LLaMA_MPS
1.0.0
Exécutez l’inférence LLaMA (et Stanford-Alpaca) sur les GPU Apple Silicon.
Comme vous pouvez le constater, contrairement aux autres LLM, LLaMA n’est en aucun cas biaisé ?
1. Clonez ce dépôt
git clone https://github.com/jankais3r/LLaMA_MPS
2. Installez les dépendances Python
cd LLaMA_MPS
pip3 install virtualenv
python3 -m venv env
source env/bin/activate
pip3 install -r requirements.txt
pip3 install -e . 3. Téléchargez les poids du modèle et placez-les dans un dossier appelé models (par exemple, LLaMA_MPS/models/7B ).
4. (Facultatif) Repartir les poids du modèle (13B/30B/65B)
Puisque nous exécutons l'inférence sur un seul GPU, nous devons fusionner les poids des modèles plus grands en un seul fichier.
mv models/13B models/13B_orig
mkdir models/13B
python3 reshard.py 1 models/13B_orig models/13B5. Exécutez l'inférence
python3 chat.py --ckpt_dir models/13B --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
Les étapes ci-dessus vous permettront d'exécuter l'inférence sur le modèle LLaMA brut en mode « saisie semi-automatique ».
Si vous souhaitez essayer le mode « instruction-réponse » similaire à ChatGPT en utilisant les poids affinés de Stanford Alpaca, poursuivez la configuration en suivant les étapes suivantes :
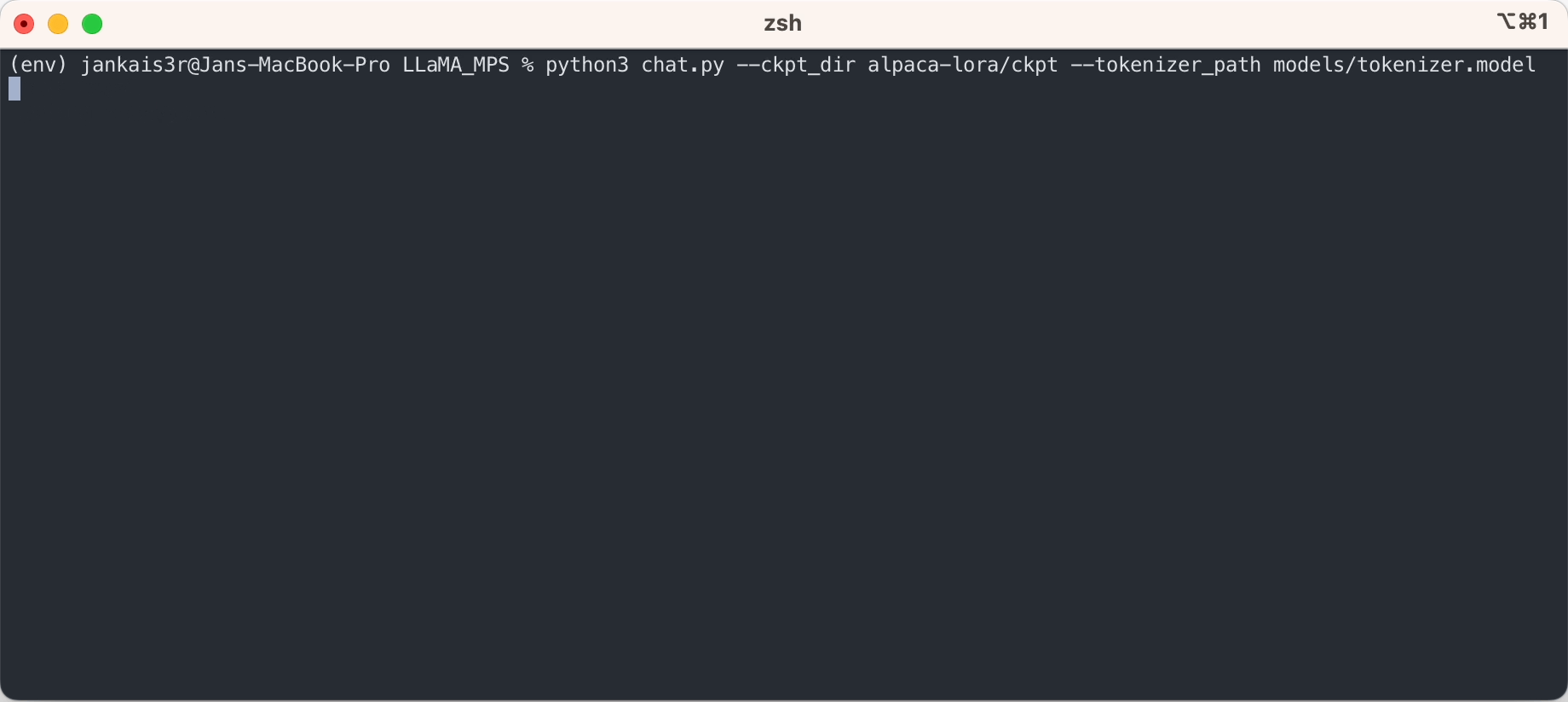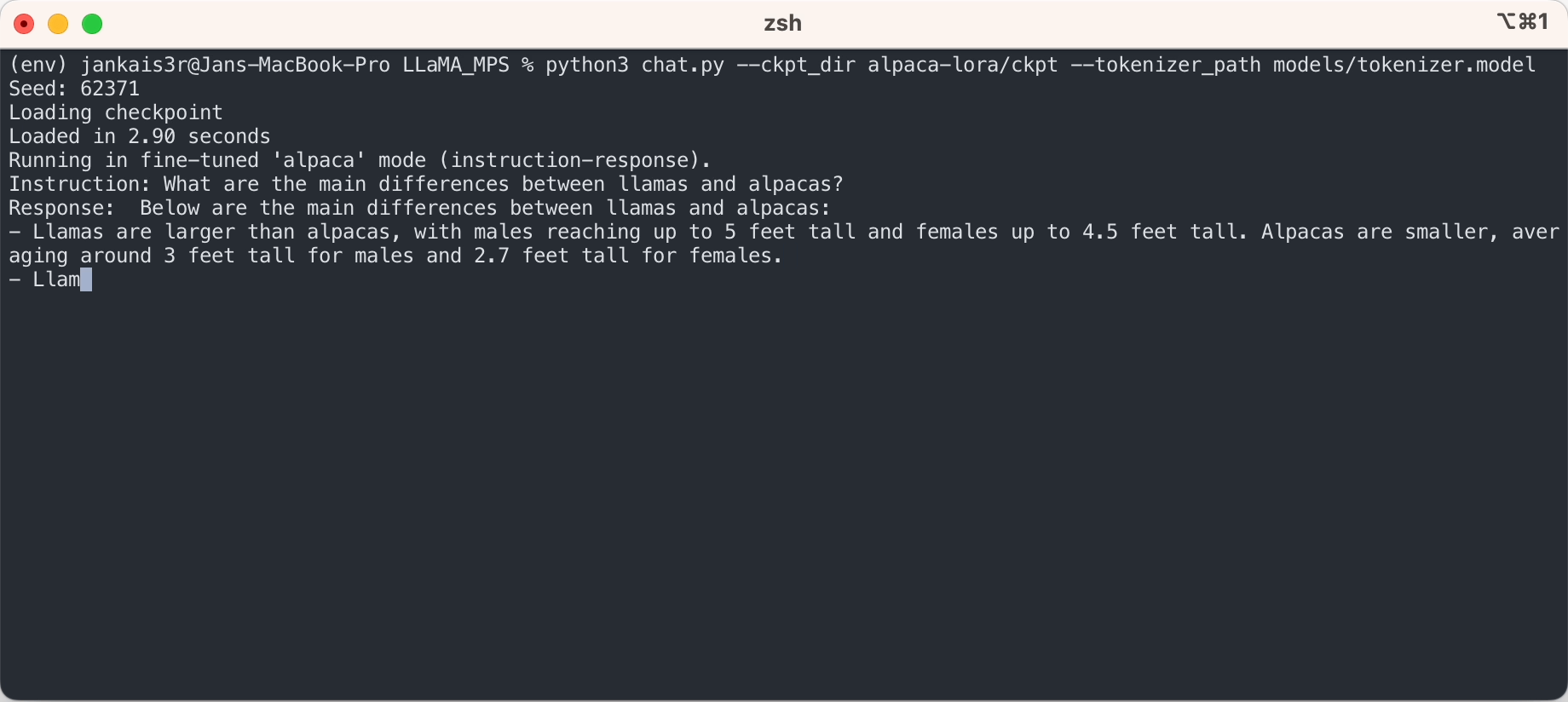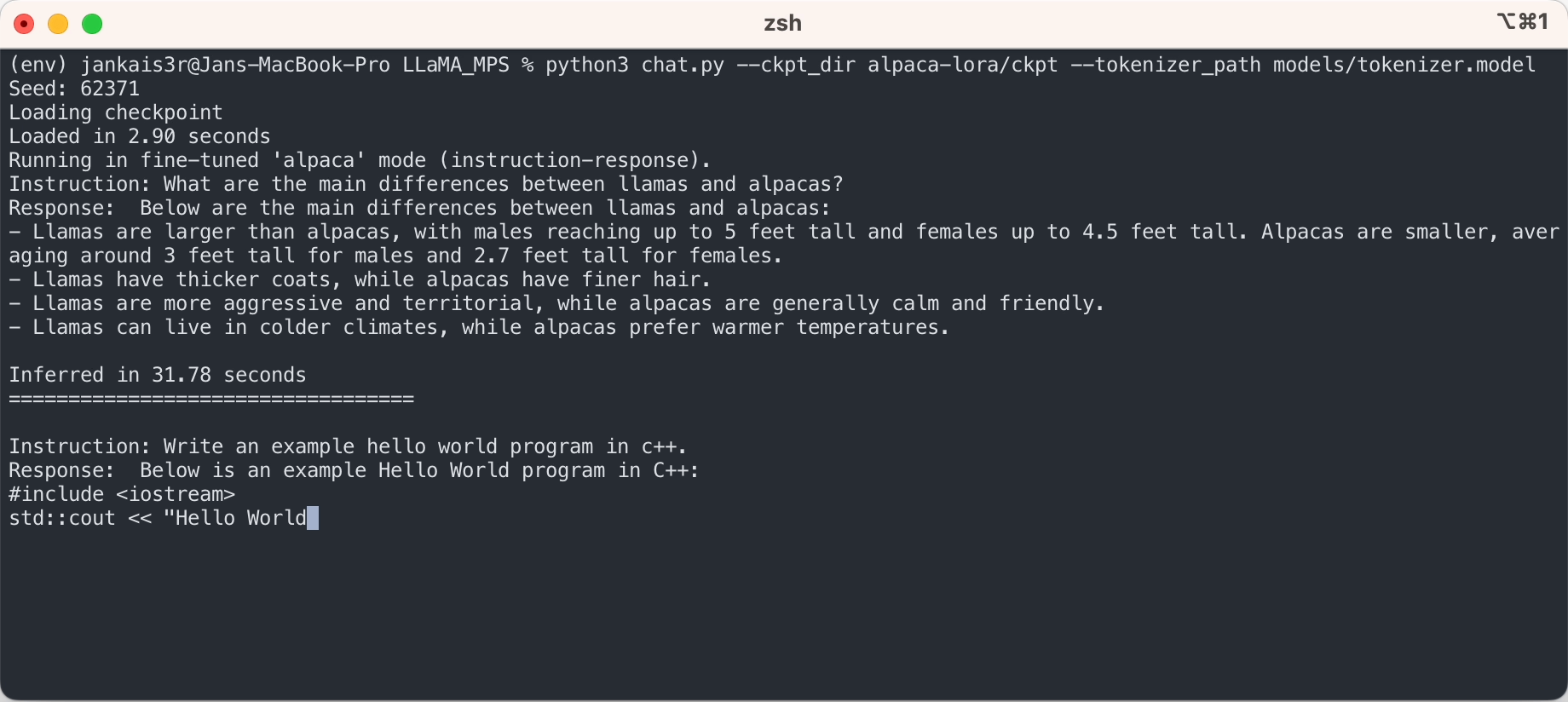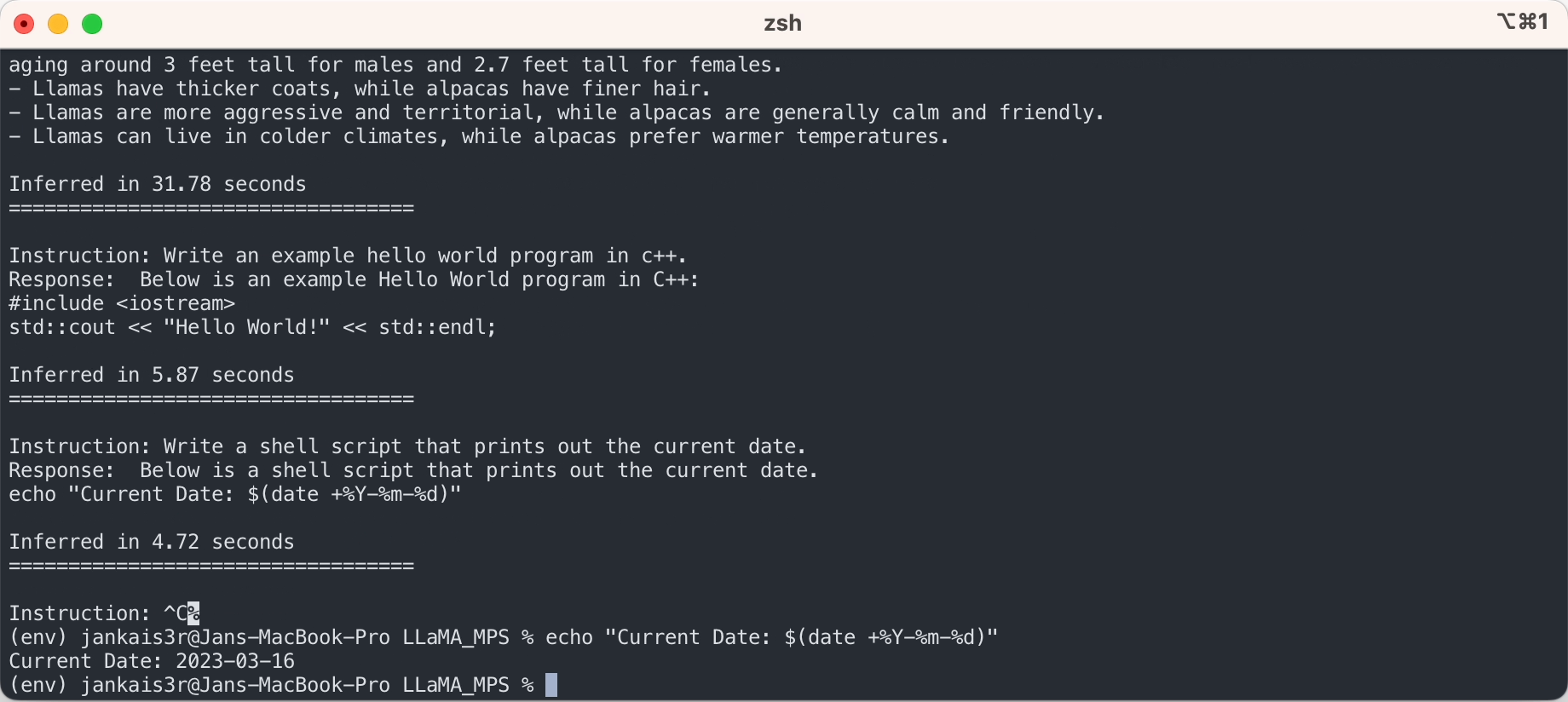
3. Téléchargez les poids affinés (disponibles pour 7B/13B)
python3 export_state_dict_checkpoint.py 7B
python3 clean_hf_cache.py4. Exécutez l'inférence
python3 chat.py --ckpt_dir models/7B-alpaca --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
| Modèle | Démarrage de la mémoire pendant l'inférence | Mémoire maximale lors de la conversion du point de contrôle | Mémoire maximale pendant le reharding |
|---|---|---|---|
| 7B | 16 GB | 14 Go | N / A |
| 13B | 32 Go | 37 Go | 45 Go |
| 30B | 66 Go | 76 Go | 125 Go |
| 65B | ?? FR | ?? FR | ?? FR |
Spécifications minimales par modèle (lentes en raison de l'échange) :
Spécifications recommandées par modèle :
- max_batch_size
Si vous disposez de mémoire disponible (par exemple, lors de l'exécution du modèle 13B sur un Mac de 64 Go), vous pouvez augmenter la taille du lot en utilisant l'argument --max_batch_size=32 . La valeur par défaut est 1 .
- max_seq_len
Pour augmenter/diminuer la longueur maximale du texte généré, utilisez l'argument --max_seq_len=256 . La valeur par défaut est 512 .
- use_repetition_penalty
L'exemple de script pénalise le modèle générant un contenu répétitif. Cela devrait conduire à une sortie de meilleure qualité, mais cela ralentit légèrement l'inférence. Exécutez le script avec l'argument --use_repetition_penalty=False pour désactiver l'algorithme de pénalité.
La meilleure alternative à LLaMA_MPS pour les utilisateurs d'Apple Silicon est llama.cpp, qui est une réimplémentation C/C++ qui exécute l'inférence uniquement sur la partie CPU du SoC. Étant donné que le code C compilé est beaucoup plus rapide que Python, il peut en fait battre cette implémentation MPS en termes de vitesse, mais au prix d'une efficacité énergétique et thermique bien pire.
Consultez la comparaison ci-dessous pour décider quelle implémentation correspond le mieux à votre cas d'utilisation.
| Mise en œuvre | Durée d'exécution totale - 256 jetons | Jetons/s | Utilisation maximale de la mémoire | Température maximale du SoC | Consommation électrique maximale du SoC | Jetons par 1 Wh |
|---|---|---|---|---|---|---|
| LAMA_MPS (13B fp16) | 75 s | 3.41 | 30 Go | 79 °C | 10 W | 1 228,80 |
| lama.cpp (13B fp16) | 70 s | 3,66 | 25 Go | 106 °C | 35 W | 376.16 |


