MoEL
1.0.0


Voici l'implémentation PyTorch du document :
MoEL : Mélange d’auditeurs empathiques . Zhaojiang Lin , Andrea Madotto, Jamin Shin, Peng Xu, Pascale Fung EMNLP 2019 [PDF]
Ce code a été écrit en utilisant PyTorch >= 0.4.1. Si vous utilisez des codes sources ou des ensembles de données inclus dans cette boîte à outils dans votre travail, veuillez citer l'article suivant. Le bibtex est répertorié ci-dessous :
@article{lin2019moel,
title={MoEL : Mélange d'auditeurs empathiques},
author={Lin, Zhaojiang et Madotto, Andrea et Shin, Jamin et Xu, Peng et Fung, Pascale},
journal={préimpression arXiv arXiv:1908.07687},
année={2019}
}
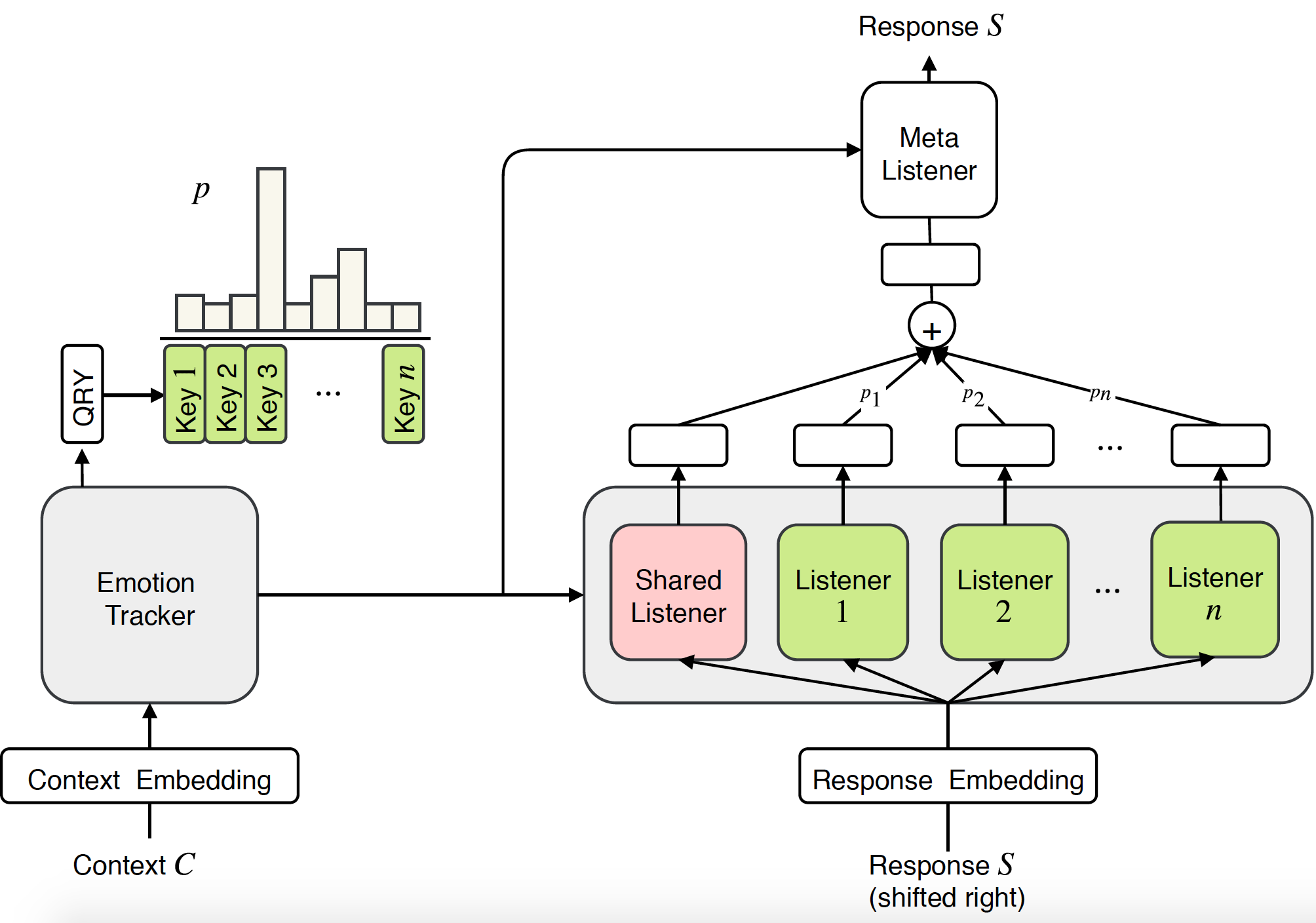
Les recherches antérieures sur les systèmes de dialogue empathique se sont principalement concentrées sur la génération de réponses face à certaines émotions. Cependant, être empathique nécessite non seulement la capacité de générer des réponses émotionnelles, mais, plus important encore, nécessite de comprendre les émotions des utilisateurs et d'y répondre de manière appropriée. Dans cet article, nous proposons une nouvelle approche de bout en bout pour modéliser l'empathie dans les systèmes de dialogue : le mélange d'auditeurs empathiques (MoEL). Notre modèle capture d'abord les émotions de l'utilisateur et génère une distribution des émotions. Sur cette base, MoEL combinera en douceur les états de sortie du ou des auditeurs appropriés, chacun optimisé pour réagir à certaines émotions, et générera une réponse empathique. Les évaluations humaines sur l'ensemble de données sur les dialogues empathiques confirment que MoEL surpasse la base de référence de la formation multitâche en termes d'empathie, de pertinence et de fluidité. De plus, l'étude de cas sur les réponses générées par différents auditeurs montre une grande interprétabilité de notre modèle.
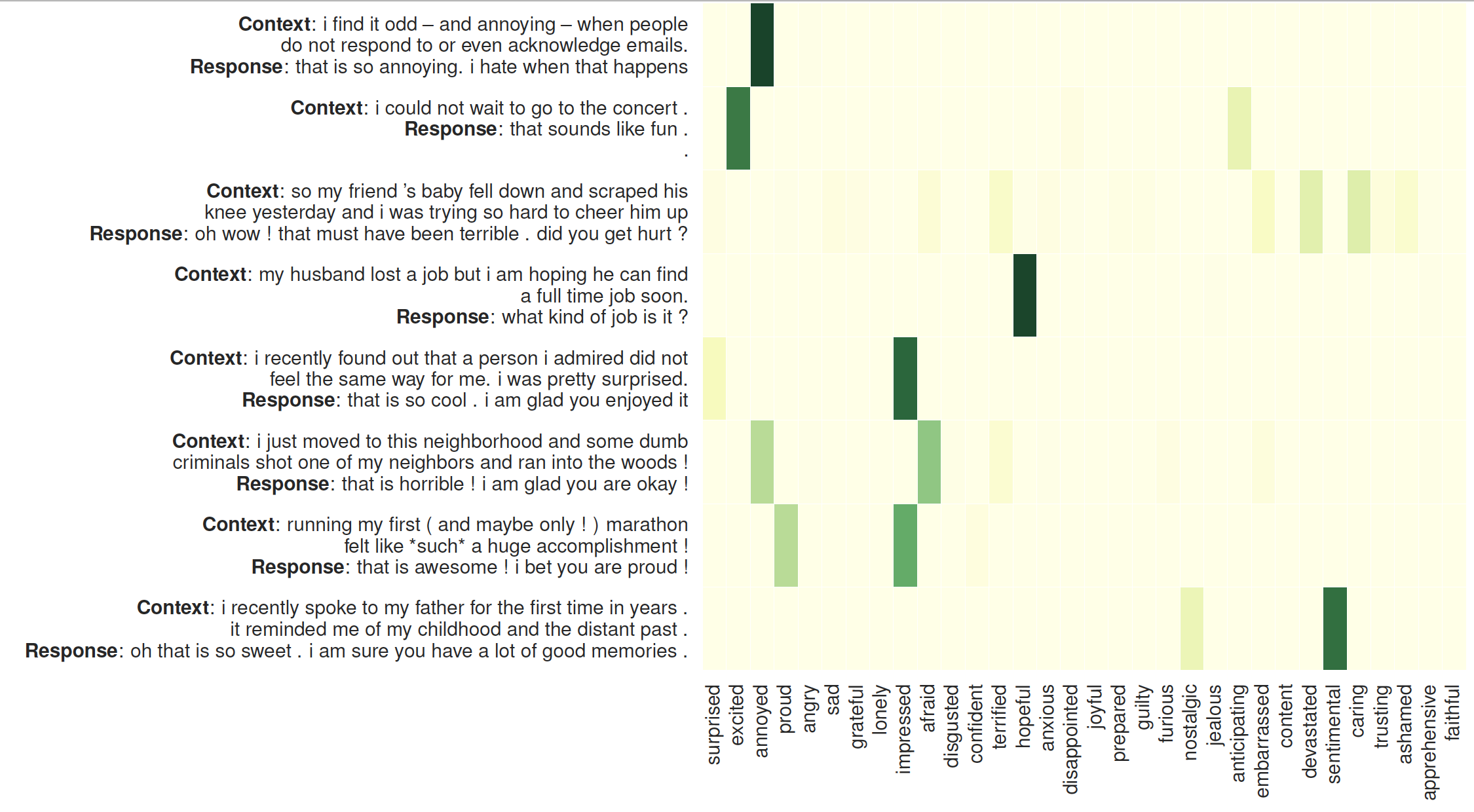
La visualisation de l'attention sur les auditeurs : Le côté gauche est le contexte suivi des réponses générées par MoEL. La carte thermique illustre les poids d'attention sur 32 auditeurs
Vérifiez les packages nécessaires ou exécutez simplement la commande
❱❱❱ pip install -r requirements.txtIntégration de gants pré-entraînés : Glove.6B.300d.txt dans le dossier /vectors/.
Résultat rapide
Pour ignorer la formation, veuillez vérifier Generation_result.txt .
Ensemble de données
L'ensemble de données (dialogue empathique) est prétraité et stocké au format npy : sys_dialog_texts.train.npy, sys_target_texts.train.npy, sys_emotion_texts.train.npy qui consiste en une liste parallèle de contexte (source), de réponse (cible) et d'étiquette d'émotion. (étiquette supplémentaire).
Formation et Test
Ministère de l'Éducation et de la Culture
❱❱❱ python3 main.py --model experts --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 1 --heads 2 --topk 5 --cuda --pretrain_emb --softmax --basic_learner --schedule 10000 --save_path save/moel/
Base de référence du transformateur
❱❱❱ python3 main.py --model trs --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 2 --heads 2 --cuda --pretrain_emb --save_path save/trs/
Base de référence du transformateur multitâche
❱❱❱ python3 main.py --model trs --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 2 --heads 2 --cuda --pretrain_emb --multitask --save_path save/multi-trs/


