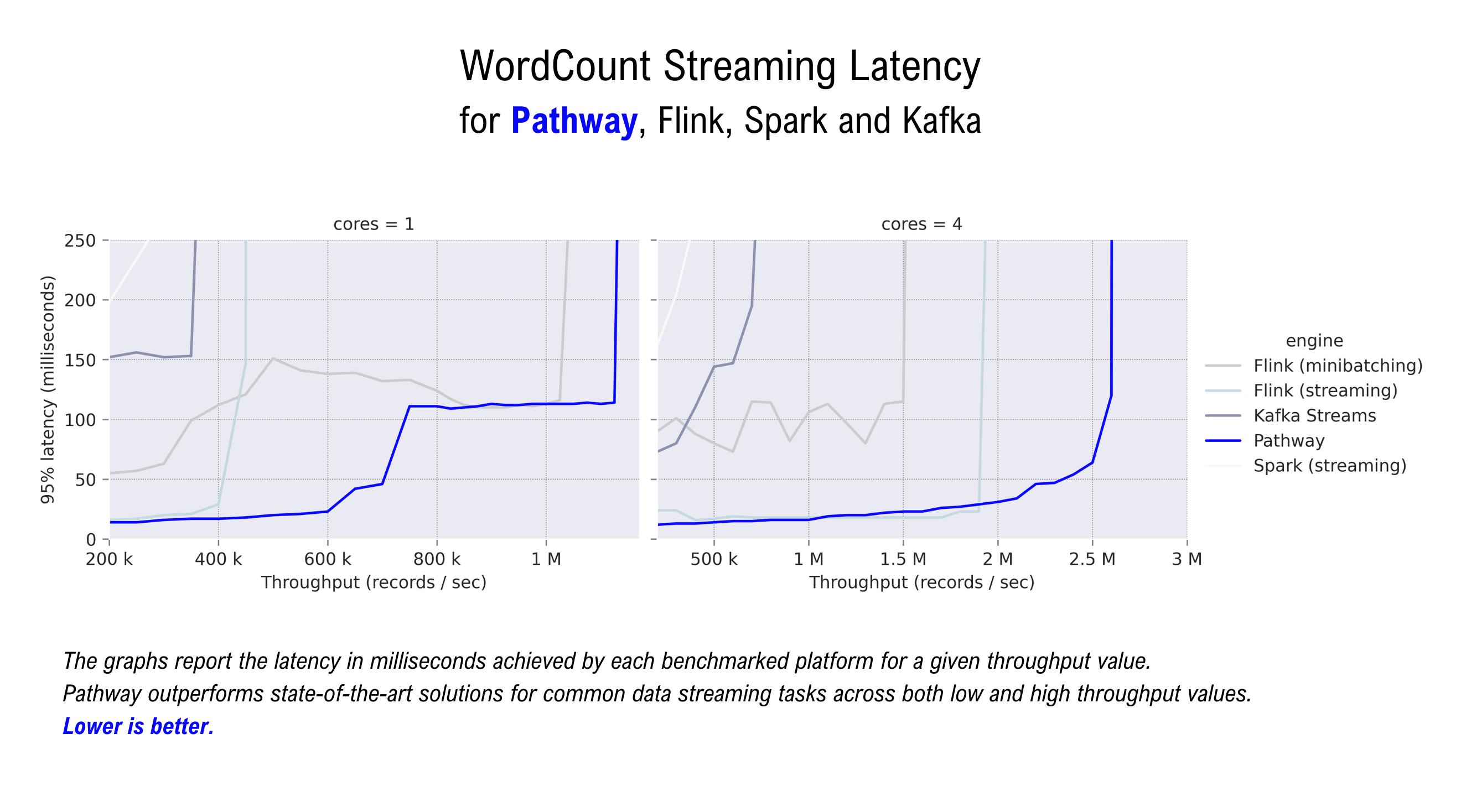
Pathway est conçu pour surpasser les technologies de pointe conçues pour les tâches de streaming et de traitement de données par lots, notamment : Flink, Spark et Kafka Streaming. Il permet également d'implémenter de nombreux algorithmes/UDF en mode streaming qui ne sont pas facilement pris en charge par d'autres frameworks de streaming (notamment : jointures temporelles, algorithmes de graphes itératifs, routines d'apprentissage automatique).
Si vous êtes curieux, voici quelques repères avec lesquels jouer.
L'intégralité de la documentation de Pathway est disponible sur path.com/developers/, y compris la documentation API.
Si vous avez des questions, n'hésitez pas à ouvrir un ticket sur GitHub, rejoignez-nous sur Discord ou envoyez-nous un e-mail à [email protected].
Pathway est distribué sur une licence BSL 1.1 qui permet une utilisation non commerciale illimitée, ainsi que l'utilisation gratuite du package Pathway à la plupart des fins commerciales. Le code de ce référentiel est automatiquement converti en Open Source (licence Apache 2.0) après 4 ans. Certains dépôts publics complémentaires à celui-ci (exemples, bibliothèques, connecteurs, etc.) sont sous licence Open Source, sous la licence MIT.
Si vous développez une bibliothèque ou un connecteur que vous souhaitez intégrer à ce dépôt, nous vous suggérons de le publier d'abord en tant que dépôt distinct sur une licence MIT/Apache 2.0.
Pour toutes les préoccupations concernant les fonctionnalités de base de Pathway, les problèmes sont encouragés. Pour plus d'informations, n'hésitez pas à vous engager auprès de la communauté Discord de Pathway.


