lance
v0.20.0

Format de données en colonnes moderne pour ML. Convertissez depuis Parquet en 2 lignes de code pour un accès aléatoire 100 fois plus rapide, un index vectoriel, une gestion des versions des données, et bien plus encore.
Compatible avec pandas, DuckDB, Polars et pyarrow avec plus d'intégrations en cours.
Documentation • Blog • Discord • Twitter
Lance est un format de données en colonnes moderne optimisé pour les flux de travail et les ensembles de données ML. Lance est parfait pour :
Les principales fonctionnalités de Lance incluent :
Accès aléatoire hautes performances : 100 fois plus rapide que Parquet sans sacrifier les performances d'analyse.
Recherche de vecteurs : trouvez les voisins les plus proches en quelques millisecondes et combinez les requêtes OLAP avec la recherche de vecteurs.
Gestion des versions automatique et sans copie : gérez les versions de vos données sans avoir besoin d'une infrastructure supplémentaire.
Intégrations d'écosystèmes : Apache Arrow, Pandas, Polars, DuckDB et bien d'autres en cours.
Conseil
Lance est en développement actif et nous apprécions les contributions. Veuillez consulter notre guide de contribution pour plus d’informations.
Installation
pip install pylancePour installer une version préliminaire :
pip install --pre --extra-index-url https://pypi.fury.io/lancedb/ pylanceConseil
Les versions préliminaires sont publiées plus souvent que les versions complètes et contiennent les dernières fonctionnalités et corrections de bogues. Ils reçoivent le même niveau de tests que les versions complètes. Nous garantissons qu'ils resteront publiés et disponibles en téléchargement pendant au moins 6 mois. Lorsque vous souhaitez épingler sur une version spécifique, préférez une version stable.
Conversion en Lance
import lance
import pandas as pd
import pyarrow as pa
import pyarrow . dataset
df = pd . DataFrame ({ "a" : [ 5 ], "b" : [ 10 ]})
uri = "/tmp/test.parquet"
tbl = pa . Table . from_pandas ( df )
pa . dataset . write_dataset ( tbl , uri , format = 'parquet' )
parquet = pa . dataset . dataset ( uri , format = 'parquet' )
lance . write_dataset ( parquet , "/tmp/test.lance" )Lecture des données de Lance
dataset = lance . dataset ( "/tmp/test.lance" )
assert isinstance ( dataset , pa . dataset . Dataset )Pandas
df = dataset . to_table (). to_pandas ()
dfCanardDB
import duckdb
# If this segfaults, make sure you have duckdb v0.7+ installed
duckdb . query ( "SELECT * FROM dataset LIMIT 10" ). to_df ()Recherche de vecteurs
Téléchargez le sous-ensemble sift1m
wget ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz
tar -xzf sift.tar.gzConvertissez-le en Lance
import lance
from lance . vector import vec_to_table
import numpy as np
import struct
nvecs = 1000000
ndims = 128
with open ( "sift/sift_base.fvecs" , mode = "rb" ) as fobj :
buf = fobj . read ()
data = np . array ( struct . unpack ( "<128000000f" , buf [ 4 : 4 + 4 * nvecs * ndims ])). reshape (( nvecs , ndims ))
dd = dict ( zip ( range ( nvecs ), data ))
table = vec_to_table ( dd )
uri = "vec_data.lance"
sift1m = lance . write_dataset ( table , uri , max_rows_per_group = 8192 , max_rows_per_file = 1024 * 1024 )Construire l'index
sift1m . create_index ( "vector" ,
index_type = "IVF_PQ" ,
num_partitions = 256 , # IVF
num_sub_vectors = 16 ) # PQRechercher l'ensemble de données
# Get top 10 similar vectors
import duckdb
dataset = lance . dataset ( uri )
# Sample 100 query vectors. If this segfaults, make sure you have duckdb v0.7+ installed
sample = duckdb . query ( "SELECT vector FROM dataset USING SAMPLE 100" ). to_df ()
query_vectors = np . array ([ np . array ( x ) for x in sample . vector ])
# Get nearest neighbors for all of them
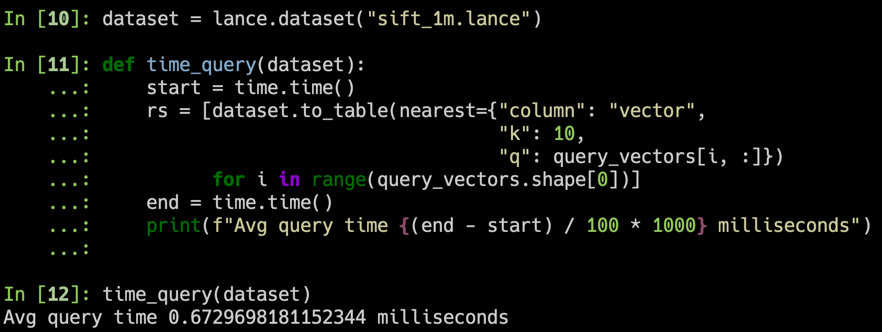
rs = [ dataset . to_table ( nearest = { "column" : "vector" , "k" : 10 , "q" : q })
for q in query_vectors ]| Annuaire | Description |
|---|---|
| rouiller | Implémentation de base de Rust |
| python | Liaisons Python (pyo3) |
| documents | Source des documents |
Nous mettrons ici en évidence quelques aspects de la conception de Lance. Pour plus de détails, consultez le document de conception complet de Lance.
Index vectoriel : Index vectoriel pour la recherche de similarité sur l'espace d'intégration. Prend en charge les processeurs ( x86_64 et arm ) et les GPU ( Nvidia (cuda) et Apple Silicon (mps) ).
Encodages : pour réaliser à la fois une analyse rapide en colonnes et des requêtes de points sous-linéaires, Lance utilise des encodages et des mises en page personnalisés.
Champs imbriqués : Lance stocke chaque sous-champ dans une colonne distincte pour prendre en charge des filtres efficaces tels que « trouver des images où les objets détectés incluent des chats ».
Versioning : un manifeste peut être utilisé pour enregistrer des instantanés. Actuellement, nous prenons en charge la création automatique de nouvelles versions via des ajouts, des écrasements et la création d'index.
Mises à jour rapides (ROADMAP) : les mises à jour seront prises en charge via des journaux à écriture anticipée.
Indices secondaires riches (ROADMAP) :
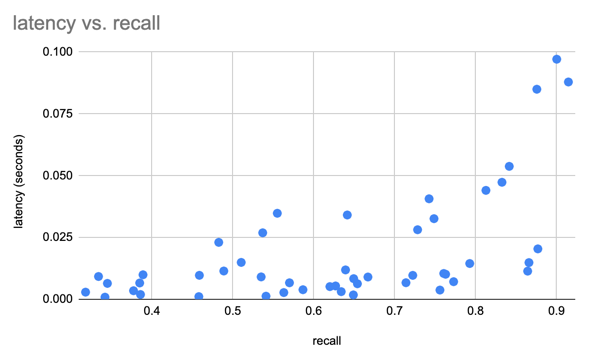
Nous avons utilisé l'ensemble de données SIFT pour comparer nos résultats avec 1 million de vecteurs de 128D.
Nous créons un ensemble de données Lance en utilisant l'ensemble de données Oxford Pet pour effectuer des tests de performances préliminaires de Lance par rapport à Parquet et aux images brutes/XML. Pour les requêtes analytiques, Lance est 50 à 100 fois meilleur que la lecture des métadonnées brutes. Pour un accès aléatoire par lots, Lance est 100 fois meilleur que les fichiers Parquet et Raw.

Le cycle de développement du machine learning comprend les étapes :
graphique LR
A[Collection] --> B[Exploration];
B --> C[Analyses] ;
C --> D[Ingénieur fonctionnalités] ;
D --> E[Formation] ;
E --> F[Évaluation] ;
F --> C ;
E --> G[Déploiement] ;
G --> H[Surveillance] ;
H --> A ;
Les gens utilisent différentes représentations de données à différentes étapes pour la performance ou sont limitées par les outils disponibles. Le monde universitaire utilise principalement XML/JSON pour les annotations et les données d'images/capteurs compressées pour l'apprentissage en profondeur, qui est difficile à intégrer dans l'infrastructure de données et lent à s'entraîner sur le stockage cloud. Alors que l'industrie utilise des lacs de données (techniques basées sur Parquet, par exemple Delta Lake, Iceberg) ou des entrepôts de données (AWS Redshift ou Google BigQuery) pour collecter et analyser des données, elle doit convertir les données dans des formats adaptés à la formation, tels que Rikai/ Petastorm ou TFRecord. Plusieurs transformations de données à usage unique, ainsi que la synchronisation de copies entre le stockage cloud et les instances de formation locales sont devenues une pratique courante.
Bien que chacun des formats de données existants excelle dans la charge de travail pour laquelle il a été conçu à l'origine, nous avons besoin d'un nouveau format de données adapté aux cycles de développement de ML à plusieurs étapes afin de réduire les silos de données.
Une comparaison de différents formats de données à chaque étape du cycle de développement du ML.
| Lance | Parquet et ORC | JSON et XML | TFEnregistrement | Base de données | Entrepôt | |
|---|---|---|---|---|---|---|
| Analytique | Rapide | Rapide | Lent | Lent | Décent | Rapide |
| Ingénierie des fonctionnalités | Rapide | Rapide | Décent | Lent | Décent | Bien |
| Entraînement | Rapide | Décent | Lent | Rapide | N / A | N / A |
| Exploration | Rapide | Lent | Rapide | Lent | Rapide | Décent |
| Prise en charge infrarouge | Riche | Riche | Décent | Limité | Riche | Riche |
Lance est actuellement utilisée en production par :


