JS Sorting Algorithm
1.0.0
L'algorithme de tri est l'un des algorithmes les plus basiques dans « Structures de données et algorithmes ».
Les algorithmes de tri peuvent être divisés en tri interne et tri externe. Le tri interne consiste à trier les enregistrements de données en mémoire, tandis que le tri externe est dû au fait que les données triées sont très volumineuses et ne peuvent pas accueillir tous les enregistrements triés en même temps. il faut accéder à la mémoire. Les algorithmes de tri internes courants incluent : le tri par insertion, le tri Hill, le tri par sélection, le tri à bulles, le tri par fusion, le tri rapide, le tri par tas, le tri par base, etc. Résumez-le avec une image :
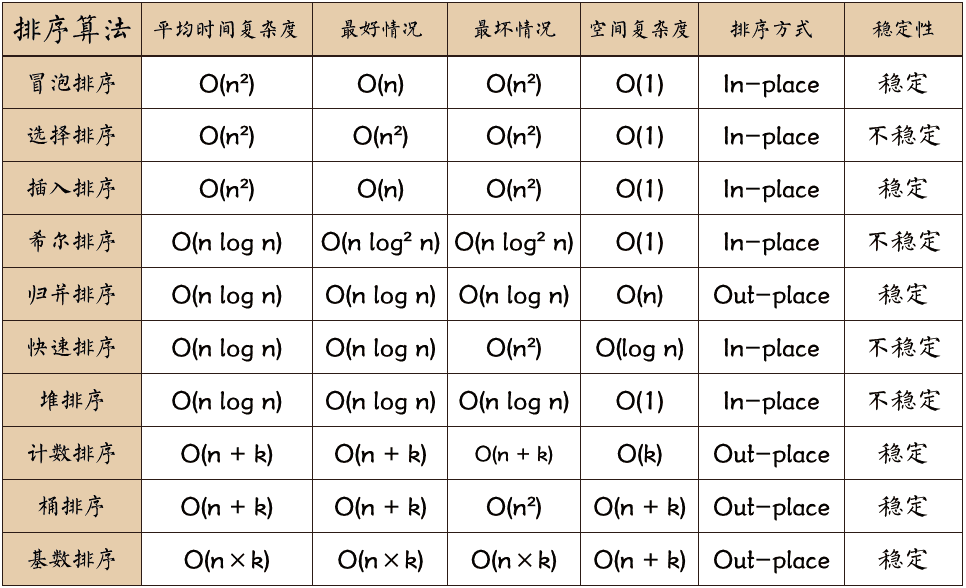
Concernant la complexité temporelle :
Concernant la stabilité :
Algorithmes de tri stables : tri à bulles, tri par insertion, tri par fusion et tri par base.
Algorithmes de tri non stables : tri par sélection, tri rapide, tri Hill, tri par tas.
Glossaire :
n : taille des données
k : le nombre de "buckets"
Sur place : occupe une mémoire constante et n'occupe pas de mémoire supplémentaire
Out-place : prend de la mémoire supplémentaire
Stabilité : L'ordre de deux valeurs clés égales après le tri est le même que leur ordre avant le tri.
Aperçu du contenu de GitBook
Le contenu de ce livre provient presque entièrement d'Internet.
Adresse du projet open source : https://github.com/hustcc/JS-Sorting-Algorithm, organisé par hustcc.
Adresse de lecture en ligne de GitBook : https://sort.hust.cc/.
Ce projet utilise lint-md pour vérifier le format des fichiers Markdown chinois. Assurez-vous que le format Markdown est correct avant de soumettre le PR.


