EasyLLMOps
1.0.0
EasyLLMOps : MLOps sans effort pour des modèles de langage puissants.
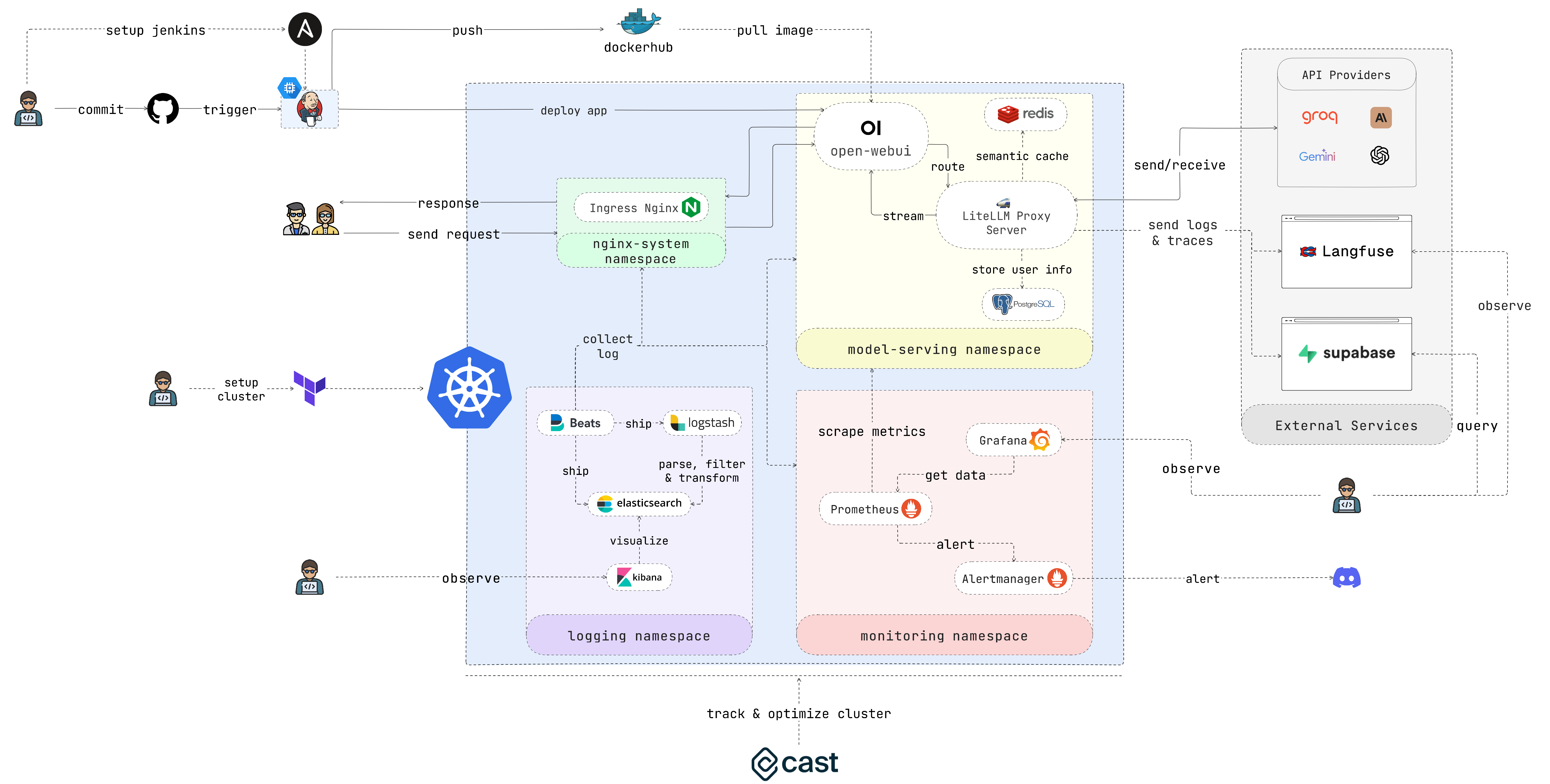
EasyLLMOps est un projet construit avec Open WebUI qui peut être déployé sur Google Kubernetes Engine (GKE) pour gérer et faire évoluer les modèles de langage. Il propose à la fois des méthodes de déploiement Terraform et manuelles, et intègre des pratiques MLOps robustes. Cela inclut des pipelines CI/CD avec Jenkins et Ansible pour l'automatisation, la surveillance avec Prometheus et Grafana pour des informations sur les performances et une journalisation centralisée avec la pile ELK pour le dépannage et l'analyse. Les développeurs peuvent trouver une documentation détaillée et des instructions sur le site Web du projet.
Développeurs créant et déployant des applications basées sur LLM. Scientifiques des données et ingénieurs en apprentissage automatique travaillant avec des LLM. Équipes DevOps responsables de la gestion de l’infrastructure LLM. Organisations cherchant à intégrer des LLM dans leurs opérations.
Si vous ne souhaitez pas y consacrer beaucoup de temps, exécutez ce script et profitez de votre café :
chmod +x ./cluster.sh
./cluster.shN'oubliez pas de vous authentifier auprès de GCP avant d'utiliser Terraform :
gcloud auth application-default loginCette section fournit un guide de démarrage très rapide pour que l'application soit opérationnelle dès que possible. Veuillez vous référer aux sections suivantes pour des instructions plus détaillées.
1. Configurez le cluster :
Si vous déployez l'application sur GKE, vous pouvez utiliser Terraform pour automatiser la configuration de votre cluster Kubernetes. Accédez au répertoire iac/terraform et initialisez Terraform :
cd iac/terraform
terraform initPlanifier et appliquer la configuration :
Générez un plan d'exécution pour vérifier les ressources que Terraform va créer ou modifier, puis appliquez la configuration pour configurer le cluster :
terraform plan
terraform apply2. Récupérez les informations sur le cluster :
Pour interagir avec votre cluster GKE, vous devrez récupérer sa configuration. Vous pouvez afficher la configuration actuelle du cluster avec la commande suivante :
cat ~ /.kube/config Assurez-vous que votre contexte kubectl est correctement défini pour gérer le cluster.
Pour un processus de déploiement plus pratique, procédez comme suit :
1. Déployez le contrôleur d'entrée Nginx :
Le contrôleur d'entrée Nginx gère l'accès externe aux services de votre cluster Kubernetes. Créez un espace de noms et installez le contrôleur d'entrée à l'aide de Helm :
kubectl create ns nginx-system
kubens nginx-system
helm upgrade --install nginx-ingress ./deployments/nginx-ingressVeuillez indiquer l'adresse IP du contrôleur d'entrée Nginx, car vous en aurez besoin plus tard.
2. Configurez le secret de la clé API :
Stockez vos variables d'environnement, telles que les clés API, en toute sécurité dans les secrets Kubernetes. Créez un espace de noms pour la diffusion du modèle et créez un secret à partir de votre fichier .env :
kubectl create ns model-serving
kubens model-serving
kubectl delete secret easyllmops-env
kubectl create secret generic easyllmops-env --from-env-file=.env -n model-serving
kubectl describe secret easyllmops-env -n model-serving3. Accorder des autorisations :
Les ressources Kubernetes nécessitent souvent des autorisations spécifiques. Appliquez les rôles et les liaisons nécessaires :
cd deployments/infrastructure
kubectl apply -f role.yaml
kubectl apply -f rolebinding.yaml4. Déployez le service de mise en cache à l'aide de Redis :
Maintenant, déployez le service de mise en cache sémantique à l'aide de Redis :
cd ./deployments/redis
helm dependency build
helm upgrade --install redis .5. Déployez LiteLLM :
Déployez le service LiteLLM :
kubens model-serving
helm upgrade --install litellm ./deployments/litellm6. Déployez l'Open WebUI :
Ensuite, déployez l'interface utilisateur Web sur votre cluster GKE :
cd open-webui
kubectl apply -f ./kubernetes/manifest/base -n model-serving7. Jouez avec l'application :
Ouvrez le navigateur et accédez à l'URL de votre cluster GKE (par exemple http://172.0.0.0 à l'étape 1) et ajoutez .nip.io à la fin de l'URL (par exemple http://172.0.0.0.nip.io ). . Vous devriez voir l'Open WebUI :
Pour les pipelines CI/CD automatisés, utilisez Jenkins et Ansible comme suit :
1. Configurez le serveur Jenkins :
Tout d’abord, créez un compte de service et attribuez-lui le rôle Compute Admin . Créez ensuite un fichier de clé Json pour le compte de service et stockez-le dans le répertoire iac/ansible/secrets .
Créez ensuite une instance Google Compute Engine nommée "jenkins-server" exécutant Ubuntu 22.04 avec une règle de pare-feu autorisant le trafic sur les ports 8081 et 50000.
ansible-playbook iac/ansible/deploy_jenkins/create_compute_instance.yamlDéployez Jenkins sur un serveur en installant les prérequis, en extrayant une image Docker et en créant un conteneur privilégié avec accès au socket Docker et aux ports exposés 8081 et 50000.
ansible-playbook -i iac/ansible/inventory iac/ansible/deploy_jenkins/deploy_jenkins.yaml2. Accédez à Jenkins :
Pour accéder au serveur Jenkins via SSH, nous devons créer une paire de clés publique/privée. Exécutez la commande suivante pour créer une paire de clés :
ssh-keygen Ouvrez Metadata et copiez la valeur ssh-keys .
Nous devons trouver le mot de passe du serveur Jenkins pour pouvoir accéder au serveur. Tout d'abord, accédez au serveur Jenkins :
ssh < USERNAME > : < EXTERNAL_IP >Exécutez ensuite la commande suivante pour obtenir le mot de passe :
sudo docker exec -it jenkins-server bash
cat /var/jenkins_home/secrets/initialAdminPasswordUne fois Jenkins déployé, accédez-y via votre navigateur :
http://<EXTERNAL_IP>:8081
3. Installez les plugins Jenkins :
Installez les plugins suivants pour intégrer Jenkins à Docker, Kubernetes et GKE :
Après avoir installé les plugins, redémarrez Jenkins.
sudo docker restart jenkins-server4. Configurez Jenkins :
4.1. Ajoutez des webhooks à votre référentiel GitHub pour déclencher les builds Jenkins.
Accédez au référentiel GitHub et cliquez sur Settings . Cliquez sur Webhooks puis cliquez sur Add Webhook . Saisissez l'URL de votre serveur Jenkins (par exemple http://<EXTERNAL_IP>:8081/github-webhook/ ). Cliquez ensuite sur Let me select individual events et sélectionnez Let me select individual events . Sélectionnez Push and Pull Request et cliquez sur Add Webhook .
4.2. Ajoutez le référentiel Github en tant que référentiel de code source Jenkins.
Accédez au tableau de bord Jenkins et cliquez sur New Item . Entrez un nom pour votre projet (par exemple easy-llmops ) et sélectionnez Multibranch Pipeline . Cliquez sur OK . Cliquez sur Configure puis cliquez sur Add Source . Sélectionnez GitHub et cliquez sur Add . Saisissez l'URL de votre référentiel GitHub (par exemple https://github.com/bmd1905/EasyLLMOps ). Dans le champ Credentials , sélectionnez Add et sélectionnez Username with password . Entrez votre nom d'utilisateur et votre mot de passe GitHub (ou utilisez un jeton d'accès personnel). Cliquez sur Test Connection puis cliquez sur Save .
4.3. Configurez les informations d’identification du hub Docker.
Tout d’abord, créez un compte Docker Hub. Accédez au site Web Docker Hub et cliquez sur Sign Up . Entrez votre nom d'utilisateur et votre mot de passe. Cliquez sur Sign Up . Cliquez sur Create Repository . Entrez un nom pour votre référentiel (par exemple easy-llmops ) et cliquez sur Create .
Depuis le tableau de bord Jenkins, accédez à Manage Jenkins > Credentials . Cliquez sur Add Credentials . Sélectionnez Username with password et cliquez sur Add . Entrez votre nom d'utilisateur Docker Hub, votre jeton d'accès et définissez ID sur dockerhub .
4.4. Configurez les informations d'identification Kubernetes.
Tout d'abord, créez un compte de service pour le serveur Jenkins afin d'accéder au cluster GKE. Accédez à la console GCP et accédez à IAM et administrateur > Comptes de service. Créez un nouveau compte de service avec le rôle Kubernetes Engine Admin . Donnez au compte de service un nom et une description. Cliquez sur le compte de service puis cliquez sur l'onglet Keys . Cliquez sur Add Key et sélectionnez JSON comme type de clé. Cliquez sur Create et téléchargez le fichier JSON.
Ensuite, depuis le tableau de bord Jenkins, accédez à Manage Jenkins > Cloud . Cliquez sur New cloud . Sélectionnez Kubernetes . Saisissez le nom de votre cluster (par exemple gke-easy-llmops-cluster-1), enter the URL and Certificate from your GKE cluster. In the Kubernetes Namespace , enter the namespace of your cluster (eg model-serving ). In the field, select Ajouter and select Compte de service Google privé. Entrez votre identifiant de projet et le chemin d'accès au fichier JSON.
5. Testez la configuration :
Envoyez un nouveau commit vers votre référentiel GitHub. Vous devriez voir une nouvelle version dans Jenkins.
1. Créez un webhook Discord :
Tout d’abord, créez un webhook Discord. Accédez au site Web Discord et cliquez sur Server Settings . Cliquez sur Integrations . Cliquez sur Create Webhook . Entrez un nom pour votre webhook (par exemple easy-llmops-discord-webhook ) et cliquez sur Create . Copiez l'URL du webhook.
2. Configurer les référentiels Helm
Tout d’abord, nous devons ajouter les référentiels Helm nécessaires pour Prometheus et Grafana :
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo add grafana https://grafana.github.io/helm-charts
helm repo updateCes commandes ajoutent les référentiels officiels Prometheus et Grafana Helm et mettent à jour les informations de votre carte Helm locale.
3. Installer les dépendances
Prometheus nécessite certaines dépendances qui peuvent être gérées avec Helm. Accédez au répertoire de surveillance et créez ces dépendances :
helm dependency build ./deployments/monitoring/kube-prometheus-stack4. Déployer Prometheus
Nous allons maintenant déployer Prometheus et ses services associés à l'aide de Helm :
kubectl create namespace monitoring
helm upgrade --install -f deployments/monitoring/kube-prometheus-stack.expanded.yaml kube-prometheus-stack deployments/monitoring/kube-prometheus-stack -n monitoringCette commande effectue les opérations suivantes :
helm upgrade --install : Cela installera Prometheus s'il n'existe pas, ou le mettra à niveau s'il existe.-f deployments/monitoring/kube-prometheus-stack.expanded.yaml : ceci spécifie un fichier de valeurs personnalisées pour la configuration.kube-prometheus-stack : Il s'agit du nom de version pour l'installation de Helm.deployments/monitoring/kube-prometheus-stack : Il s'agit du graphique à utiliser pour l'installation.-n monitoring : ceci spécifie l'espace de noms dans lequel installer.Par défaut, les services ne sont pas exposés en externe. Pour y accéder, vous pouvez utiliser la redirection de port :
Pour Prométhée :
kubectl port-forward -n monitoring svc/kube-prometheus-stack-prometheus 9090:9090 Accédez ensuite à Prometheus sur http://localhost:9090
Pour Grafana :
kubectl port-forward -n monitoring svc/kube-prometheus-stack-grafana 3000:80 Accédez ensuite à Grafana sur http://localhost:3000
Les informations d'identification par défaut pour Grafana sont généralement :
5. Test d'alerte
Nous devons d’abord créer un exemple d’alerte. Accédez au répertoire monitoring et exécutez la commande suivante :
kubectl port-forward -n monitoring svc/alertmanager-operated 9093:9093Ensuite, dans un nouveau terminal, exécutez la commande suivante :
curl -XPOST -H " Content-Type: application/json " -d ' [
{
"labels": {
"alertname": "DiskSpaceLow",
"severity": "critical",
"instance": "server02",
"job": "node_exporter",
"mountpoint": "/data"
},
"annotations": {
"summary": "Disk space critically low",
"description": "Server02 has only 5% free disk space on /data volume"
},
"startsAt": "2023-09-01T12:00:00Z",
"generatorURL": "http://prometheus.example.com/graph?g0.expr=node_filesystem_free_bytes+%2F+node_filesystem_size_bytes+%2A+100+%3C+5"
},
{
"labels": {
"alertname": "HighMemoryUsage",
"severity": "warning",
"instance": "server03",
"job": "node_exporter"
},
"annotations": {
"summary": "High memory usage detected",
"description": "Server03 is using over 90% of its available memory"
},
"startsAt": "2023-09-01T12:05:00Z",
"generatorURL": "http://prometheus.example.com/graph?g0.expr=node_memory_MemAvailable_bytes+%2F+node_memory_MemTotal_bytes+%2A+100+%3C+10"
}
] ' http://localhost:9093/api/v2/alertsCette commande crée un exemple d'alerte. Vous pouvez vérifier que l'alerte a été créée en exécutant la commande suivante :
curl http://localhost:9093/api/v2/statusOu, vous pouvez vérifier manuellement la chaîne Discord.
Cette configuration fournit des fonctionnalités de surveillance complètes pour votre cluster Kubernetes. Avec Prometheus collectant des métriques et Grafana les visualisant, vous pouvez suivre efficacement les performances, configurer des alertes pour les problèmes potentiels et obtenir des informations précieuses sur votre infrastructure et vos applications.
La journalisation centralisée est essentielle pour surveiller et dépanner les applications déployées sur Kubernetes. Cette section vous guide dans la configuration d'une pile ELK (Elasticsearch, Logstash, Kibana) avec Filebeat pour journaliser votre cluster GKE.
0. Exécution rapide
Vous pouvez utiliser ce script unique helmfile pour lancer la pile ELK :
cd deployments/ELK
helmfile sync1. Installez ELK Stack avec Helm
Nous utiliserons Helm pour déployer les composants de la pile ELK :
Tout d'abord, créez un espace de noms pour les composants de journalisation :
kubectl create ns logging
kubens loggingEnsuite, installez Elasticsearch :
helm install elk-elasticsearch elastic/elasticsearch -f deployments/ELK/elastic.expanded.yaml --namespace logging --create-namespaceAttendez qu'Elasticsearch soit prêt :
echo " Waiting for Elasticsearch to be ready... "
kubectl wait --for=condition=ready pod -l app=elasticsearch-master --timeout=300sCréez un secret pour que Logstash puisse accéder à Elasticsearch :
kubectl create secret generic logstash-elasticsearch-credentials
--from-literal=username=elastic
--from-literal=password= $( kubectl get secrets --namespace=logging elasticsearch-master-credentials -ojsonpath= ' {.data.password} ' | base64 -d )Installez Kibana :
helm install elk-kibana elastic/kibana -f deployments/ELK/kibana.expanded.yamlInstallez Logstash :
helm install elk-logstash elastic/logstash -f deployments/ELK/logstash.expanded.yamlInstallez Filebeat :
helm install elk-filebeat elastic/filebeat -f deployments/ELK/filebeat.expanded.yaml2. Accédez à Kibana :
Exposez Kibana à l'aide d'un service et accédez-y via votre navigateur :
kubectl port-forward -n logging svc/elk-kibana-kibana 5601:5601Veuillez utiliser ce script pour obtenir le mot de passe Kibana :
kubectl get secrets --namespace=logging elasticsearch-master-credentials -ojsonpath= ' {.data.password} ' | base64 -d Ouvrez votre navigateur et accédez à http://localhost:5601 .
3. Vérifier la collecte des journaux
Vous devriez maintenant pouvoir voir les journaux de vos pods Kubernetes dans Kibana. Vous pouvez créer des tableaux de bord et des visualisations pour analyser vos journaux et obtenir des informations sur le comportement de votre application.
Veuillez vous rendre sur Cast AI pour créer un compte gratuit et obtenir le TOKEN.
Exécutez ensuite cette ligne pour vous connecter à GKE :
curl -H " Authorization: Token <TOKEN> " " https://api.cast.ai/v1/agent.yaml?provider=gke " | kubectl apply -f - Appuyez sur I ran this script sur l'interface utilisateur de Cast AI, puis copiez le code de configuration et collez-le dans le terminal :
CASTAI_API_TOKEN= < API_TOKEN > CASTAI_CLUSTER_ID= < CASTAI_CLUSTER_ID > CLUSTER_NAME=easy-llmops-gke INSTALL_AUTOSCALER=true INSTALL_POD_PINNER=true INSTALL_SECURITY_AGENT=true LOCATION=asia-southeast1-b PROJECT_ID=easy-llmops /bin/bash -c " $( curl -fsSL ' https://api.cast.ai/v1/scripts/gke/onboarding.sh ' ) " I ran this script et j'attends la fin de l'installation.
Vous pouvez ensuite voir vos tableaux de bord sur l'interface utilisateur de Cast AI :
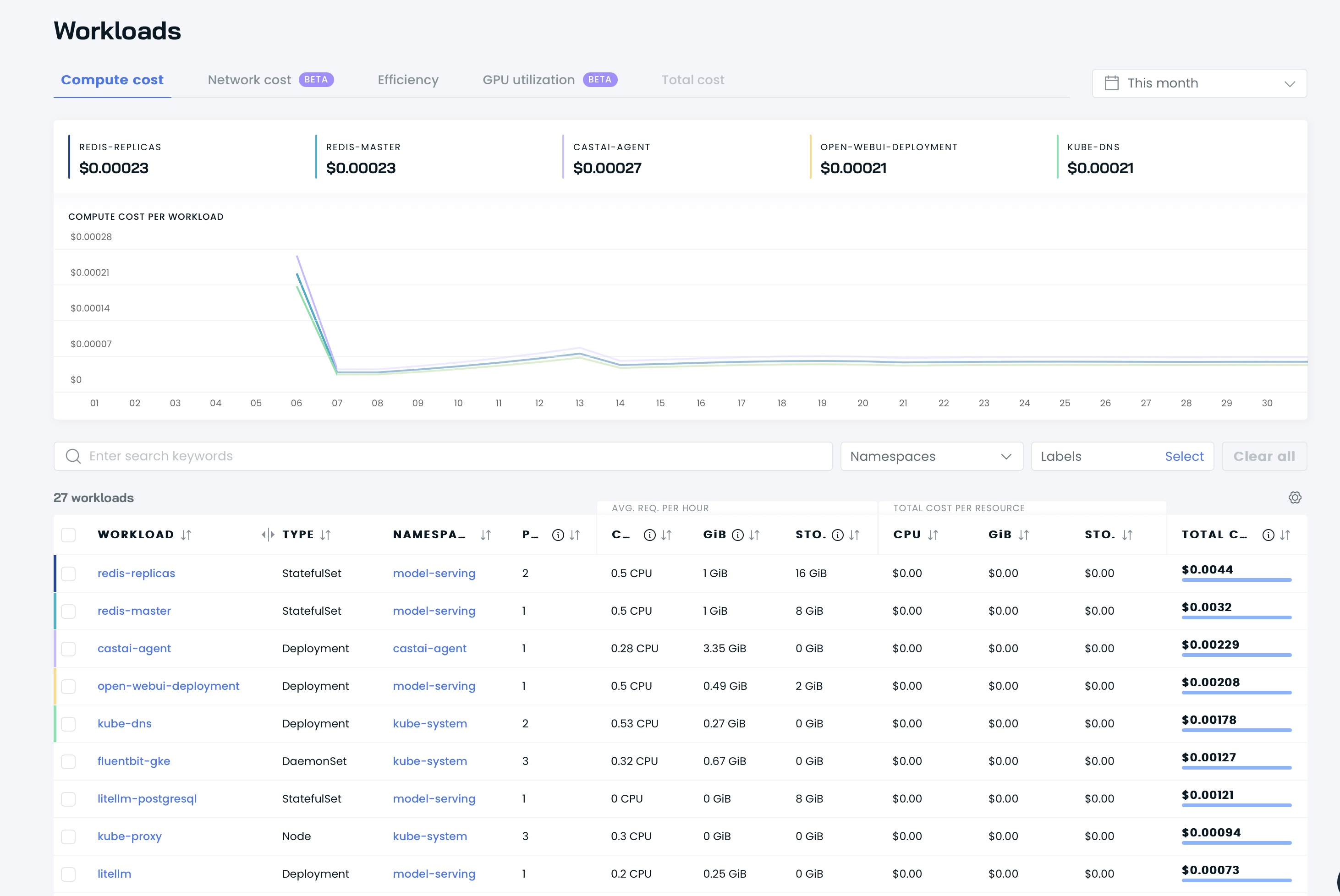
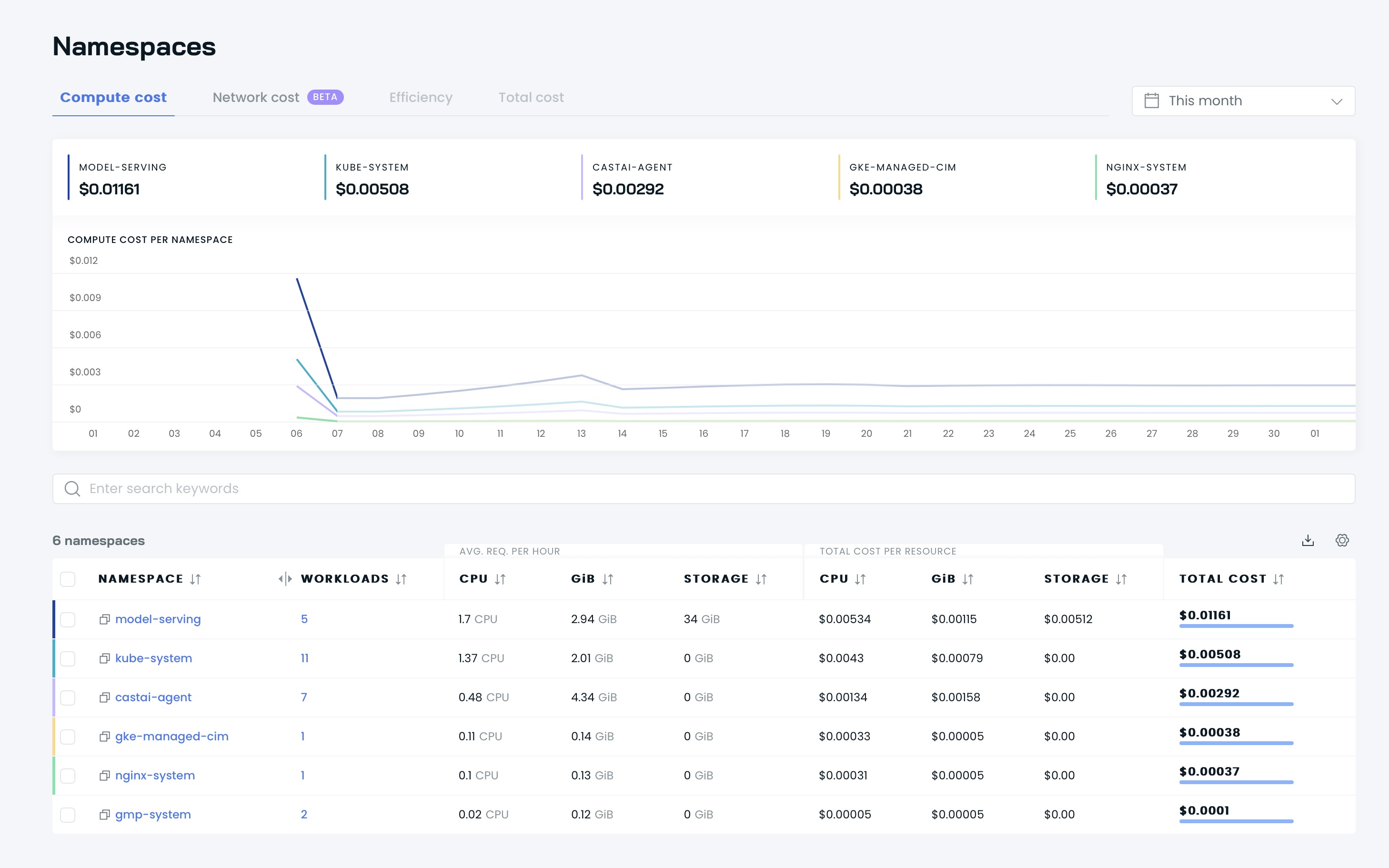
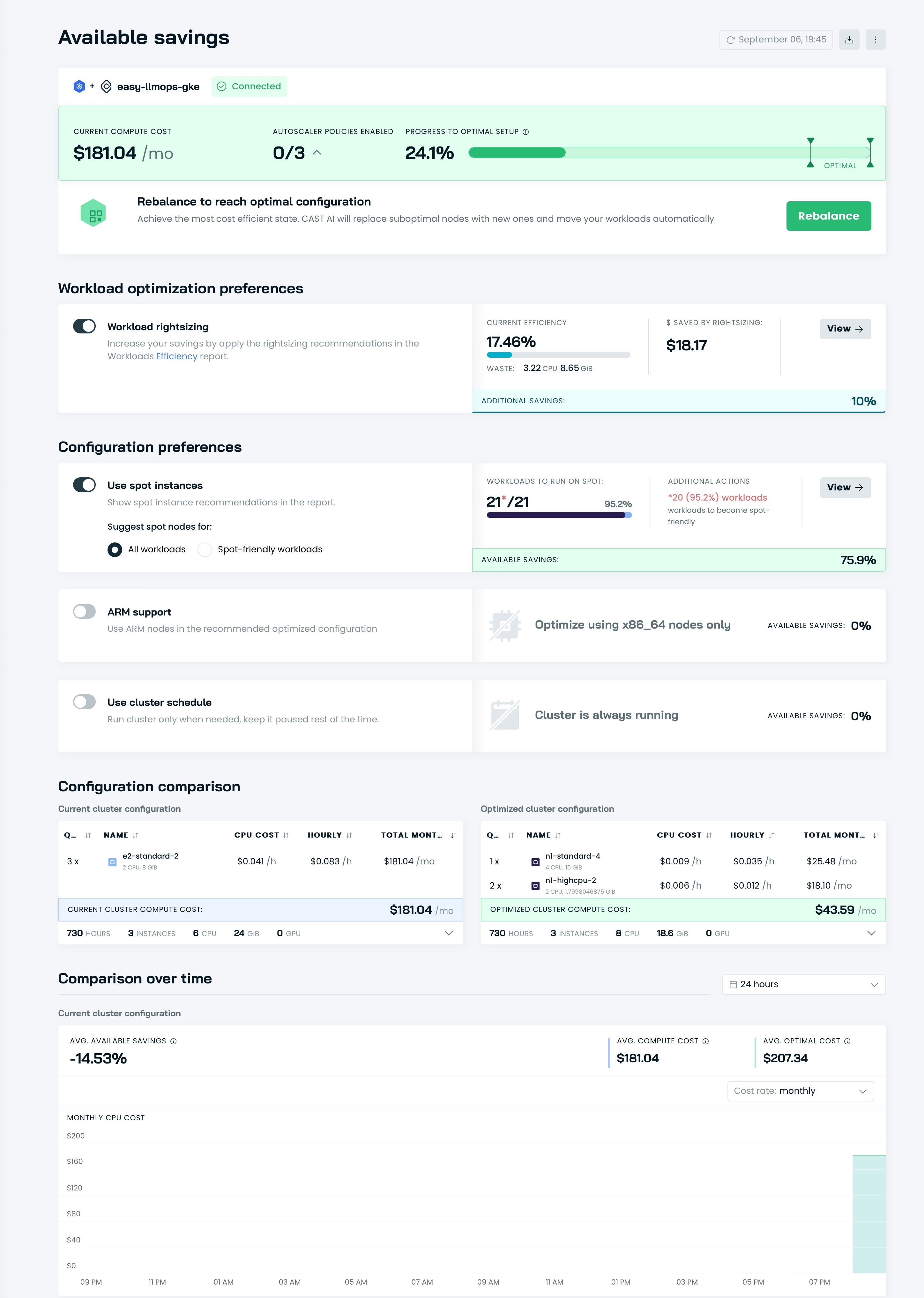
Il est temps d'optimiser votre cluster avec Cast AI ! Accédez à la section Available savings et cliquez sur le bouton Rebalance .
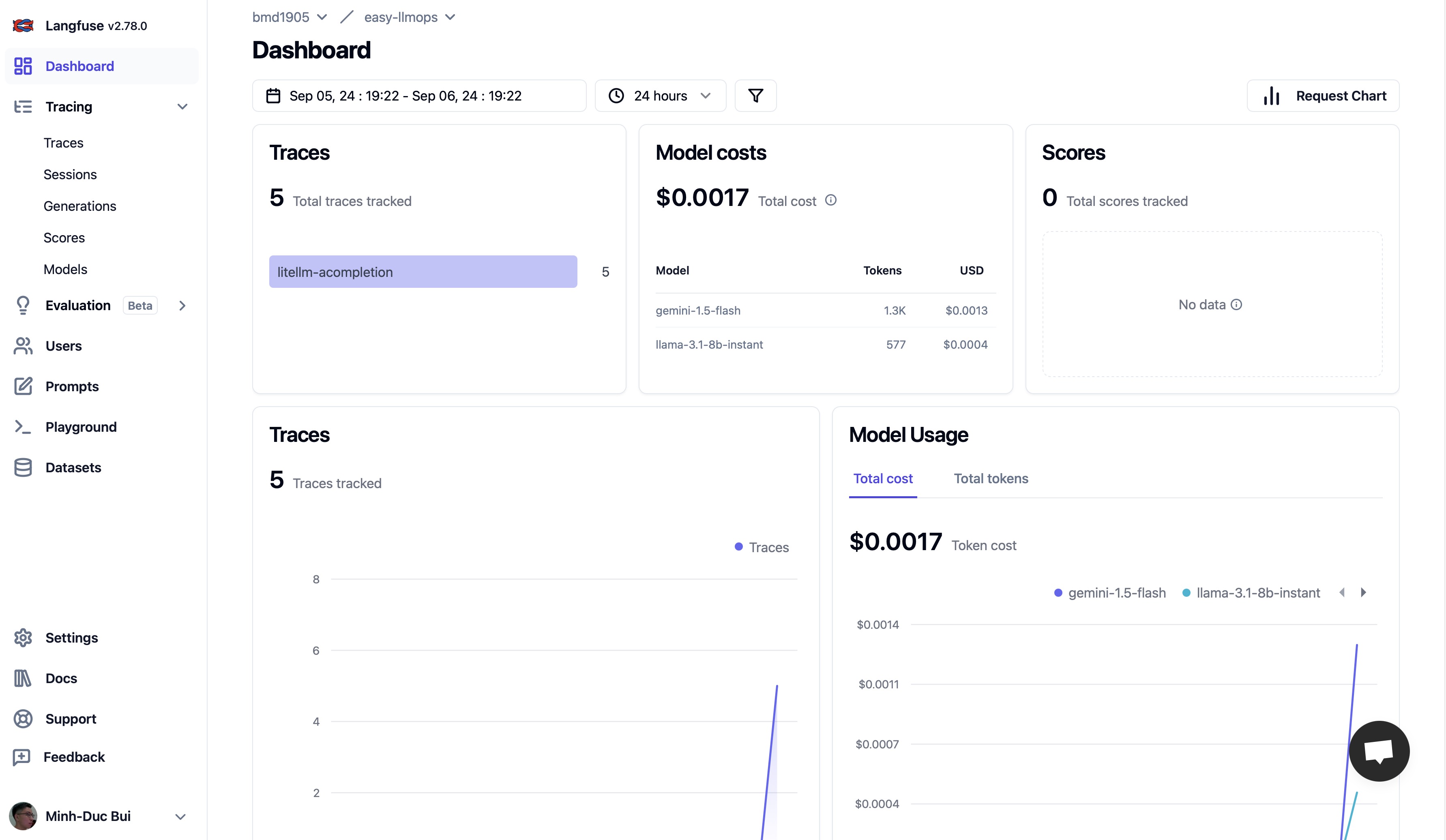
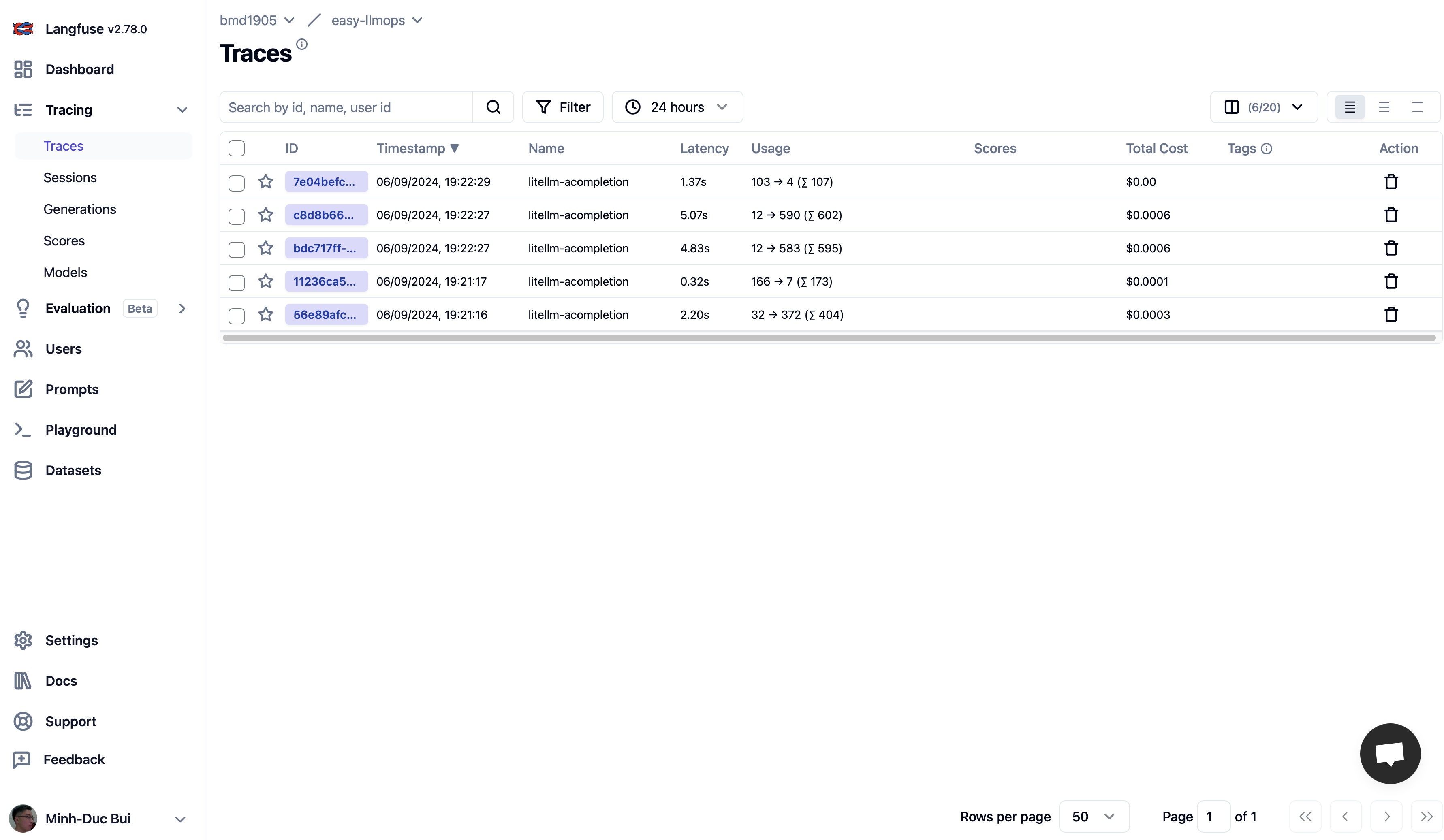
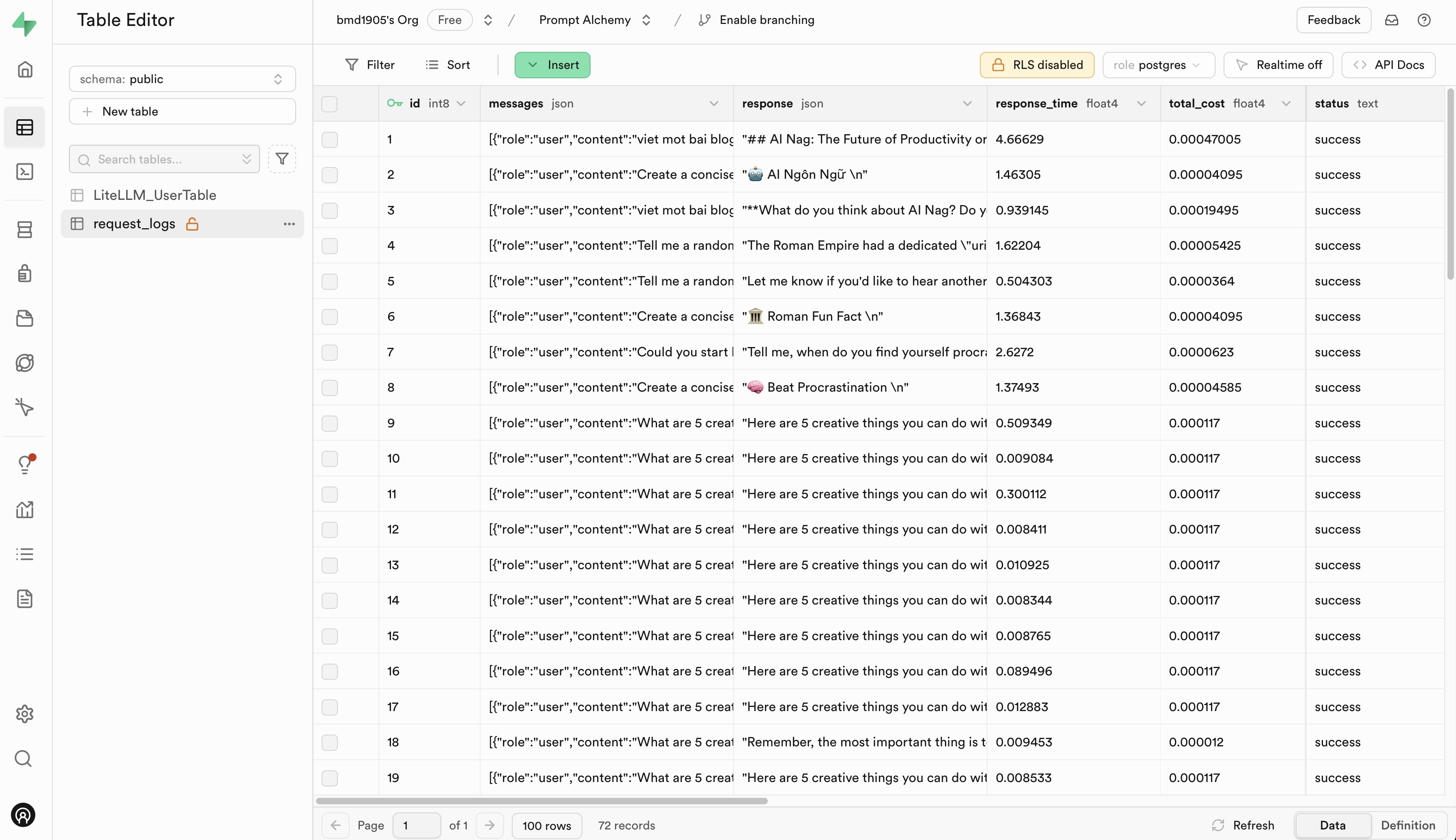
Veuillez vous rendre sur Langfuse et Supabase pour créer un compte gratuit et obtenir des clés API, puis remplacez les espaces réservés dans le fichier .env.example par vos clés API.
Nous apprécions les contributions à EasyLLMOps ! Veuillez consulter notre CONTRIBUTING.md pour plus d'informations sur la façon de commencer.
EasyLLMOps est publié sous la licence MIT. Voir le fichier LICENSE pour plus de détails.
Si vous utilisez EasyLLMOps dans votre recherche, veuillez le citer comme suit :
@software{EasyLLMOps2024,
author = {Minh-Duc Bui},
title = {EasyLLMOps: Effortless MLOps for Powerful Language Models.},
year = {2024},
url = {https://github.com/bmd1905/EasyLLMOps}
}
Pour toute question, problème ou collaboration, veuillez ouvrir un problème sur notre référentiel GitHub ou contacter directement les responsables.


