ChatBot chinois/chatbot chinois
- L'auteur a entièrement transféré à
Direction du réseau neuronal du graphique GNN Le développement C++ ne suivra plus le NLP et le code du projet cessera d'être maintenu. Lorsque le projet Yuanxiang a été achevé, il y avait très peu de ressources en ligne. L'auteur est entré en contact avec la PNL et le Deep Learning pour la première fois sur un coup de tête. Surmontant de nombreuses difficultés, il a finalement écrit ce Toy Model. Par conséquent, l'auteur sait que ce n'est pas facile pour les débutants, donc même si le projet n'est plus maintenu, les problèmes ou les e-mails ([email protected]) recevront une réponse en temps opportun pour aider les nouveaux arrivants dans le Deep Learning. (La version de Tensorflow que j'utilise est trop ancienne. Si vous exécutez directement la nouvelle version, vous obtiendrez certainement diverses erreurs. Si vous rencontrez des difficultés, ne vous embêtez pas à installer l'ancienne version de l'environnement. Il est recommandé d'utiliser Pytorch pour le reconstruire selon ma logique de traitement. J'ai la flemme d'écrire)
- Aspect GNN :
- Un ensemble de modèles de comparaison de référence : GNNs-Baseline a été adapté et compilé pour faciliter une vérification rapide des idées.
- Le code open source de mon article ACMMM 2023 (CCF-A) est ici LSTGM.
- Le code open source de mon article ICDM 2023 (CCF-B) est toujours en cours de compilation. . . VERT
- Les boursiers sont invités à ajouter, communiquer et apprendre.
Configuration de l'environnement
| programme | Version |
|---|
| python | 3,68 |
| flux tensoriel | 1.13.1 |
| Kéras | 2.2.4 |
| fenêtres10 | |
| jupyter | |
Principaux documents de référence
- Thèse "TRADUCTION MACHINE NEURALE PAR APPRENTISSAGE CONJOINT À ALIGNER ET À TRADUIRE ( Cliquez sur le titre pour télécharger )"
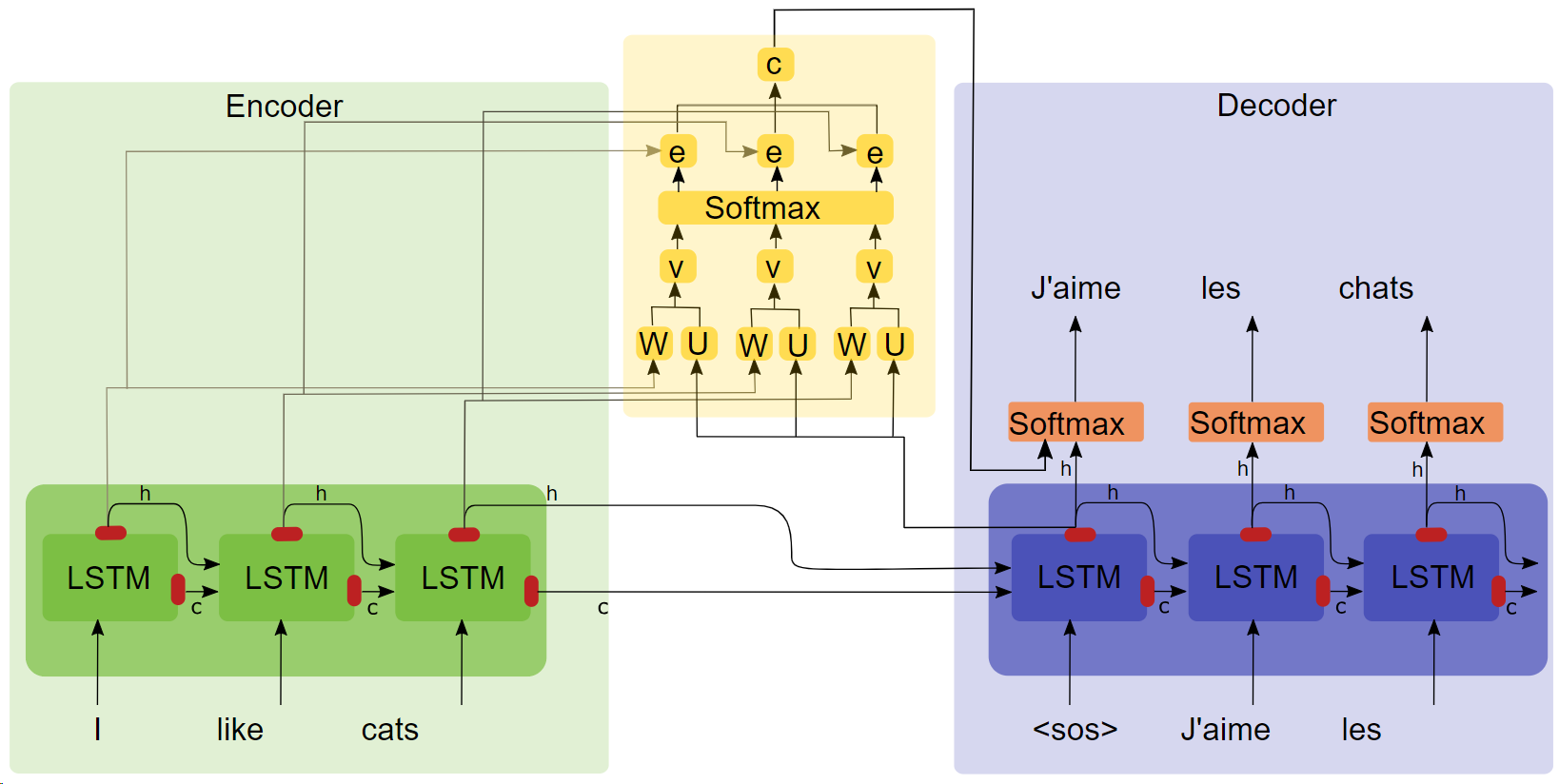
- Diagramme de structure de l'attention
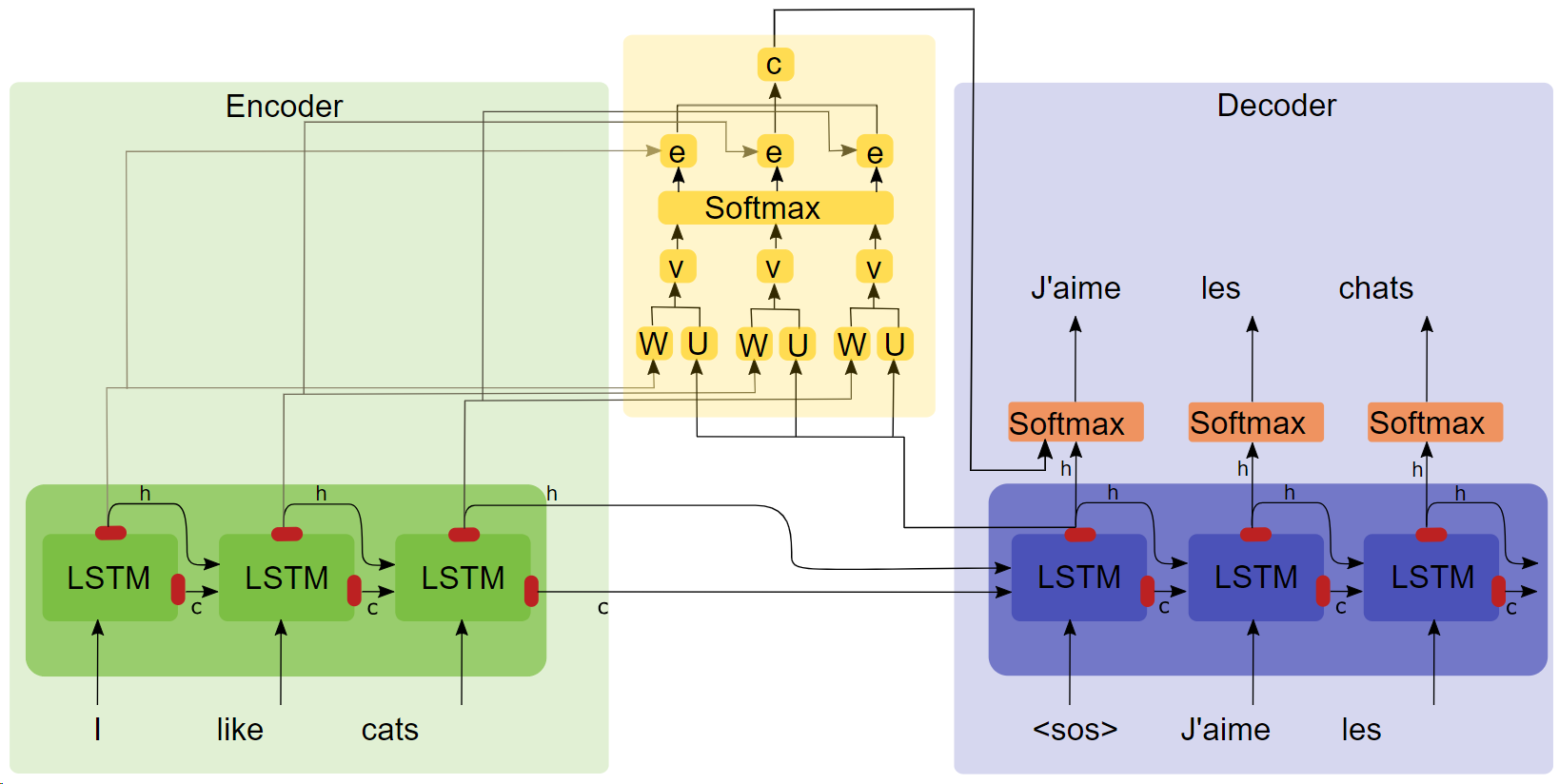
Points clés
- LSTM
- séquence2séq
- Les expériences d'attention montrent qu'après l'ajout du mécanisme d'attention, la vitesse d'entraînement est plus rapide, la convergence est plus rapide et l'effet est meilleur.
Corpus et environnement de formation
100 000 groupes de dialogue du corpus Qingyun, formés au sein du colaboratoire Google.
courir
Méthode 1 : Processus complet
- Prétraitement des données
get_data
- Formation sur modèle
chatbot_train (Il s'agit de la version montée sur Google Colab, le chemin d'exécution local doit être légèrement modifié)
- Prédiction du modèle
chatbot_inference_Attention
Méthode 2 : charger un modèle existant
- Exécutez
chatbot_inference_Attention
-
models/W--184-0.5949-.h5
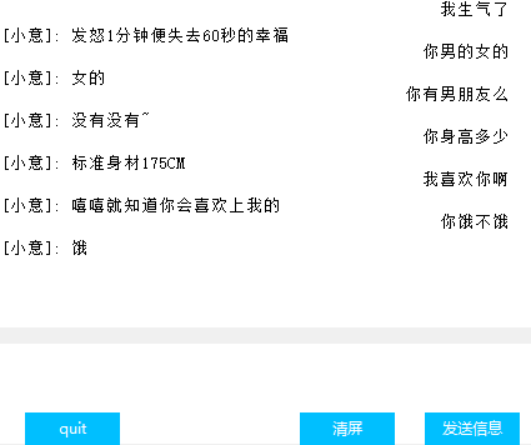
Interface(Tkinter)
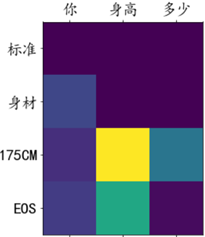
Attention visualisation du poids
autre
- Dans le fichier de formation chat_bot, les deux premiers des trois derniers blocs de code sont utilisés pour monter Google Cloud Disk, et le dernier est utilisé pour obtenir ces pertes afin de faciliter le dessin. Je ne sais pas pourquoi le tensorbord dans la fonction de rappel. ne fonctionne pas, alors j'ai proposé cette stratégie ;
- L'avant-dernier bloc de code du fichier de prédiction n'a que la saisie de texte mais pas d'interface. Le dernier bloc de code est l'interface. L'un des deux blocs peut être exécuté immédiatement selon les besoins ;
- Il y a beaucoup de sorties intermédiaires dans le code, j'espère que cela vous aidera à comprendre le code ;
- Il existe un modèle que j'ai formé sur des modèles. Il ne devrait y avoir aucun problème en fonctionnement normal. Vous pouvez également le former vous-même.
- L'auteur a des capacités limitées et n'a pas trouvé d'indicateur pour quantifier l'effet du dialogue, de sorte que la perte ne peut refléter qu'approximativement les progrès de la formation.