Okapi
1.0.0
Okapi
Grands modèles de langage adaptés aux instructions dans plusieurs langues avec apprentissage par renforcement à partir de la rétroaction humaine
Il s'agit du référentiel du framework Okapi qui introduit des ressources et des modèles pour le réglage des instructions pour les grands modèles de langage (LLM) avec apprentissage par renforcement à partir de commentaires humains (RLHF) dans plusieurs langues. Notre framework prend en charge 26 langues, dont 8 langues à ressources élevées, 11 langues à ressources moyennes et 7 langues à ressources faibles.
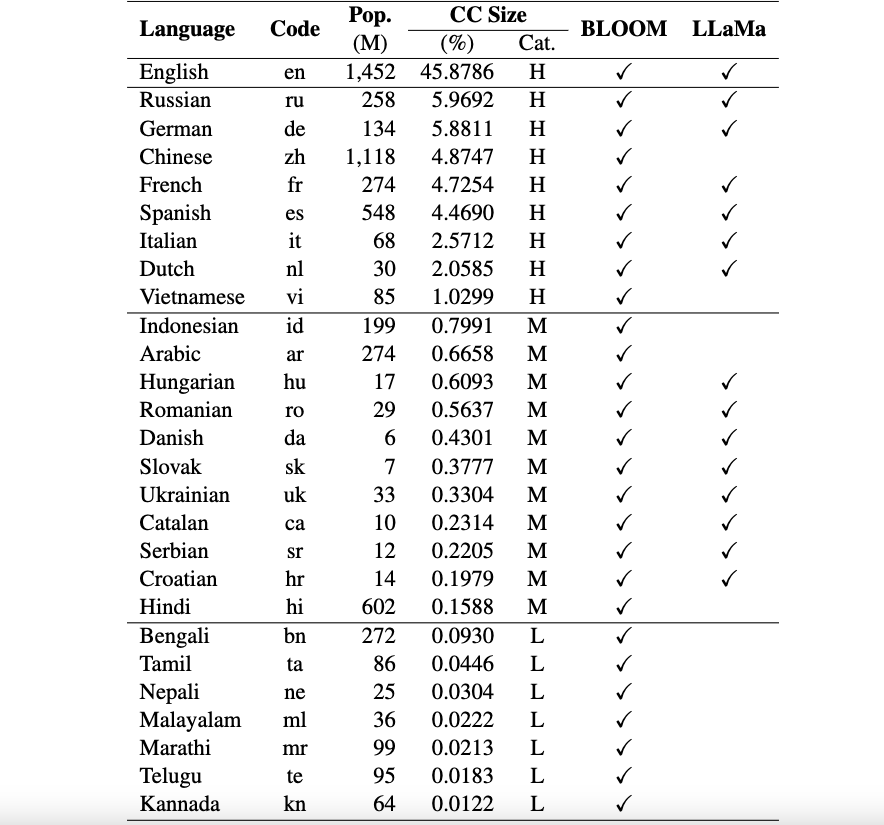
Ressources Okapi : nous fournissons des ressources pour effectuer le réglage des instructions avec RLHF pour 26 langues, y compris les invites ChatGPT, les ensembles de données d'instructions multilingues et les données de classement des réponses multilingues.
Modèles Okapi : nous fournissons des LLM basés sur les instructions RLHF pour 26 langues sur l'ensemble de données Okapi. Nos modèles incluent des versions basées sur BLOOM et LLaMa. Nous fournissons également des scripts pour interagir avec nos modèles et affiner les LLM avec nos ressources.
Ensembles de données de référence pour l'évaluation multilingue : nous fournissons trois ensembles de données de référence pour évaluer les grands modèles linguistiques multilingues (LLM) pour 26 langues. Vous pouvez accéder aux ensembles de données complets et aux scripts d'évaluation : ici.
Avis d'utilisation et de licence : Okapi est destiné et autorisé à des fins de recherche uniquement. Les ensembles de données sont CC BY NC 4.0 (autorisant uniquement une utilisation non commerciale) et les modèles formés à l'aide de l'ensemble de données ne doivent pas être utilisés en dehors des fins de recherche.
Notre document technique avec les résultats de l’évaluation peut être consulté ici.
Nous effectuons un processus complet de collecte de données pour préparer les données nécessaires à notre cadre multilingue Okapi en quatre étapes principales :
Pour télécharger l'intégralité de l'ensemble de données, vous pouvez utiliser le script suivant :
bash scripts/download.shSi vous n'avez besoin des données que pour une langue spécifique, vous pouvez spécifier le code de la langue comme argument du script :
bash scripts/download.sh [LANG]
# For example, to download the dataset for Vietnamese: bash scripts/download.sh viAprès le téléchargement, nos données publiées se trouvent dans le répertoire des ensembles de données . Il comprend :
multilingual-alpaca-52k : Les données traduites pour 52K instructions en anglais en alpaga en 26 langues.
multilingual-ranking-data-42k : Les données de classement des réponses multilingues pour 26 langues. Pour chaque langue, nous fournissons 42 000 instructions ; chacun d'eux a 4 réponses classées. Ces données peuvent être utilisées pour former des modèles de récompense pour 26 langues.
multilingual-rl-tuning-64k : Les données d'instructions multilingues pour RLHF. Nous fournissons 62 000 instructions pour chacune des 26 langues.
En utilisant nos ensembles de données Okapi et la technique de réglage des instructions basée sur RLHF, nous introduisons des LLM multilingues affinés pour 26 langues, construits sur les versions 7B de LLaMA et BLOOM. Les modèles peuvent être obtenus auprès de HuggingFace ici.
Okapi prend en charge les discussions interactives avec les LLM multilingues adaptés aux instructions en 26 langues. Suivez les étapes suivantes pour les chats :
git clone https://github.com/nlp-uoregon/Okapi.git
cd Okapi
pip install -r requirements.txt
from chat import pipeline
model_path = 'uonlp/okapi-vi-bloom'
p = pipeline ( model_path , gpu = True )
instruction = 'Dịch câu sau sang Tiếng Việt' # Translate the following sentence into Vietnamese
prompt_input = 'The City of Eugene - a great city for the arts and outdoors. '
response = p . generate ( instruction = instruction , prompt_input = prompt_input )
print ( response )Nous fournissons également des scripts pour affiner les LLM avec nos données d'instruction à l'aide de RLHF, couvrant trois étapes principales : le réglage fin supervisé, la modélisation des récompenses et le réglage fin avec RLHF. Utilisez les étapes suivantes pour affiner les LLM :
conda create -n okapi python=3.9
conda activate okapi
pip install -r requirements.txtbash scripts/supervised_finetuning.sh [LANG]bash scripts/reward_modeling.sh [LANG]bash scripts/rl_training.sh [LANG]Si vous utilisez les données, le modèle ou le code de ce référentiel, veuillez citer :
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

