duplicut
v2.2 release
De nos jours, la création d’une liste de mots de passe implique généralement la concaténation de plusieurs sources de données.
Idéalement, les mots de passe les plus probables devraient figurer au début de la liste de mots, afin que les mots de passe les plus courants soient déchiffrés instantanément.
Avec les outils de déduplication existants, vous êtes obligé de choisir si vous préférez conserver l'ordre OU gérer des listes de mots massives .
Malheureusement, la création d'une liste de mots nécessite à la fois :

J'ai donc écrit duplicut en C hautement optimisé pour répondre à ce besoin très spécifique ?
git clone https://github.com/nil0x42/duplicut
cd duplicut/ && make
./duplicut wordlist.txt -o clean-wordlist.txt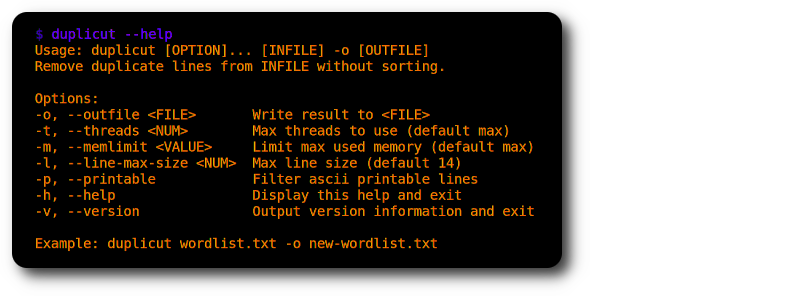
Caractéristiques :
-l )-p )Mise en œuvre :
Limites :
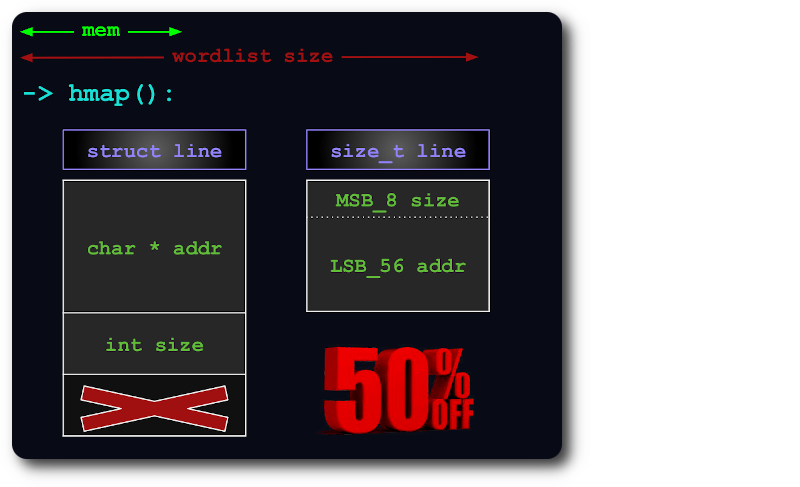
Un uint64 suffit pour indexer les lignes dans hashmap, en regroupant les informations size dans les bits supplémentaires du pointeur :
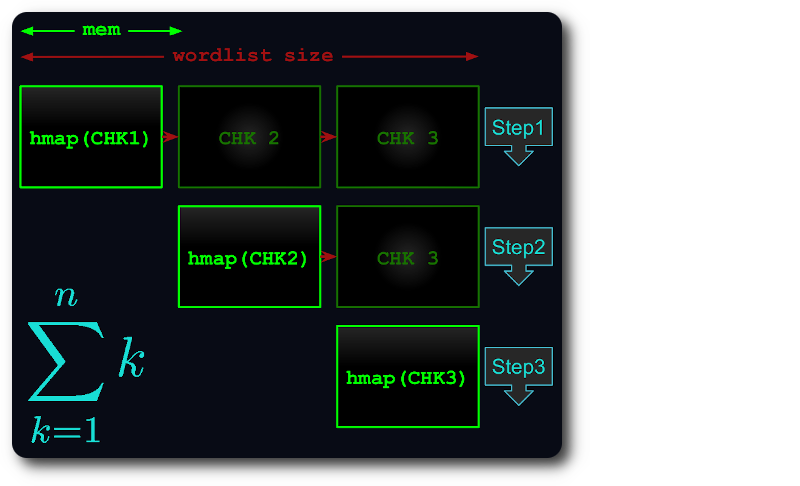
Si le fichier entier ne peut pas tenir en mémoire, il est divisé en morceaux virtuels, de telle sorte que chaque morceau utilise autant de RAM que possible.
Chaque morceau est ensuite chargé dans hashmap, dédupliqué et testé par rapport aux morceaux suivants.
De cette façon, le temps d'exécution diminue au maximum jusqu'au numéro du triangle :
Si vous trouvez un bug ou si quelque chose ne fonctionne pas comme prévu, veuillez compiler duplicut en mode débogage et publier un problème avec la sortie ci-jointe :
# debug level can be from 1 to 4
make debug level=1
./duplicut [OPTIONS] 2>&1 | tee /tmp/duplicut-debug.log


