qlib
v0.9.5 ?

Fonctionnalités publiées récemment
 : Agents évolutifs autonomes basés sur le LLM pour la R&D industrielle basée sur les données
: Agents évolutifs autonomes basés sur le LLM pour la R&D industrielle basée sur les donnéesNous sommes ravis d'annoncer la sortie de RD-Agent ?, un outil puissant qui prend en charge l'exploration automatisée de facteurs et l'optimisation de modèles dans la R&D en investissement quantitatif.
RD-Agent est maintenant disponible sur GitHub, et nous souhaitons la bienvenue à votre étoile ?!
Pour en savoir plus, veuillez visiter notre page ♾️Démo. Ici, vous trouverez des vidéos de démonstration en anglais et en chinois pour vous aider à mieux comprendre le scénario et l'utilisation de RD-Agent.
Nous avons préparé plusieurs vidéos de démonstration pour vous :
| Scénario | Vidéo de démonstration (anglais) | Vidéo de démonstration (中文) |
|---|---|---|
| Extraction de facteurs quantitatifs | Lien | Lien |
| Extraction de facteurs quantitatifs à partir de rapports | Lien | Lien |
| Optimisation du modèle quantitatif | Lien | Lien |
| Fonctionnalité | Statut |
|---|---|
| BPQP pour un apprentissage de bout en bout | ?Bientôt !(En cours de révision) |
| Auto Quant Factory pilotée par LLM | Sorti dans ♾️RD-Agent le 8 août 2024 |
| Modèles KRNN et Sandwich | ? Sortie le 26 mai 2023 |
| Publier Qlib v0.9.0 | Sortie le 9 décembre 2022 |
| Cadre d'apprentissage RL | ? ? Sorti le 10 novembre 2022. #1332, #1322, #1316, #1299, #1263, #1244, #1169, #1125, #1076 |
| Modèles HIST et IGMTF | ? Sortie le 10 avril 2022 |
| Tutoriel sur le bloc-notes Qlib | Sortie le 7 avril 2022 |
| Données de l'indice Ibovespa | ? Sortie le 6 avril 2022 |
| Base de données ponctuelle | ? Sortie le 10 mars 2022 |
| Exemple de données Backend et carnet de commandes du fournisseur Arctic | ? Sortie le 17 janvier 2022 |
| Cadre basé sur le méta-apprentissage et DDG-DA | ? ? Sortie le 10 janvier 2022 |
| Optimisation du portefeuille basée sur la planification | ? Sorti le 28 décembre 2021 |
| Publier Qlib v0.8.0 | Sorti le 8 décembre 2021 |
| AJOUTER un modèle | ? Sortie le 22 novembre 2021 |
| Modèle ADARNN | ? Sorti le 14 novembre 2021 |
| Modèle RTC | ? Sorti le 4 novembre 2021 |
| Cadre de décision imbriqué | ? Sortie le 1er octobre 2021. Exemple et Doc |
| Adaptateur de routage temporel (TRA) | ? Sortie le 30 juillet 2021 |
| Transformateur & Localformer | ? Sortie le 22 juillet 2021 |
| Publier Qlib v0.7.0 | Sortie le 12 juillet 2021 |
| Modèle TCTS | ? Sortie le 1er juillet 2021 |
| Service en ligne et roulement de modèle automatique | ? Sortie le 17 mai 2021 |
| Modèle DoubleEnsemble | ? Sorti le 2 mars 2021 |
| Exemple de traitement de données haute fréquence | ? Sorti le 5 février 2021 |
| Exemple de trading haute fréquence | ? Partie du code publiée le 28 janvier 2021 |
| Données haute fréquence (1 min) | ? Sortie le 27 janvier 2021 |
| Modèle Tabnet | ? Sortie le 22 janvier 2021 |
Les fonctionnalités publiées avant 2021 ne sont pas répertoriées ici.

Qlib est une plateforme d'investissement quantitatif open source orientée IA qui vise à réaliser le potentiel, à responsabiliser la recherche et à créer de la valeur en utilisant les technologies d'IA dans l'investissement quantitatif, de l'exploration d'idées à la mise en œuvre de productions. Qlib prend en charge divers paradigmes de modélisation d'apprentissage automatique, notamment l'apprentissage supervisé, la modélisation de la dynamique du marché et l'apprentissage par renforcement.
Un nombre croissant de travaux/articles de recherche SOTA Quant dans divers paradigmes sont publiés dans Qlib pour résoudre de manière collaborative les principaux défis de l'investissement quantitatif. Par exemple, 1) utiliser l'apprentissage supervisé pour exploiter les modèles non linéaires complexes du marché à partir de données financières riches et hétérogènes, 2) modéliser la nature dynamique du marché financier à l'aide d'une technologie adaptative de dérive des concepts, et 3) utiliser l'apprentissage par renforcement pour modéliser l'investissement continu. décisions et aider les investisseurs à optimiser leurs stratégies de trading.
Il contient le pipeline ML complet de traitement des données, de formation de modèles et de back-tests ; et couvre toute la chaîne d'investissement quantitatif : recherche d'alpha, modélisation des risques, optimisation de portefeuille et exécution d'ordres. Pour plus de détails, veuillez vous référer à notre article « Qlib : Une plateforme d'investissement quantitatif orientée IA ».
| Frameworks, tutoriel, données et DevOps | Principaux défis et solutions dans la recherche quantique |
|---|---|
|
|
Nouvelles fonctionnalités en cours de développement (classées par heure de sortie estimée). Vos retours sur les fonctionnalités sont très importants.

Le cadre de haut niveau de Qlib peut être trouvé ci-dessus (les utilisateurs peuvent trouver le cadre détaillé de la conception de Qlib lorsqu'ils entrent dans le vif du sujet). Les composants sont conçus sous forme de modules couplés de manière lâche et chaque composant peut être utilisé de manière autonome.
Qlib fournit une infrastructure solide pour prendre en charge la recherche Quant. Les données sont toujours une partie importante. Un cadre d'apprentissage solide est conçu pour prendre en charge divers paradigmes d'apprentissage (par exemple, apprentissage par renforcement, apprentissage supervisé) et modèles à différents niveaux (par exemple, modélisation dynamique du marché). En modélisant le marché, les stratégies de trading généreront des décisions commerciales qui seront exécutées. Plusieurs stratégies de trading et exécuteurs à différents niveaux ou granularités peuvent être imbriqués pour être optimisés et exécutés ensemble. Enfin, une analyse complète sera fournie et le modèle pourra être servi en ligne à faible coût.
Ce guide de démarrage rapide tente de démontrer
Voici une démo rapide montrant comment installer Qlib et exécuter LightGBM avec qrun . Mais assurez-vous d'avoir déjà préparé les données en suivant les instructions.
Ce tableau montre la version Python prise en charge de Qlib :
| installer avec pip | installer à partir des sources | parcelle | |
|---|---|---|---|
| Python3.7 | ✔️ | ✔️ | ✔️ |
| Python3.8 | ✔️ | ✔️ | ✔️ |
| Python3.9 | ✔️ |
Note :
conda peut entraîner des fichiers d'en-tête manquants, provoquant l'échec de l'installation de certains packages.Qlib à partir des sources. Si les utilisateurs utilisent Python 3.6 sur leurs machines, il est recommandé de mettre à niveau Python vers la version 3.7 ou d'utiliser Python de conda pour installer Qlib à partir des sources.Qlib prend en charge l'exécution de workflows tels que la formation de modèles, l'exécution de backtests et le tracé de la plupart des figures associées (ceux inclus dans le notebook). Cependant, le traçage des performances du modèle n'est pas pris en charge pour le moment et nous corrigerons ce problème lors de la mise à niveau future des packages dépendants.Qlib Nécessite le package tables , hdf5 dans les tables ne prend pas en charge python3.9. Les utilisateurs peuvent facilement installer Qlib par pip selon la commande suivante.
pip install pyqlibRemarque : pip installera la dernière qlib stable. Cependant, la branche principale de qlib est en développement actif. Si vous souhaitez tester les derniers scripts ou fonctions de la branche principale. Veuillez installer qlib avec les méthodes ci-dessous.
En outre, les utilisateurs peuvent installer la dernière version de développement Qlib à l'aide du code source en suivant les étapes suivantes :
Avant d'installer Qlib à partir des sources, les utilisateurs doivent installer certaines dépendances :
pip install numpy
pip install --upgrade cython Clonez le référentiel et installez Qlib comme suit.
git clone https://github.com/microsoft/qlib.git && cd qlib
pip install . # `pip install -e .[dev]` is recommended for development. check details in docs/developer/code_standard_and_dev_guide.rst Remarque : Vous pouvez également installer Qlib avec python setup.py install . Mais ce n’est pas l’approche recommandée. Cela sautera pip et causera des problèmes obscurs. Par exemple, seule la commande pip install . peut écraser la version stable installée par pip install pyqlib , alors que la commande python setup.py install ne le peut pas .
Conseils : Si vous ne parvenez pas à installer Qlib ou à exécuter les exemples dans votre environnement, comparer vos étapes et le workflow CI peut vous aider à trouver le problème.
Conseils pour Mac : Si vous utilisez Mac avec M1, vous pourriez rencontrer des problèmes lors de la création de la roue pour LightGBM, en raison de dépendances manquantes d'OpenMP. Pour résoudre le problème, installez d'abord openmp avec brew install libomp , puis exécutez pip install . pour le construire avec succès.
❗ En raison d'une politique de sécurité des données plus restrictive. L'ensemble de données officiel est temporairement désactivé. Vous pouvez essayer cette source de données fournie par la communauté. Voici un exemple pour télécharger les données mises à jour le 20240809.
wget https://github.com/chenditc/investment_data/releases/download/2024-08-09/qlib_bin.tar.gz
mkdir -p ~ /.qlib/qlib_data/cn_data
tar -zxvf qlib_bin.tar.gz -C ~ /.qlib/qlib_data/cn_data --strip-components=1
rm -f qlib_bin.tar.gzL'ensemble de données officiel ci-dessous reprendra dans un avenir proche.
Chargez et préparez les données en exécutant le code suivant :
# get 1d data
python -m qlib.run.get_data qlib_data --target_dir ~ /.qlib/qlib_data/cn_data --region cn
# get 1min data
python -m qlib.run.get_data qlib_data --target_dir ~ /.qlib/qlib_data/cn_data_1min --region cn --interval 1min
# get 1d data
python scripts/get_data.py qlib_data --target_dir ~ /.qlib/qlib_data/cn_data --region cn
# get 1min data
python scripts/get_data.py qlib_data --target_dir ~ /.qlib/qlib_data/cn_data_1min --region cn --interval 1min
Cet ensemble de données est créé à partir de données publiques collectées par des scripts de robot d'exploration, qui ont été publiées dans le même référentiel. Les utilisateurs pourraient créer le même ensemble de données avec. Description de l'ensemble de données
Veuillez faire ATTENTION au fait que les données sont collectées auprès de Yahoo Finance et qu'elles peuvent ne pas être parfaites. Nous recommandons aux utilisateurs de préparer leurs propres données s'ils disposent d'un ensemble de données de haute qualité. Pour plus d'informations, les utilisateurs peuvent se référer au document associé .
Cette étape est facultative si les utilisateurs souhaitent uniquement essayer leurs modèles et stratégies sur les données historiques.
Il est recommandé aux utilisateurs de mettre à jour les données manuellement une fois (--trading_date 2021-05-25), puis de les configurer pour qu'elles se mettent à jour automatiquement.
REMARQUE : les utilisateurs ne peuvent pas mettre à jour progressivement les données en fonction des données hors ligne fournies par Qlib (certains champs sont supprimés pour réduire la taille des données). Les utilisateurs doivent utiliser Yahoo Collector pour télécharger les données Yahoo à partir de zéro, puis les mettre à jour progressivement.
Pour plus d'informations, veuillez vous référer à : Yahoo Collector
Mise à jour automatique des données vers le répertoire "qlib" chaque jour de bourse (Linux)
utiliser crontab : crontab -e
configurer des tâches chronométrées :
* * * * 1-5 python <script path> update_data_to_bin --qlib_data_1d_dir <user data dir>
Mise à jour manuelle des données
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir <user data dir> --trading_date <start date> --end_date <end date>
docker pull pyqlib/qlib_image_stable:stabledocker run -it --name < container name > -v < Mounted local directory > :/app qlib_image_stable>>> python scripts/get_data.py qlib_data --name qlib_data_simple --target_dir ~ /.qlib/qlib_data/cn_data --interval 1d --region cn
>>> python qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml>>> exitdocker start -i -a < container name >docker stop < container name >docker rm < container name > Qlib fournit un outil nommé qrun pour exécuter automatiquement l'ensemble du flux de travail (y compris la création d'un ensemble de données, les modèles de formation, le backtest et l'évaluation). Vous pouvez démarrer un workflow de recherche quantifiée automatique et effectuer une analyse graphique des rapports selon les étapes suivantes :
Flux de travail de recherche quantique : exécutez qrun avec la configuration du flux de travail lightgbm (workflow_config_lightgbm_Alpha158.yaml comme suit.
cd examples # Avoid running program under the directory contains `qlib`
qrun benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml Si les utilisateurs souhaitent utiliser qrun en mode débogage, veuillez utiliser la commande suivante :
python -m pdb qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml Le résultat de qrun est le suivant, veuillez vous référer à Intraday Trading pour plus de détails sur le résultat.
' The following are analysis results of the excess return without cost. '
risk
mean 0.000708
std 0.005626
annualized_return 0.178316
information_ratio 1.996555
max_drawdown -0.081806
' The following are analysis results of the excess return with cost. '
risk
mean 0.000512
std 0.005626
annualized_return 0.128982
information_ratio 1.444287
max_drawdown -0.091078 Voici des documents détaillés pour qrun et workflow.
Analyse des rapports graphiques : exécutez examples/workflow_by_code.ipynb avec jupyter notebook pour obtenir des rapports graphiques
Analyse du signal de prévision (prédiction du modèle)
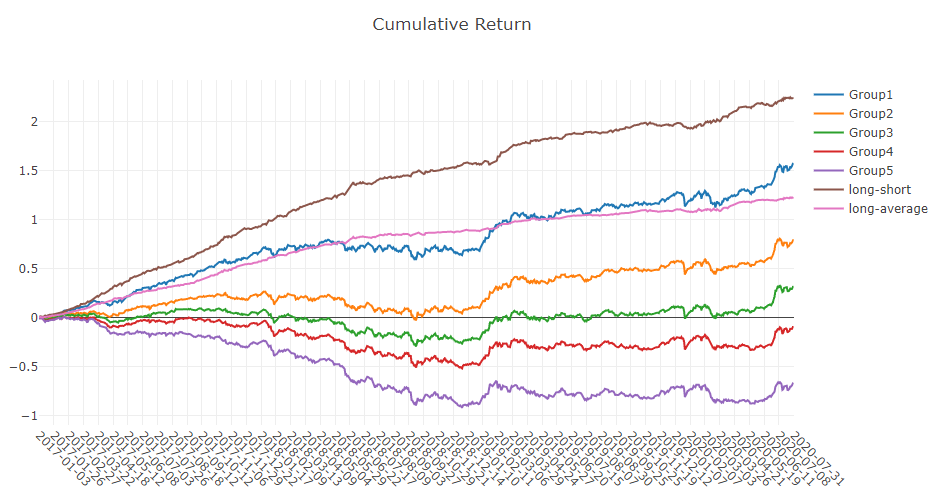
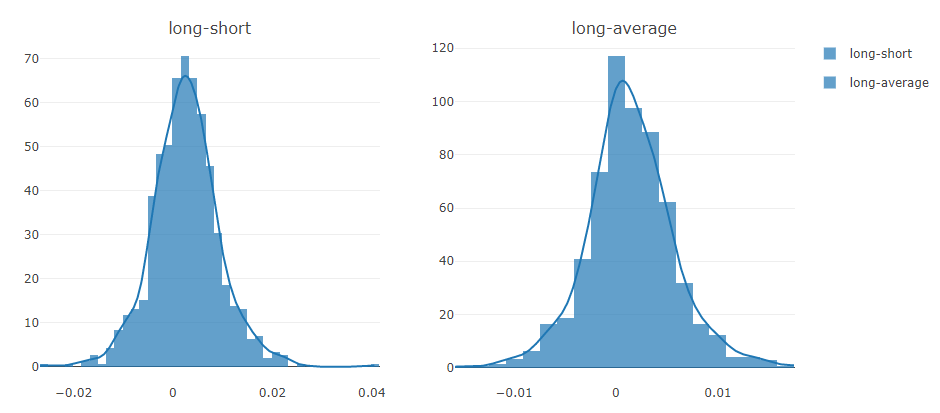
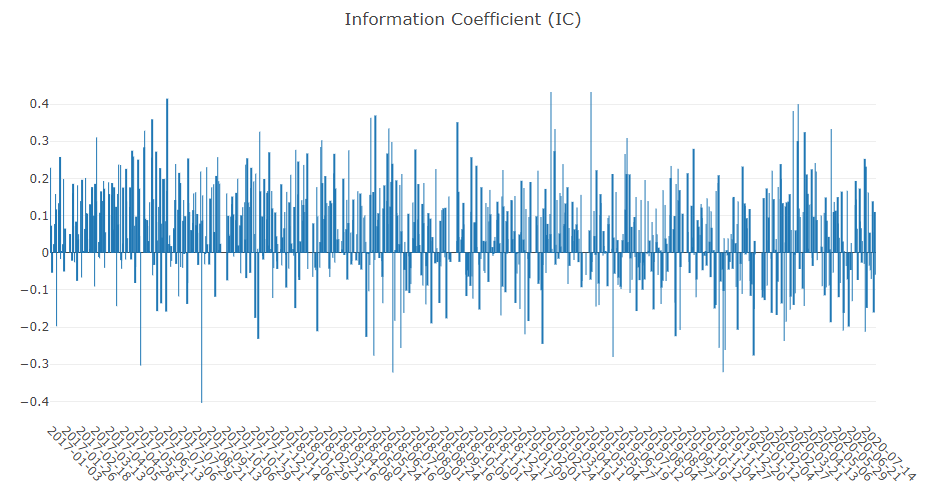
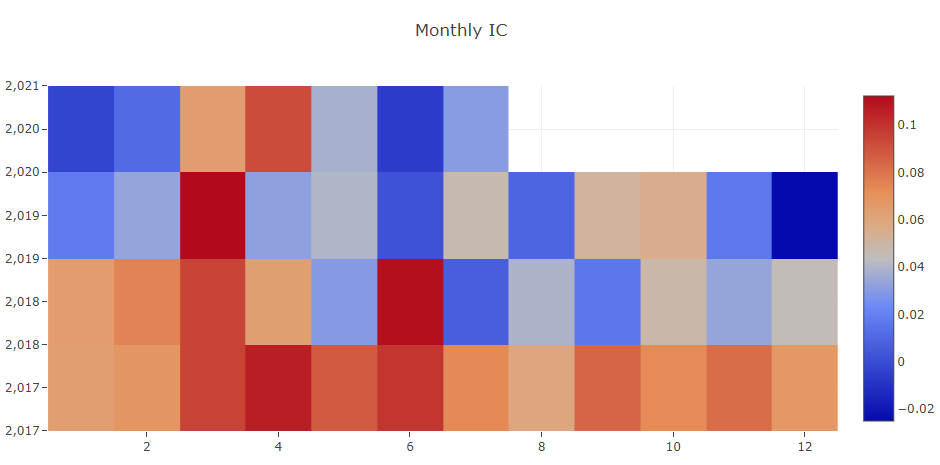
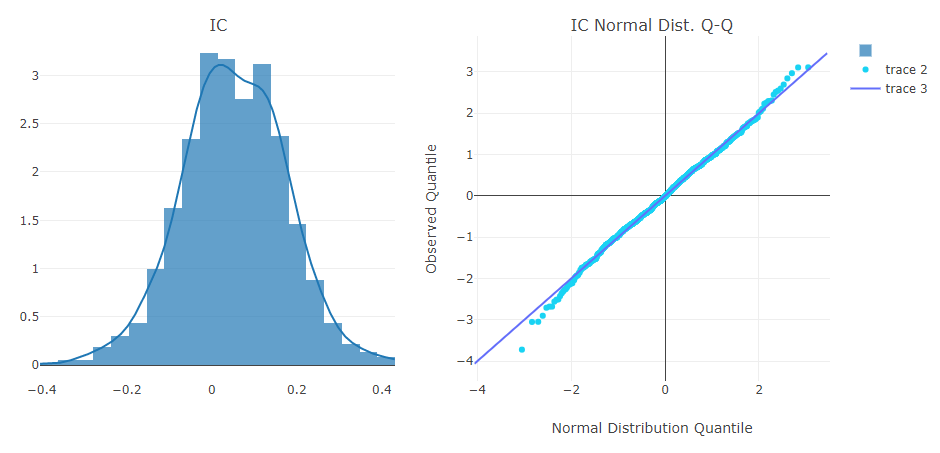
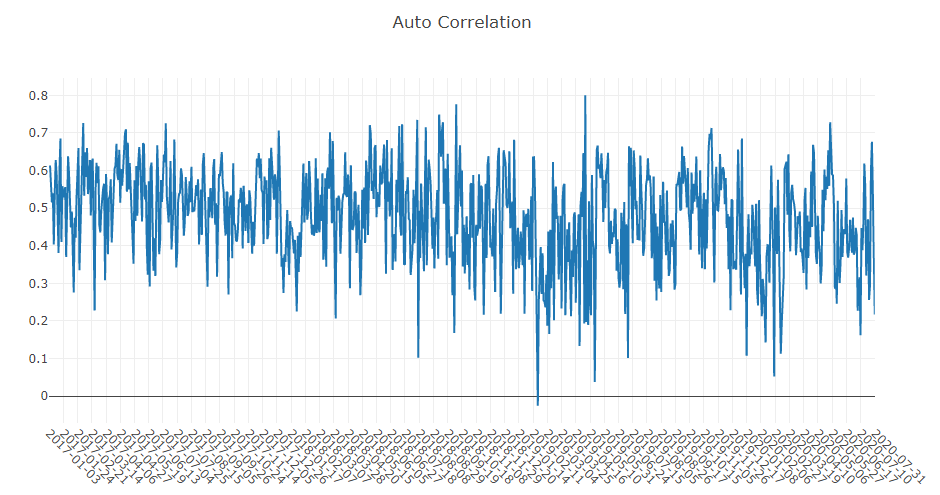
Analyse de portefeuille
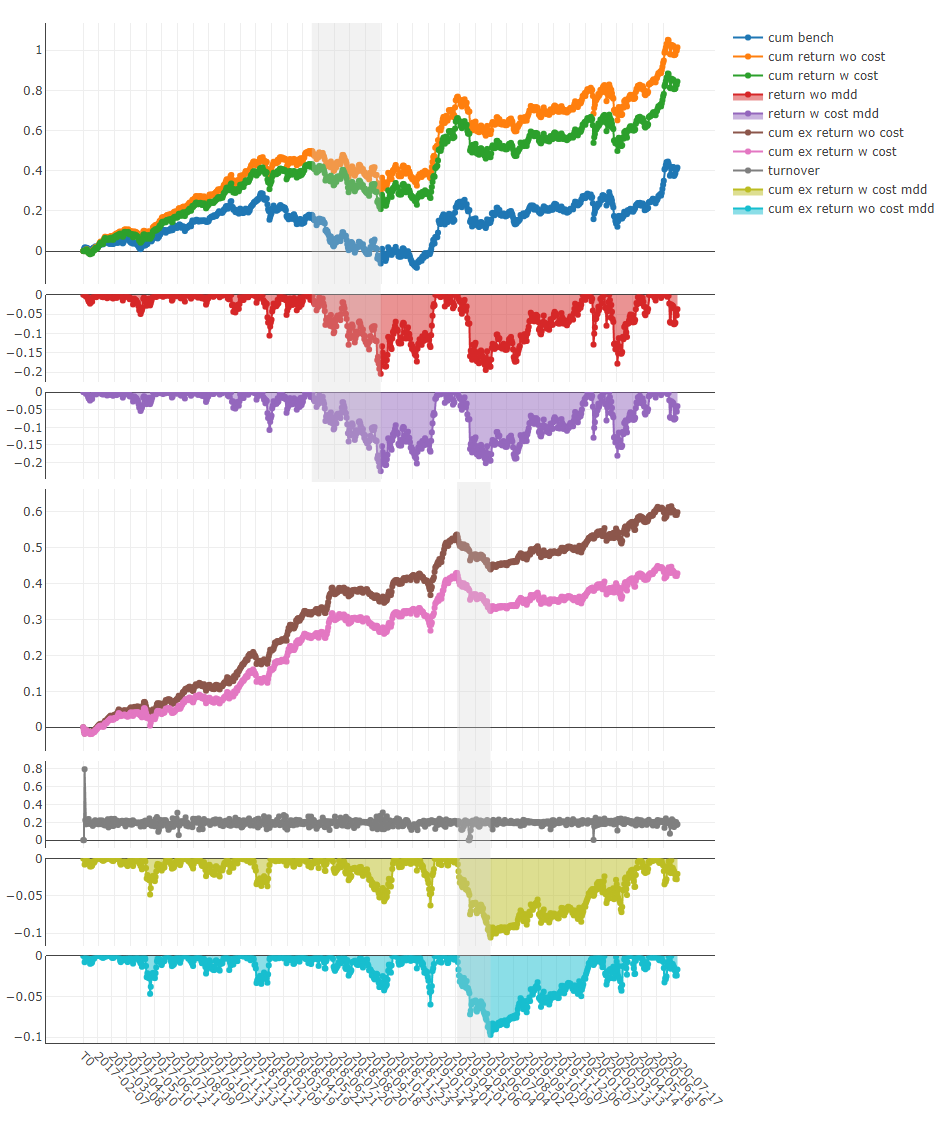
Explication des résultats ci-dessus
Le flux de travail automatique peut ne pas convenir au flux de travail de recherche de tous les chercheurs Quant. Pour prendre en charge un flux de travail de recherche Quant flexible, Qlib fournit également une interface modularisée pour permettre aux chercheurs de créer leur propre flux de travail par code. Voici une démo pour un flux de travail de recherche Quant personnalisé par code.
L’investissement quantitatif est un scénario tout à fait unique avec de nombreux défis clés à résoudre. Actuellement, Qlib propose des solutions pour plusieurs d’entre eux.
Une prévision précise de l’évolution du cours des actions est un élément très important pour construire des portefeuilles rentables. Cependant, l’énorme quantité de données sous différents formats sur le marché financier rend difficile la création de modèles de prévision.
Un nombre croissant de travaux/articles de recherche SOTA Quant, qui se concentrent sur la création de modèles de prévision pour extraire des signaux/modèles précieux dans des données financières complexes, sont publiés dans Qlib
Voici une liste de modèles construits sur Qlib .
Votre PR de nouveaux modèles Quant est la bienvenue.
Les performances de chaque modèle sur les ensembles de données Alpha158 et Alpha360 peuvent être trouvées ici.
Tous les modèles répertoriés ci-dessus sont exécutables avec Qlib . Les utilisateurs peuvent trouver les fichiers de configuration que nous fournissons et quelques détails sur le modèle via le dossier benchmarks. Plus d’informations peuvent être récupérées dans les fichiers modèles répertoriés ci-dessus.
Qlib propose trois manières différentes d'exécuter un seul modèle, les utilisateurs peuvent choisir celle qui correspond le mieux à leur cas :
Les utilisateurs peuvent utiliser l'outil qrun mentionné ci-dessus pour exécuter le flux de travail d'un modèle basé sur un fichier de configuration.
Les utilisateurs peuvent créer un script python workflow_by_code basé sur celui répertorié dans le dossier examples .
Les utilisateurs peuvent utiliser le script run_all_model.py répertorié dans le dossier examples pour exécuter un modèle. Voici un exemple de commande shell spécifique à utiliser : python run_all_model.py run --models=lightgbm , où les arguments --models peuvent prendre n'importe quel nombre de modèles répertoriés ci-dessus (les modèles disponibles peuvent être trouvés dans les benchmarks). Pour plus de cas d'utilisation, veuillez vous référer aux docstrings du fichier.
tensorflow==1.15.0 ) Qlib fournit également un script run_all_model.py qui peut exécuter plusieurs modèles pendant plusieurs itérations. ( Remarque : le script ne prend en charge que Linux pour le moment. D'autres systèmes d'exploitation seront pris en charge à l'avenir. De plus, il ne prend pas non plus en charge l'exécution parallèle du même modèle plusieurs fois, et cela sera également corrigé dans le développement futur.)
Le script créera un environnement virtuel unique pour chaque modèle et supprimera les environnements après la formation. Ainsi, seuls les résultats d’expériences tels que les résultats IC et backtest seront générés et stockés.
Voici un exemple d'exécution de tous les modèles pendant 10 itérations :
python run_all_model . py run 10Il fournit également l'API permettant d'exécuter des modèles spécifiques à la fois. Pour plus de cas d'utilisation, veuillez vous référer aux docstrings du fichier.
En raison de la nature non stationnaire de l'environnement du marché financier, la distribution des données peut changer à différentes périodes, ce qui fait que les performances des modèles basés sur les données d'entraînement se désintègrent dans les futures données de test. Ainsi, l’adaptation des modèles/stratégies de prévision à la dynamique du marché est très importante pour la performance des modèles/stratégies.
Voici une liste de solutions construites sur Qlib .
Qlib prend désormais en charge l'apprentissage par renforcement, une fonctionnalité conçue pour modéliser les décisions d'investissement continues. Cette fonctionnalité aide les investisseurs à optimiser leurs stratégies de trading en apprenant des interactions avec l'environnement pour maximiser une certaine notion de récompense cumulative.
Voici une liste de solutions construites sur Qlib classées par scénarios.
Voici l'introduction de ce scénario. Toutes les méthodes ci-dessous sont comparées ici.
L'ensemble de données joue un rôle très important dans Quant. Voici une liste des jeux de données construits sur Qlib :
| Ensemble de données | Marché américain | Marché chinois |
|---|---|---|
| Alpha360 | √ | √ |
| Alpha158 | √ | √ |
Voici un tutoriel pour créer un ensemble de données avec Qlib . Votre PR pour créer un nouvel ensemble de données Quant est très bien accueilli.
Qlib est hautement personnalisable et beaucoup de ses composants peuvent être appris. Les composants apprenables sont des instances de Forecast Model et Trading Agent . Ils sont appris sur la base de la couche Learning Framework , puis appliqués à plusieurs scénarios dans la couche Workflow . Le cadre d'apprentissage exploite également la couche Workflow (par exemple, partage Information Extractor , création d'environnements basés sur Execution Env ).
Sur la base des paradigmes d’apprentissage, ils peuvent être classés en apprentissage par renforcement et apprentissage supervisé.
Execution Env dans Workflow pour créer des environnements. Il convient de noter que NestedExecutor est également pris en charge. Cela permet aux utilisateurs d'optimiser ensemble différents niveaux de stratégies/modèles/agents (par exemple, optimiser une stratégie d'exécution d'ordres pour une stratégie de gestion de portefeuille spécifique).Si vous souhaitez avoir un aperçu rapide des composants de qlib les plus fréquemment utilisés, vous pouvez essayer les notebooks ici.
Les documents détaillés sont organisés en docs. Sphinx et le thème readthedocs sont requis pour créer la documentation aux formats HTML.
cd docs/
conda install sphinx sphinx_rtd_theme -y
# Otherwise, you can install them with pip
# pip install sphinx sphinx_rtd_theme
make htmlVous pouvez également consulter le dernier document directement en ligne.
Qlib est en développement actif et continu. Notre plan est dans la feuille de route, qui est gérée comme un projet github.
Le serveur de données de Qlib peut être déployé en mode Offline ou en mode Online . Le mode par défaut est le mode hors ligne.
En mode Offline , les données seront déployées localement.
En mode Online , les données seront déployées en tant que service de données partagé. Les données et leur cache seront partagés par tous les clients. Les performances de récupération des données devraient être améliorées en raison d'un taux plus élevé d'accès au cache. Cela consommera également moins d’espace disque. Les documents du mode en ligne sont disponibles dans Qlib-Server. Le mode en ligne peut être déployé automatiquement avec des scripts basés sur Azure CLI. Le code source du serveur de données en ligne peut être trouvé dans le référentiel Qlib-Server.
La performance du traitement des données est importante pour les méthodes basées sur les données telles que les technologies d'IA. En tant que plateforme orientée IA, Qlib fournit une solution de stockage et de traitement des données. Pour démontrer les performances du serveur de données Qlib, nous le comparons avec plusieurs autres solutions de stockage de données.
Nous évaluons les performances de plusieurs solutions de stockage en accomplissant la même tâche, qui crée un ensemble de données (14 caractéristiques/facteurs) à partir des données quotidiennes de base OHLCV d'une bourse (800 actions chaque jour de 2007 à 2020). La tâche implique des requêtes et un traitement de données.
| HDF5 | MySQL | MongoDB | InfluxDB | Qlib -E -D | Qlib +E -D | Qlib +E +D | |
|---|---|---|---|---|---|---|---|
| Total (1 CPU) (secondes) | 184,4 ± 3,7 | 365,3 ± 7,5 | 253,6 ± 6,7 | 368,2 ± 3,6 | 147,0 ± 8,8 | 47,6 ± 1,0 | 7,4 ± 0,3 |
| Total (64 CPU) (secondes) | 8,8 ± 0,6 | 4,2 ± 0,2 |
+(-)E indique avec (out) ExpressionCache+(-)D indique avec (out) DatasetCacheLa plupart des bases de données à usage général prennent trop de temps pour charger les données. Après avoir examiné l'implémentation sous-jacente, nous constatons que les données passent par trop de couches d'interfaces et de transformations de format inutiles dans les solutions de bases de données à usage général. De telles surcharges ralentissent considérablement le processus de chargement des données. Les données Qlib sont stockées dans un format compact, ce qui permet de les combiner efficacement dans des tableaux à des fins de calcul scientifique.
Qlib , veuillez créer des pull request.Rejoignez les groupes de discussion de messagerie instantanée :
| Gitter |
|---|
 |
Nous apprécions toutes les contributions et remercions tous les contributeurs !
Avant de publier Qlib en tant que projet open source sur Github en septembre 2020, Qlib était un projet interne à notre groupe. Malheureusement, l’historique des validations internes n’est pas conservé. De nombreux membres de notre groupe ont également beaucoup contribué à Qlib, notamment Ruihua Wang, Yinda Zhang, Haisu Yu, Shuyu Wang, Bochen Pang et Dong Zhou. Notamment grâce à Dong Zhou pour sa version initiale de Qlib.
Ce projet accueille les contributions et suggestions.
Voici quelques normes de code et conseils de développement pour soumettre une pull request.
Faire des contributions n’est pas une chose difficile. Résoudre un problème (peut-être simplement répondre à une question soulevée dans la liste des problèmes ou dans le gitter), corriger/émettre un bug, améliorer les documents et même corriger une faute de frappe sont des contributions importantes à Qlib.
Par exemple, si vous souhaitez contribuer au document/code de Qlib, vous pouvez suivre les étapes décrites dans la figure ci-dessous.

Si vous ne savez pas par où commencer à contribuer, vous pouvez vous référer aux exemples suivants.
| Taper | Exemples |
|---|---|
| Résoudre les problèmes | Répondez à une question ; émettre ou corriger un bug |
| Documents | Améliorer la qualité des documents ; Corriger une faute de frappe |
| Fonctionnalité | Implémentez une fonctionnalité demandée comme celle-ci ; Refactoriser les interfaces |
| Ensemble de données | Ajouter un ensemble de données |
| Modèles | Implémenter un nouveau modèle, quelques instructions pour contribuer aux modèles |
Les bons premiers numéros sont étiquetés pour indiquer qu'ils sont faciles à démarrer vos contributions.
Vous pouvez trouver une implémentation imparfaite dans Qlib en rg 'TODO|FIXME' qlib
Si vous souhaitez devenir l'un des responsables de Qlib pour contribuer davantage (par exemple, aider à fusionner les relations publiques, trier les problèmes), veuillez nous contacter par e-mail ([email protected]). Nous sommes heureux de vous aider à mettre à niveau votre autorisation.
La plupart des contributions nécessitent que vous acceptiez un contrat de licence de contributeur (CLA) déclarant que vous avez le droit de nous accorder, et que vous nous accordez effectivement le droit d'utiliser votre contribution. Pour plus de détails, visitez https://cla.opensource.microsoft.com.
Lorsque vous soumettez une pull request, un robot CLA déterminera automatiquement si vous devez fournir un CLA et décorera le PR de manière appropriée (par exemple, vérification du statut, commentaire). Suivez simplement les instructions fournies par le bot. Vous n’aurez besoin de le faire qu’une seule fois pour tous les dépôts utilisant notre CLA.
Ce projet a adopté le code de conduite Microsoft Open Source. Pour plus d’informations, consultez la FAQ sur le code de conduite ou contactez [email protected] pour toute question ou commentaire supplémentaire.


