dream
v1.13.0
DeepPavlov Dream est une plateforme de création d'assistants d'IA génératifs multi-compétences.
Pour en savoir plus sur la plateforme et comment créer des assistants IA avec elle, veuillez visiter Dream. Si vous souhaitez en savoir plus sur l'agent DeepPavlov qui alimente Dream, visitez la documentation de l'agent DeepPavlov.
Nous avons déjà inclus six distributions : quatre d'entre elles sont basées sur le socialbot léger Deepy, une est un chatbot Dream de taille réelle (basé sur la version Alexa Prize Challenge) en anglais et un chatbot Dream en russe.
Version de base de l'assistant lunaire. Deepy Base contient un annotateur de prétraitement orthographique, une compétence de maintenance Harvesters basée sur un modèle et une compétence de programmation en domaine ouvert basée sur AIML basée sur Dialog Flow Framework.
Version avancée de l'assistant lunaire. Deepy Advanced contient des annotateurs de prétraitement orthographique, de segmentation de phrases, de liaison d'entités et de capture d'intentions, de compétences GoBot de maintenance de Harvesters pour des réponses orientées vers des objectifs et de compétences de programme en domaine ouvert basées sur AIML et basées sur le cadre de flux de dialogue.
Version FAQ de l'assistant lunaire. Deepy FAQ contient un annotateur de prétraitement orthographique, une compétence de questions fréquemment posées basée sur un modèle et une compétence de programme à domaine ouvert basée sur AIML basée sur Dialog Flow Framework.
Version orientée objectifs de l'assistant lunaire. Deepy GoBot Base contient un annotateur de prétraitement orthographique, la compétence GoBot de maintenance des moissonneurs pour des réponses orientées vers les objectifs et une compétence Program-y à domaine ouvert basée sur AIML basée sur le cadre de flux de dialogue.
Version complète de DeepPavlov Dream Socialbot. Il s'agit presque de la même version du socialbot DREAM qu'à la fin de l'Alexa Prize Challenge 4. Certains services API sont remplacés par des modèles pouvant être entraînés. Certains services (par exemple News Annotator, Game Skill, Weather Skill) nécessitent des clés privées pour les API sous-jacentes, la plupart d'entre elles peuvent être obtenues gratuitement. Si vous souhaitez utiliser ces services dans des déploiements locaux, ajoutez vos clés aux variables d'environnement (par exemple, ./.env , ./.env_ru ). Cette version de Dream Socialbot est très consommatrice de ressources du fait de son architecture modulaire et de ses objectifs originaux (participation à Alexa Prize Challenge). Nous proposons une démo de Dream Socialbot sur notre site Web.
Version mini de DeepPavlov Dream Socialbot. Il s'agit d'un socialbot génératif qui utilise le modèle anglais DialoGPT pour générer la plupart des réponses. Il contient également des composants de capture d'intention et de répondeur pour répondre aux demandes spéciales des utilisateurs. Lien vers la distribution.
Version russe de DeepPavlov Dream Socialbot. Il s'agit d'un socialbot génératif qui utilise le Russian DialoGPT de DeepPavlov pour générer la plupart des réponses. Il contient également des composants de capture d'intention et de répondeur pour répondre aux demandes spéciales des utilisateurs. Lien vers la distribution.
Version mini de DeepPavlov Dream Socialbot avec utilisation de modèles génératifs basés sur des invites. Il s'agit d'un socialbot génératif qui utilise de grands modèles de langage pour générer la plupart des réponses. Vous pouvez télécharger vos propres invites (fichiers json) sur common/prompts, ajouter des noms d'invite à PROMPTS_TO_CONSIDER (séparés par des virgules) et les informations fournies seront utilisées dans la génération de réponses alimentée par LLM comme invite. Lien vers la distribution.
docker à partir de 20 et plus ;docker-compose v1.29.2 ; git clone https://github.com/deeppavlov/dream.git
Si vous obtenez une erreur « Autorisation refusée » lors de l'exécution de docker-compose, assurez-vous de configurer correctement votre utilisateur Docker.
docker-compose -f docker-compose.yml -f assistant_dists/deepy_base/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_adv/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_faq/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_gobot_base/docker-compose.override.yml up --build
Le moyen le plus simple d’essayer Dream est de le déployer via un proxy. Toutes les requêtes seront redirigées vers l'API DeepPavlov, vous n'aurez donc pas besoin d'utiliser de ressources locales. Voir Utilisation du proxy pour plus de détails.
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
Veuillez noter que les composants DeepPavlov Dream nécessitent beaucoup de ressources. Reportez-vous à la section des composants pour voir les exigences estimées.
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml up --build
Nous avons également inclus une configuration avec des allocations GPU pour les environnements multi-GPU :
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/test.yml up
Lorsque vous devez redémarrer un conteneur Docker particulier sans reconstruire (assurez-vous que le mappage dans assistant_dists/dream/dev.yml est correct) :
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml restart container-name
docker-compose -f docker-compose.yml -f assistant_dists/dream_persona_prompted/docker-compose.override.yml -f assistant_dists/dream_persona_prompted/dev.yml -f assistant_dists/dream_persona_prompted/proxy.yml up --build
Nous avons également inclus une configuration avec des allocations GPU pour les environnements multi-GPU.
DeepPavlov Agent propose plusieurs options d'interaction : une interface de ligne de commande, une API HTTP et un bot Telegram
Dans un onglet de terminal séparé, exécutez :
docker-compose exec agent python -m deeppavlov_agent.run agent.channel=cmd agent.pipeline_config=assistant_dists/dream/pipeline_conf.json
Entrez votre nom d'utilisateur et discutez avec Dream !
Une fois que vous avez démarré le bot, l'API de l'agent de DeepPavlov s'exécutera sur http://localhost:4242 . Vous pouvez en savoir plus sur l'API dans la documentation de l'agent DeepPavlov.
Une interface de discussion de base sera disponible sur http://localhost:4242/chat .
Actuellement, le bot Telegram est déployé à la place de l'API HTTP. Modifiez la définition command agent dans la configuration docker-compose.override.yml :
agent:
command: sh -c 'bin/wait && python -m deeppavlov_agent.run agent.channel=telegram agent.telegram_token=<TELEGRAM_BOT_TOKEN> agent.pipeline_config=assistant_dists/dream/pipeline_conf.json'
REMARQUE : traitez votre jeton Telegram comme un secret et ne le confiez pas à des référentiels publics !
Dream utilise plusieurs fichiers de configuration docker-compose :
./docker-compose.yml est la configuration principale qui comprend des conteneurs pour l'agent DeepPavlov et la base de données mongo ;
./assistant_dists/*/docker-compose.override.yml répertorie tous les composants de la distribution ;
./assistant_dists/dream/dev.yml inclut des liaisons de volume pour faciliter le débogage de Dream ;
./assistant_dists/dream/proxy.yml est une liste de conteneurs proxy.
Si vos ressources de déploiement sont limitées, vous pouvez remplacer les conteneurs par leurs copies proxy hébergées par DeepPavlov. Pour ce faire, remplacez ces définitions de conteneur dans proxy.yml , par exemple :
convers-evaluator-annotator:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8004
- SERVICE_PORT=8004
et incluez cette configuration dans votre commande de déploiement :
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
Par défaut, proxy.yml contient toutes les définitions de proxy disponibles.
Dream Architecture est présenté dans l’image suivante : 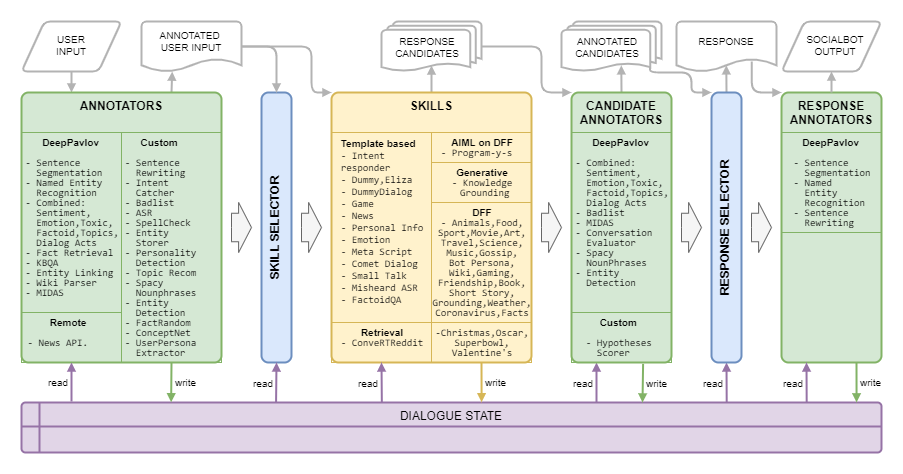
| Nom | Exigences | Description |
|---|---|---|
| Sélecteur basé sur des règles | Algorithme qui sélectionne une liste de compétences pour générer des réponses des candidats au contexte actuel en fonction de sujets, d'entités, d'émotions, de toxicité, d'actes de dialogue et d'historique de dialogue. | |
| Sélecteur de réponse | 50 Mo de RAM | Algorithme qui sélectionne une réponse finale parmi la liste donnée de réponses candidates |
| Nom | Exigences | Description |
|---|---|---|
| RSA | 40 Mo de RAM | calcule la confiance ASR globale pour un énoncé donné et le note comme très faible , faible , moyenne ou élevée (pour le balisage Amazon) |
| Mots interdits | 150 Mo de RAM | détecte les mots et les phrases de la mauvaise liste |
| Classement combiné | 1,5 Go de RAM, 3,5 Go de processeur graphique | Modèle basé sur BERT comprenant la classification des sujets, la classification des actes de dialogue, les sentiments, la toxicité, l'émotion et la classification des faits. |
| Classification combinée légère | 1,6 Go de RAM | Le même modèle que la classification combinée, mais prend 42 % de temps en moins grâce à la structure plus légère |
| COMeT atomique | 2 Go de RAM, 1,1 Go de GPU | Modèles de prédiction de bon sens COMeT Atomic |
| COMeT ConceptNet | 2 Go de RAM, 1,1 Go de GPU | Modèles de prédiction de bon sens COMeT ConceptNet |
| Annotateur évaluateur Convers | 1 Go de RAM, 4,5 Go de processeur graphique | est formé sur les données du prix Alexa des concours précédents et prédit si la réponse du candidat est intéressante, compréhensible, pertinente, engageante ou erronée |
| Classement des émotions | 2,5 Go de RAM | annotateur de classification des émotions |
| Détection d'entité | 1,5 Go de RAM, 3,2 Go de processeur graphique | extrait les entités et leurs types des énoncés |
| Liaison d'entité | 2,5 Go de RAM, 1,3 Go de processeur graphique | trouve les identifiants d'entité Wikidata pour les entités détectées avec Entity Detection |
| Stockeur d'entité | 220 Mo de RAM | un composant basé sur des règles, qui stocke les entités des déclarations de l'utilisateur et du socialbot si l'expression d'une opinion est détectée avec des modèles ou un classificateur MIDAS et les enregistre avec l'attitude détectée par rapport à l'état de dialogue |
| Fait aléatoire | 50 Mo de RAM | renvoie des faits aléatoires pour l'entité donnée (pour les entités de l'énoncé de l'utilisateur) |
| Récupération de faits | 7,4 Go de RAM, 1,2 Go de processeur graphique | extrait des faits de Wikipédia et wikiHow |
| Capteur d'intention | 1,7 Go de RAM, 2,4 Go de processeur graphique | classe les énoncés de l'utilisateur en un certain nombre d'intentions prédéfinies qui sont formées sur un ensemble de phrases et d'expressions rationnelles |
| KBQA | 2 Go de RAM, 1,4 Go de processeur graphique | répond aux questions factuelles des utilisateurs sur la base de Wikidata KB |
| Classement MIDAS | 1,1 Go de RAM, 4,5 Go de processeur graphique | Modèle basé sur BERT formé sur un sous-ensemble de classes sémantiques de l'ensemble de données MIDAS |
| Prédicteur MIDAS | 30 Mo de RAM | Modèle basé sur BERT formé sur un sous-ensemble de classes sémantiques de l'ensemble de données MIDAS |
| NER | 2,2 Go de RAM, 5 Go de GPU | extrait les noms de personnes, les noms de lieux et d'organisations à partir de texte sans casse |
| Annotateur de l'API Actualités | 80 Mo de RAM | extrait les dernières nouvelles sur les entités ou les sujets à l'aide de l'API GNews. Les déploiements DeepPavlov Dream utilisent notre propre clé API. |
| Capteur de personnalité | 30 Mo de RAM | la compétence consiste à changer la description de la personnalité du système via l'interface de discussion, cela fonctionne comme une commande système, la réponse est un message de type système |
| Sélecteur d'invite | 50 Mo de RAM | Annotateur utilisant Sentence Ranker pour classer les invites et sélectionner N_SENTENCES_TO_RETURN invites les plus pertinentes (en fonction des questions fournies dans les invites) |
| Extraction de propriété | 6,3 Gio de RAM | extrait les attributs de l'utilisateur des énoncés |
| Mots-clés de râteau | 40 Mo de RAM | extrait les mots-clés des énoncés à l'aide de l'algorithme RAKE |
| Extracteur de personnalité relative | 50 Mo de RAM | Annotateur utilisant Sentence Ranker pour classer les phrases personnelles et sélectionner N_SENTENCES_TO_RETURN les phrases les plus pertinentes |
| Sentreécrire | 200 Mo de RAM | réécrit les énoncés de l'utilisateur en remplaçant les pronoms par des noms spécifiques qui fournissent des informations plus utiles aux composants en aval |
| Sentseg | 1 Go de RAM | nous permet de gérer les énoncés longs et complexes de l'utilisateur en les divisant en phrases et en récupérant la ponctuation |
| Phrases nominales spatiales | 180 Mo de RAM | extrait les phrases nominales à l'aide de Spacy et filtre les phrases génériques |
| Classificateur de fonctions vocales | 1,1 Go de RAM, 4,5 Go de processeur graphique | un algorithme hiérarchique basé sur plusieurs modèles linéaires et une approche basée sur des règles pour la prédiction des fonctions de la parole décrites par Eggins et Slade |
| Prédicteur de la fonction vocale | 1,1 Go de RAM, 4,5 Go de processeur graphique | donne des probabilités de fonctions vocales qui peuvent suivre une fonction vocale prédite par Speech Function Classifier |
| Prétraitement orthographique | 50 Mo de RAM | composant basé sur des modèles pour réécrire différentes expressions familières dans un style de conversation plus formel |
| Recommandation de sujet | 40 Mo de RAM | propose un sujet pour une conversation plus approfondie en utilisant les informations sur les sujets discutés et les préférences de l'utilisateur. La version actuelle est basée sur les personnalités de Reddit (voir Dream Report pour Alexa Prize 4). |
| Classification toxique | 3,5 Go de RAM, 3 Go de processeur graphique | Modèle de classification toxique des transformateurs spécifiés comme PRETRAINED_MODEL_NAME_OR_PATH |
| Extracteur de personnalité d'utilisateur | 40 Mo de RAM | détermine à quelle catégorie d'âge appartient l'utilisateur en fonction de quelques mots clés |
| Analyseur Wiki | 100 Mo de RAM | extrait les triplets Wikidata pour les entités détectées avec Entity Linking |
| Faits sur les wikis | 1,7 Go de RAM | modèle qui extrait des faits connexes des pages Wikipédia et WikiHow |
| Nom | Exigences | Description |
|---|---|---|
| DialogueGPT | 1,2 Go de RAM, 2,1 Go de processeur graphique | service génératif basé sur le modèle génératif Transformers, le modèle est défini dans l'argument de composition du docker PRETRAINED_MODEL_NAME_OR_PATH (par exemple, microsoft/DialoGPT-small avec 0,2-0,5 seconde sur GPU) |
| DialoGPT basé sur la personnalité | 1,2 Go de RAM, 2,1 Go de processeur graphique | service génératif basé sur le modèle génératif Transformers, le modèle a été pré-entraîné sur l'ensemble de données PersonaChat pour générer une réponse conditionnée par plusieurs phrases du personnage du socialbot |
| Sous-titrage des images | 4 Go de RAM, 5,4 Go de processeur graphique | crée une représentation textuelle d'une image reçue |
| Remplissage | 1 Go de RAM, 1,2 Go de GPU | (désactivé mais le code est disponible) service génératif basé sur le modèle de remplissage, pour l'énoncé donné, renvoie l'énoncé où _ du texte original est remplacé par des jetons générés |
| Base de connaissances | 2 Go de RAM, 2,1 Go de GPU | service génératif basé sur l'architecture BlenderBot apportant une réponse au contexte en tenant compte d'un paragraphe de texte supplémentaire |
| LM masqué | 1,1 Go de RAM, 1 Go de GPU | (éteint mais le code est disponible) |
| Basé sur Seq2seq Persona | 1,5 Go de RAM, 1,5 Go de processeur graphique | service génératif basé sur le modèle Transformers seq2seq, le modèle a été pré-entraîné sur l'ensemble de données PersonaChat pour générer une réponse conditionnée par plusieurs phrases du personnage du socialbot |
| Classement des phrases | 1,2 Go de RAM, 2,1 Go de processeur graphique | modèle de classement donné sous la forme PRETRAINED_MODEL_NAME_OR_PATH qui, pour une paire de phrases os, renvoie un score flottant de correspondance |
| HistoireGPT | 2,6 Go de RAM, 2,15 Go de processeur graphique | un service génératif basé sur GPT-2 affiné, pour l'ensemble de mots-clés donné, renvoie une nouvelle utilisant les mots-clés |
| GPT-3.5 | 100 Mo de RAM | service génératif basé sur le service API OpenAI, le modèle est défini dans l'argument de composition docker PRETRAINED_MODEL_NAME_OR_PATH (en particulier, dans ce service, text-davinci-003 est utilisé. |
| ChatGPT | 100 Mo de RAM | service génératif basé sur le service API OpenAI, le modèle est défini dans l'argument de composition docker PRETRAINED_MODEL_NAME_OR_PATH (en particulier, dans ce service, gpt-3.5-turbo est utilisé. |
| Histoire rapideGPT | 3 Go de RAM, 4 Go de GPU | service génératif basé sur GPT-2 affiné, pour le sujet donné représenté par un nom renvoie une nouvelle sur un sujet donné |
| GPT-J6B | 1,5 Go de RAM, 24,2 Go de processeur graphique | service génératif basé sur le modèle génératif Transformers, le modèle est défini dans l'argument de composition docker PRETRAINED_MODEL_NAME_OR_PATH (en particulier, dans ce service, le modèle GPT-J est utilisé. |
| BLOOMZ7B | 2,5 Go de RAM, 29 Go de processeur graphique | service génératif basé sur le modèle génératif Transformers, le modèle est défini dans l'argument de composition du docker PRETRAINED_MODEL_NAME_OR_PATH (en particulier, dans ce service, le modèle BLOOMZ-7b1 est utilisé. |
| GPT-JT 6B | 2,5 Go de RAM, 25,1 Go de processeur graphique | service génératif basé sur le modèle génératif Transformers, le modèle est défini dans l'argument de composition docker PRETRAINED_MODEL_NAME_OR_PATH (en particulier, dans ce service, le modèle GPT-JT est utilisé. |
| Nom | Exigences | Description |
|---|---|---|
| Gestionnaire Alexa | 30 Mo de RAM | gestionnaire pour plusieurs commandes Alexa spécifiques |
| Compétence de Noël | 30 Mo de RAM | prend en charge la FAQ, les faits et les scripts pour Noël |
| Compétence de dialogue comète | 300 Mo de RAM | utilise le modèle COMeT ConceptNet pour exprimer une opinion, poser une question ou faire un commentaire sur les actions de l'utilisateur mentionnées dans le dialogue |
| Convertir Reddit | 1,2 Go de RAM | utilise un encodeur ConveRT pour créer des représentations efficaces de phrases |
| Compétence factice | une partie du conteneur d'agent | une compétence de secours avec plusieurs réponses candidates non toxiques |
| Boîte de dialogue de compétence factice | 600 Mo de RAM | renvoie le prochain tour de l'ensemble de données de discussion thématique si la réponse de l'utilisateur à la compétence factice est similaire à la réponse correspondante dans les données source |
| Élise | 30 Mo de RAM | Chatbot (https://github.com/wadetb/eliza) |
| Compétence émotionnelle | 40 Mo de RAM | renvoie les réponses du modèle aux émotions détectées par la classification des émotions à partir de l'annotateur de classification combinée |
| Contrôle qualité des faits | 170 Mo de RAM | répond à des questions factuelles |
| Compétence de jeu coopératif | 100 Mo de RAM | propose à l'utilisateur une conversation sur les jeux informatiques : les classements des meilleurs jeux de l'année écoulée, du mois dernier et de la semaine dernière |
| Compétence d'entretien des moissonneuses | 30 Mo de RAM | Compétence en entretien des moissonneuses |
| Compétence Gobot de maintenance des moissonneuses | 30 Mo de RAM | Entretien des abatteuses Compétence orientée vers un objectif |
| Compétence de base des connaissances | 100 Mo de RAM | génère une réponse basée sur l'historique du dialogue et fournit des connaissances liées au sujet de conversation en cours |
| Compétence méta-script | 150 Mo de RAM | propose un dialogue à plusieurs tours autour des activités humaines. La compétence utilise le modèle COMeT Atomic pour générer des descriptions et des questions de bon sens sur plusieurs aspects. |
| ASR mal entendu | 40 Mo de RAM | utilise les annotations du processeur ASR pour donner un retour à l'utilisateur lorsque la confiance ASR est trop faible |
| Compétence API Actualités | 60 Mo de RAM | présente les dernières nouvelles les mieux notées sur les entités ou les sujets utilisant l'API GNews |
| Compétence Oscar | 30 Mo de RAM | prend en charge la FAQ, les faits et les scripts pour Oscar |
| Compétence en informations personnelles | 40 Mo de RAM | interroge et stocke le nom, le lieu de naissance et l'emplacement de l'utilisateur |
| Compétence Y du programme DFF | 800 Mo de RAM | [Nouvelle version DFF] Chatbot Program Y (https://github.com/keiffster/program-y) adapté pour Dream socialbot |
| Programme DFF Y Compétence dangereuse | 100 Mo de RAM | [Nouvelle version DFF] Chatbot Program Y (https://github.com/keiffster/program-y) adapté pour Dream socialbot, contenant des réponses à des situations dangereuses dans un dialogue |
| Programme DFF Y Compétences Larges | 110 Mo de RAM | [Nouvelle version DFF] Chatbot Program Y (https://github.com/keiffster/program-y) adapté pour Dream socialbot, qui ne comprend que des modèles très généraux (avec une confiance moindre) |
| Compétence de bavardage | 35 Mo de RAM | pose des questions en utilisant des scripts manuscrits sur 25 sujets, y compris, mais sans s'y limiter, l'amour, le sport, le travail, les animaux de compagnie, etc. |
| Compétence du SuperBowl | 30 Mo de RAM | prend en charge la FAQ, les faits et les scripts pour le SuperBowl |
| Contrôle qualité du texte | 1,8 Go de RAM, 2,8 Go de processeur graphique | Le service trouve la réponse à une question factuelle dans le texte. |
| Compétence de la Saint-Valentin | 30 Mo de RAM | prend en charge la FAQ, les faits et les scripts pour la Saint-Valentin |
| Compétence de numérotation Wikidata | 100 Mo de RAM | génère un énoncé à l'aide de triplets Wikidata. Non allumé, doit être amélioré |
| Compétence des animaux DFF | 200 Mo de RAM | est créé à l'aide de DFF et comporte trois branches de conversation sur les animaux : les animaux de compagnie de l'utilisateur, les animaux de compagnie du socialbot et les animaux sauvages |
| Compétence artistique DFF | 100 Mo de RAM | Compétence basée sur DFF pour discuter de l'art |
| Compétence du livre DFF | 400 Mo de RAM | [Nouvelle version DFF] détecte les titres de livres et les auteurs mentionnés dans l'énoncé de l'utilisateur à l'aide de l'analyseur Wiki et de la liaison d'entités et recommande des livres en exploitant les informations de la base de données GoodReads. |
| Compétence personnelle du robot DFF | 150 Mo de RAM | vise à discuter des favoris des utilisateurs et des 20 choses les plus populaires avec des histoires courtes exprimant l'opinion du socialbot à leur sujet |
| Compétence DFF sur le coronavirus | 110 Mo de RAM | [Nouvelle version DFF] récupère des données sur le nombre de cas et de décès de coronavirus dans différents endroits provenant du Centre pour la science et l'ingénierie des systèmes de l'Université John Hopkins |
| Compétence alimentaire DFF | 150 Mo de RAM | construit avec DFF pour encourager les conversations liées à l'alimentation |
| Compétence d'amitié DFF | 100 Mo de RAM | [Nouvelle version DFF] Compétence basée sur DFF pour saluer l'utilisateur au début de la boîte de dialogue et rediriger l'utilisateur vers une compétence scriptée |
| Compétence de faits DFF | 100 Mo de RAM | [Nouvelle version DFF] Raconte des faits amusants aux utilisateurs |
| Compétence de jeu DFF | 80 Mo de RAM | propose une discussion sur les jeux vidéo. Gaming Skill est destiné à une discussion plus générale sur les jeux vidéo |
| Compétence de potins DFF | 95 Mo de RAM | Compétence basée sur DFF pour discuter d'autres personnes avec des nouvelles à leur sujet |
| Compétence d'image DFF | 100 Mo de RAM | [Nouvelle version DFF] Compétence scriptée basée sur les sous-titres d'image envoyés (à partir d'annotations) avec des réponses spécifiées en cas de détection de nourriture, d'animaux ou de personnes, et des réponses par défaut dans le cas contraire. |
| Compétence de modèle DFF | 50 Mo de RAM | [Nouvelle version DFF] Compétence basée sur DFF qui fournit un exemple d'utilisation de DFF |
| Compétence invitée par le modèle DFF | 50 Mo de RAM | [Nouvelle version DFF] Compétence basée sur DFF qui fournit des réponses générées par un modèle de langage en fonction des invites spécifiées et du contexte de dialogue. Le modèle à utiliser est spécifié dans GENERATIVE_SERVICE_URL. Par exemple, vous pouvez utiliser le service Transformer LM GPTJ. |
| Compétence de mise à la terre DFF | 90 Mo de RAM | [Nouvelle version DFF] Compétence basée sur DFF pour répondre au sujet de la conversation, générer un accusé de réception, générer des réponses universelles sur certains actes de dialogue par MIDAS |
| Répondeur d'intention DFF | 100 Mo de RAM | [Nouvelle version DFF] fournit des réponses basées sur un modèle pour certaines des intentions détectées par l'annotateur Intent Catcher |
| Compétence de film DFF | 1,1 Go de RAM | est implémenté en utilisant DFF et prend en charge les conversations liées aux films |
| Compétence musicale DFF | 70 Mo de RAM | Compétence basée sur DFF pour discuter de musique |
| Compétence scientifique DFF | 90 Mo de RAM | Compétence basée sur DFF pour discuter de science |
| Compétence de nouvelle DFF | 90 Mo de RAM | [Nouvelle version DFF] raconte des histoires courtes aux utilisateurs dans 3 catégories : (1) des histoires au coucher, telles que des fables et des histoires morales, (2) des histoires d'horreur et (3) des histoires drôles. |
| Compétence sportive DFF | 70 Mo de RAM | Compétence basée sur DFF pour discuter de sport |
| Compétence de voyage DFF | 70 Mo de RAM | Compétence basée sur DFF pour discuter de voyage |
| Compétence météo DFF | 1,4 Go de RAM | [Nouvelle version DFF] utilise le service OpenWeatherMap pour obtenir les prévisions pour l'emplacement de l'utilisateur |
| Compétence wiki DFF | 150 Mo de RAM | utilisé pour créer des scénarios avec extraction d'entités, remplissage d'emplacements, insertion de faits et accusés de réception |
| Nom | Exigences | Description |
|---|---|---|
| Compétence FAQ sur l'IA | 150 Mo de RAM | [Nouvelle version DFF] Tout ce que vous vouliez savoir sur l'IA moderne sans oser le demander ! Cet assistant FAQ discute avec vous tout en vous expliquant les sujets les plus simples du monde technologique d'aujourd'hui. |
| Compétence de styliste de mode | 150 Mo de RAM | [Nouvelle version DFF] Restez protégé à chaque saison avec l'assistant vestimentaire de Costa Industries ! Découvrez le confort et la protection ultimes, quelle que soit la météo. Restez au chaud en hiver et... |
| Compétence de personnalité de rêve | 150 Mo de RAM | [Nouvelle version DFF] Compétence basée sur des invites qui utilise un service génératif donné pour générer des réponses basées sur l'invite donnée |
| Compétence en marketing | 150 Mo de RAM | [Nouvelle version DFF] Connectez-vous avec votre audience comme jamais auparavant avec Marketing AI Assistant ! Atteignez de nouveaux sommets de réussite en exploitant le pouvoir de l’empathie. Dis au revoir.. |
| Compétence de conte de fées | 150 Mo de RAM | [Nouvelle version DFF] Cet assistant vous racontera, à vous ou à vos enfants, un conte de fées court mais captivant. Choisissez les personnages et le sujet et laissez le reste à l'imagination de l'IA. |
| Compétence nutritionnelle | 150 Mo de RAM | [Nouvelle version DFF] Découvrez le secret d'une alimentation saine avec notre assistant IA ! Trouvez facilement des options alimentaires nutritives pour vous et vos proches. Dites adieu au stress des repas et bonjour aux délices... |
| Compétence en coaching de vie | 150 Mo de RAM | [Nouvelle version DFF] Libérez votre plein potentiel avec l'assistant IA breveté de Rhodes & Co ! Atteignez des performances optimales au travail et à la maison. Mettez-vous en forme sans effort et inspirez les autres. |
Kuratov Y. et al. Rapport technique DREAM pour le Prix Alexa 2019 // Actes du Prix Alexa. – 2020.
Baymurzina D. et al. Rapport technique DREAM pour le prix Alexa 4 // Actes du prix Alexa. – 2021.
DeepPavlov Dream est sous licence Apache 2.0.
Program-y (voir dream/skills/dff_program_y_skill , dream/skills/dff_program_y_wide_skill , dream/skills/dff_program_y_dangerous_skill ) est sous licence Apache 2.0. Eliza (voir dream/skills/eliza ) est sous licence MIT.
Pour créer un fichier de certification xlsx avec les réponses du bot, vous pouvez utiliser le script xlsx_responder.py en exécutant
docker-compose -f docker-compose.yml -f dev.yml exec -T -u $( id -u ) agent python3
utils/xlsx_responder.py --url http://0.0.0.0:4242
--input ' tests/dream/test_questions.xlsx '
--output ' tests/dream/output/test_questions_output.xlsx '
--cache tests/dream/output/test_questions_output_ $( date --iso-8601=seconds ) .json Assurez-vous que tous les services sont déployés. --input - fichier xlsx avec les questions de certification, --output - fichier xlsx avec les réponses du robot, --cache - json , qui contient un balisage détaillé et est utilisé pour un cache.


