Stock_Price_Analysis
1.0.0
Ce projet a été créé pour illustrer l'utilisation de macros développées à l'aide de VBA pour Excel pouvant être utilisées pour automatiser la collecte et la visualisation de données à partir d'un groupe sélectionné de stocks d'énergie verte. Cela a été utilisé pour montrer la capacité d'utiliser des macros et comment elles pouvaient être automatisées à l'aide d'interfaces graphiques telles que des boutons pour permettre une utilisation reproductible de la tâche. Pour ce projet, des données boursières de 12 actions collectées en 2017 et 2018 ont été utilisées. Les données utilisées comprenaient le code boursier, les valeurs boursières d'ouverture et de clôture et le volume quotidien des transactions pour chaque jour. À partir de là, nous avons pu déterminer le premier et le dernier cours de l’action ainsi que le volume global des transactions pour chaque action analysée.
Un autre objectif de ce projet était d'examiner comment améliorer l'efficacité du code en utilisant le refactoring pour optimiser la puissance de calcul nécessaire à la réalisation des macros. Pour cela, nous avons utilisé notre version initiale du code qui était fonctionnelle mais nécessitait que le programme effectue une itération de l'ensemble des données pour chaque symbole boursier que nous cherchions à analyser. L'objectif était de développer une version refactorisée du code original qui obligeait le programme à terminer uniquement lors de l'itération de l'ensemble de données et à obtenir les mêmes données que la première version.
Pour commencer, nous avons développé un code fonctionnel qui a permis de collecter le volume annuel total du stock et la performance d'une année sur l'autre de chaque stock que nous cherchions à analyser. Comme le montre le code que nous avons fourni ci-dessous, les données ont été collectées pour chaque stock en effectuant une itération de l'ensemble de données et en insérant les données dans la feuille de calcul Excel avant de passer au stock suivant.

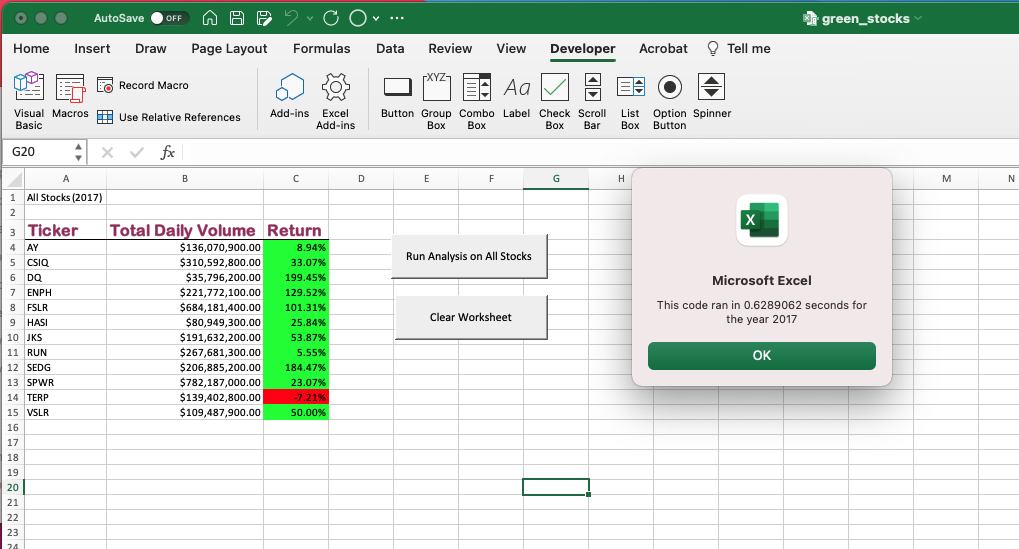
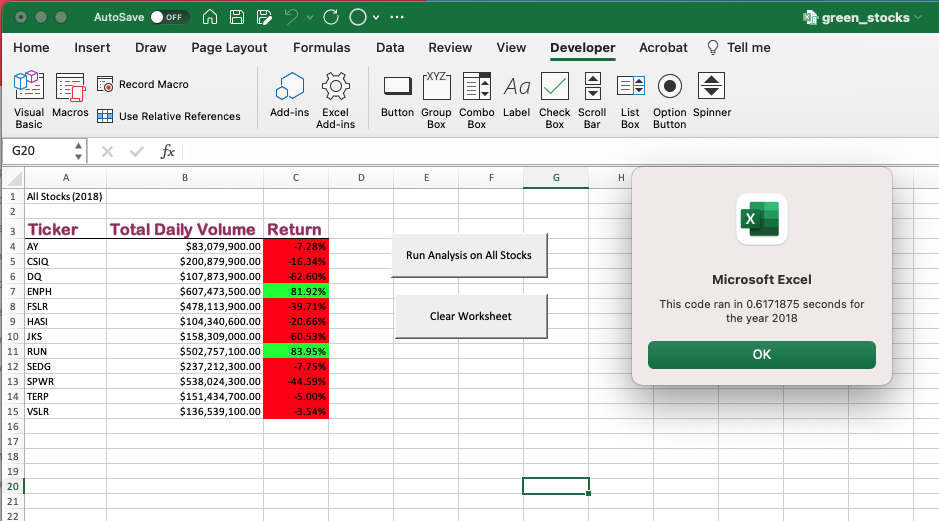
Le code contenait une minuterie qui afficherait le temps nécessaire à l'exécution du programme et afficherait les résultats. Grâce à cela, nous pouvons comparer le temps nécessaire pour compléter le code initial afin de collecter les données pour les ensembles de données de chaque année. Cela nous a fourni un temps d'exécution pour le code pour chaque année, comme le montrent les images ci-dessous. Il montre que le code initial a pris 0,6289062 secondes pour compléter l'ensemble de données de 2017 et 0,6171875 pour compléter l'ensemble de données de 2018.
Grâce à la refactorisation du code de travail d'origine, une utilisation plus efficace de l'informatique peut être réalisée en réduisant le nombre total d'itérations de l'ensemble de données, ce qui entraîne une augmentation de la vitesse d'exécution de la tâche. Pour refactoriser ce code, deux composants ont dû être ajoutés à la macro en cours de développement. Le premier était un index pour chaque ticker qui serait itéré pour chaque ligne de données dans les ensembles de données analysés. Ainsi, pour chaque ligne de données de l'ensemble de données, le programme identifierait quel ticker était présent et stockerait les données pertinentes liées à la valeur de l'index. La seconde était une collection de tableaux de données pour stocker les multiples points de données pour chaque symbole boursier. Comme chaque valeur enregistrée dans le tableau pouvait être récupérée en fonction de l'ordre dans lequel elles ont été collectées, il a été possible de lier ces données à l'index du ticker utilisé. L'utilisation de ces deux outils a permis la refactorisation du code comme le montre l'exemple ci-dessous.

En utilisant le même code que celui utilisé pour déterminer le temps d'exécution du code initial, il a été possible de voir s'il y avait une amélioration du temps d'exécution observée dans le code refactorisé pour l'analyse. Comme le montrent les images ci-dessous, le temps nécessaire pour terminer l'analyse des données de 2017 et 2018 a été calculé à l'aide du nouveau code et celui-ci a été utilisé pour comparer avec le code initial utilisé. À partir de cela, nous avons pu voir qu'il a fallu 0,5273438 secondes pour compléter l'ensemble de données de 2017 et 0,516825 secondes pour compléter l'ensemble de données de 2018.
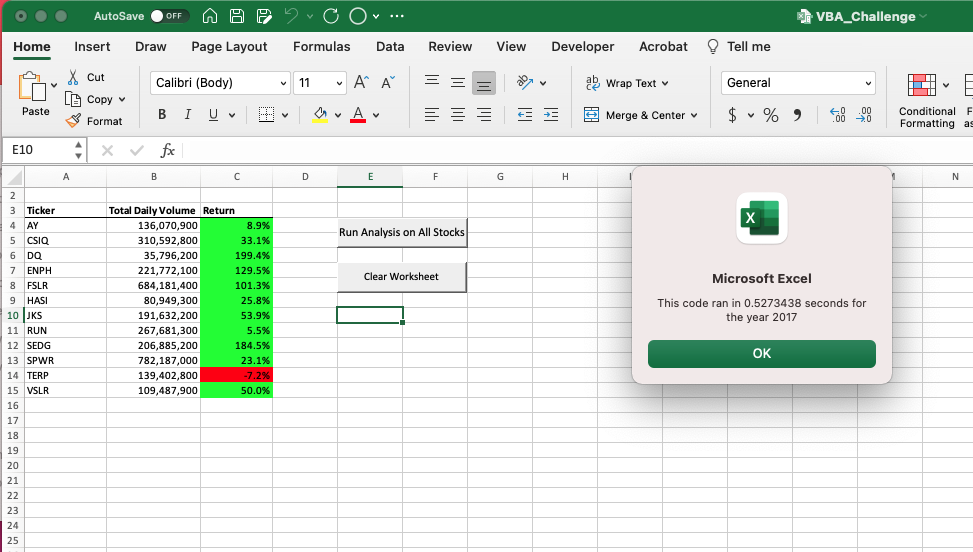
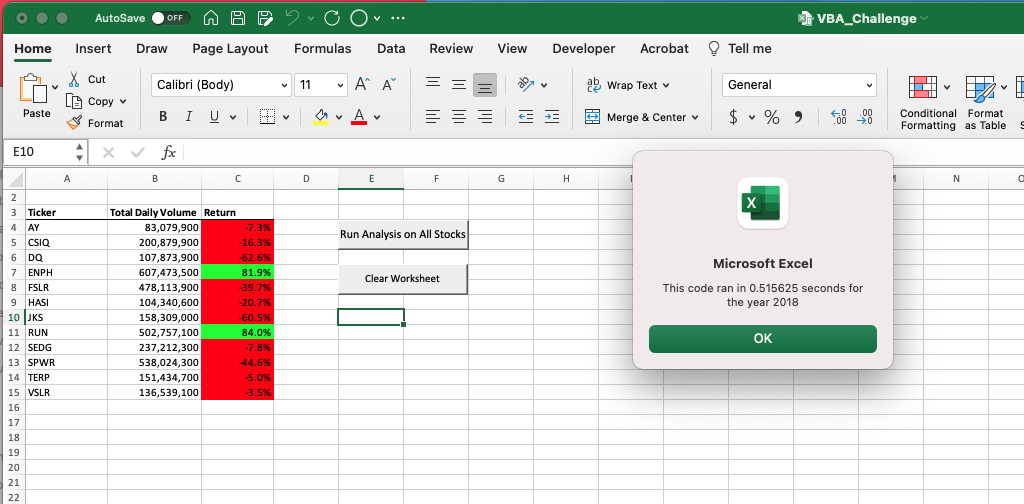
À partir des informations collectées sur la base du temps nécessaire pour terminer l'exécution du code initial et refactorisé, il y a eu une réduction de 0,1015624 s pour l'ensemble de données 2017 et de 0,1103625 s pour l'ensemble de données 2018.
Le processus de refactorisation du code présente certains avantages et inconvénients pour son utilisation. Examinons d’abord certains des avantages
Certains des inconvénients de l’utilisation de la refactorisation du code.
Dans l'exemple que nous avons montré ici, la refactorisation effectuée pour améliorer l'efficacité du code présentait des avantages et des inconvénients.
Certaines des idées positives qui ont résulté du changement du code sont les suivantes :
Réduction du temps nécessaire pour terminer l'analyse en réduisant le nombre d'itérations effectuées pour collecter les données.
Résultat : un code plus robuste qui peut être facilement étendu à des ensembles de données plus volumineux et à davantage de critères de recherche.
Tableaux utilisés pour stocker des données qui peuvent être utilisées pour d'autres calculs ou analyses si une analyse plus approfondie des données était nécessaire
Certains des facteurs négatifs pour l'utilisation du refactoring dans ce code sont les suivants
https://www.c-sharpcorner.com/article/pros-and-cons-of-code-refactoring/" ↩ ↩ 2


