local LLM with RAG
1.0.0

Ce projet est un bac à sable expérimental permettant de tester des idées liées à l'exécution de grands modèles linguistiques (LLM) locaux avec Ollama afin d'effectuer une génération de récupération augmentée (RAG) pour répondre à des questions basées sur des exemples de PDF. Dans ce projet, nous utilisons également Ollama pour créer des intégrations avec le texte nomic-embed à utiliser avec Chroma. Veuillez noter que les intégrations sont rechargées à chaque exécution de l'application, ce qui n'est pas efficace et n'est effectué ici qu'à des fins de test.
Il existe également une interface utilisateur Web créée à l'aide de Streamlit pour offrir une manière différente d'interagir avec Ollama.
python3 -m venv .venv .source .venv/bin/activate sous Unix ou MacOS, ou ..venvScriptsactivate sous Windows.pip install -r requirements.txt . Remarque : La première fois que vous exécuterez le projet, il téléchargera les modèles nécessaires depuis Ollama pour le LLM et les intégrations. Il s'agit d'un processus de configuration unique qui peut prendre un certain temps en fonction de votre connexion Internet.
python app.py -m <model_name> -p <path_to_documents> pour spécifier un modèle et le chemin d'accès aux documents. Si aucun modèle n'est spécifié, la valeur par défaut est mistral. Si aucun chemin n'est spécifié, la valeur par défaut est Research située dans le référentiel à des fins d'exemple.-e <embedding_model_name> . S'il n'est pas spécifié, la valeur par défaut est nomic-embed-text. Cela chargera les fichiers PDF et Markdown, générera des intégrations, interrogera la collection et répondra à la question définie dans app.py .
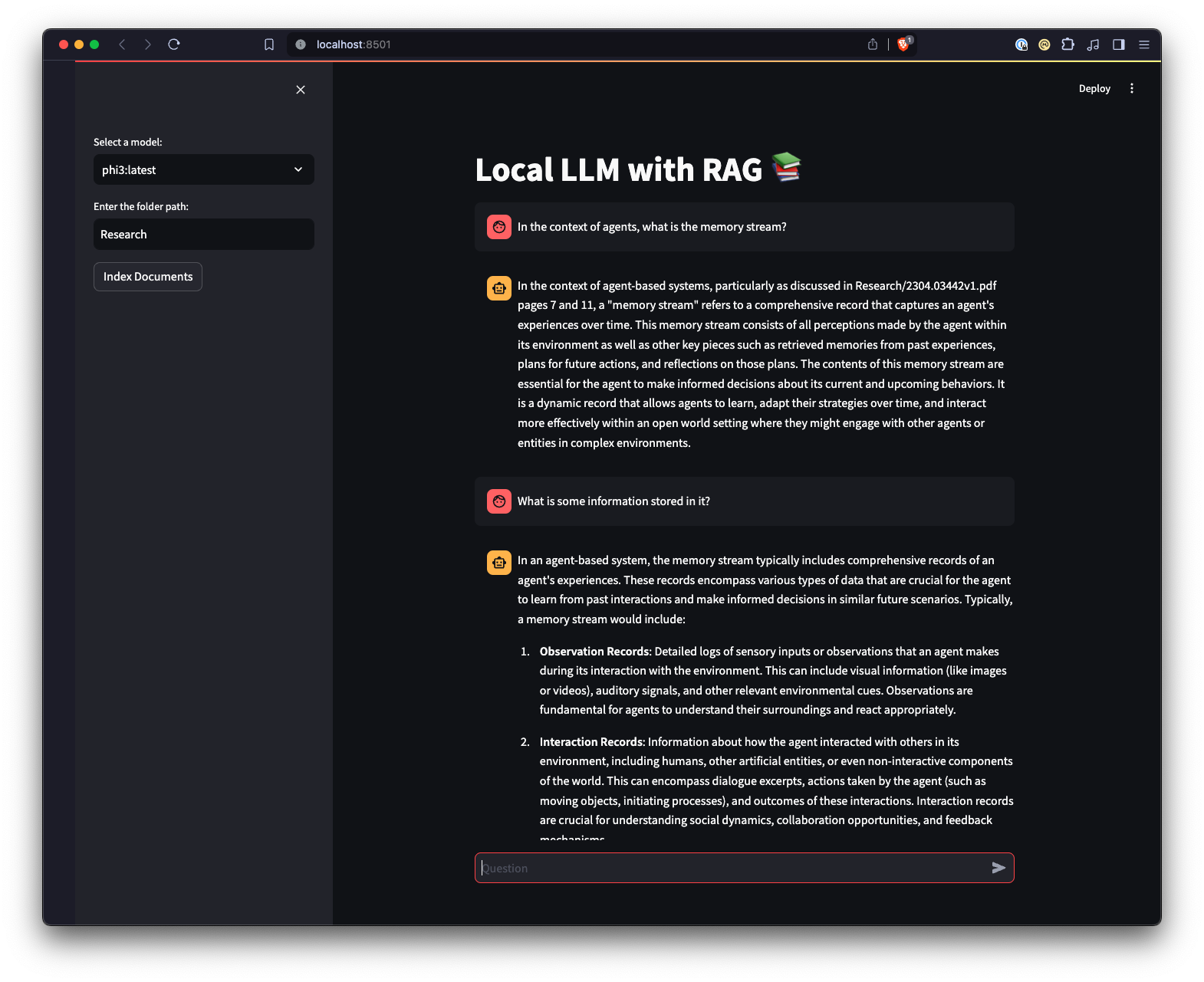
ui.pystreamlit run ui.py dans votre terminal.Cela démarrera un serveur Web local et ouvrira un nouvel onglet dans votre navigateur Web par défaut où vous pourrez interagir avec l'application. L'interface utilisateur Streamlit vous permet de sélectionner des modèles, de sélectionner un dossier, offrant ainsi un moyen plus simple et plus intuitif d'interagir avec le système de chatbot RAG par rapport à l'interface de ligne de commande. L'application gérera le chargement des documents, générera des intégrations, interrogera la collection et affichera les résultats de manière interactive.


