MELD
1.0.0
Si vous êtes intéressé par les LLM sur les tests de QI, consultez notre nouveau travail : AlgoPuzzleVQA
Nous avons publié les fonctionnalités visuelles extraites à l'aide de Resnet - https://github.com/declare-lab/MM-Align
Pour les références mises à jour, veuillez visiter ce lien : conv-emotion
Pour télécharger les données, utilisez wget : wget http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz
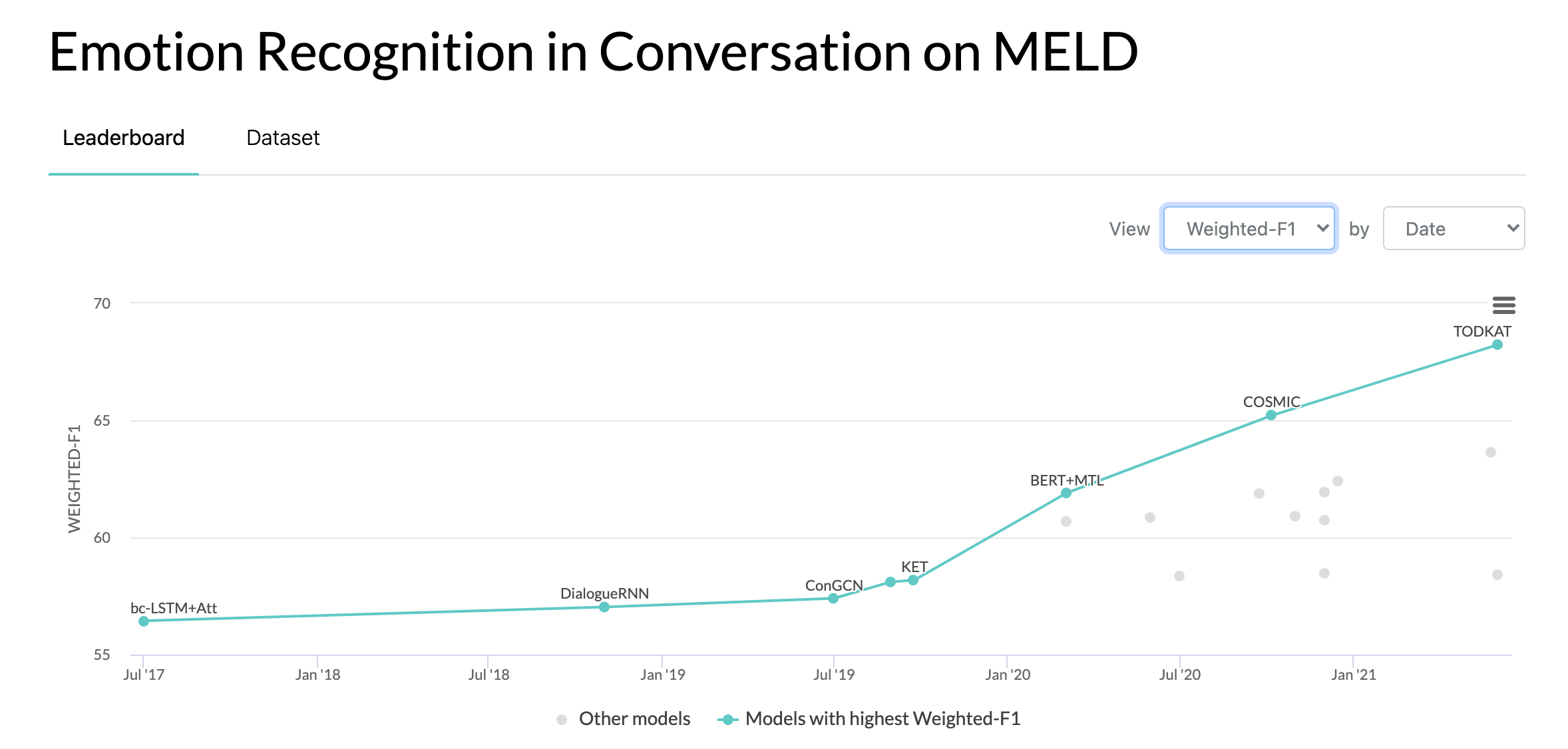
10/10/2020 : Nouvel article et SOTA sur la reconnaissance des émotions dans les conversations sur l'ensemble de données MELD. Référez-vous au répertoire COSMIC pour le code. Lisez l'article -- COSMIC : Connaissances COmmonSense pour l'identification des émotions dans les conversations.
22/05/2019 : MELD : Un ensemble de données multimodal multi-parties pour la reconnaissance des émotions dans la conversation a été accepté comme article complet à l'ACL 2019. L'article mis à jour peut être trouvé ici - https://arxiv.org/pdf/1810.02508. pdf
22/05/2019 : Dyadic MELD est sorti. Il peut être utilisé pour tester des modèles conversationnels dyadiques.
15/11/2018 : Le problème dans train.tar.gz a été résolu.
Zhang, Yazhou, Qiuchi Li, Dawei Song, Peng Zhang et Panpan Wang. «Réseaux interactifs d'inspiration quantique pour l'analyse des sentiments conversationnels». IJCAI 2019.
Zhang, Dong, Liangqing Wu, Changlong Sun, Shoushan Li, Qiaoming Zhu et Guodong Zhou. "Modélisation de la dépendance sensible au contexte et au locuteur pour la détection des émotions dans les conversations multi-locuteurs." IJCAI 2019.
Ghosal, Deepanway, Navonil Majumder, Soujanya Poria, Niyati Chhaya et Alexander Gelbukh. "DialogueGCN : un réseau neuronal convolutif graphique pour la reconnaissance des émotions dans la conversation." EMNLP 2019.
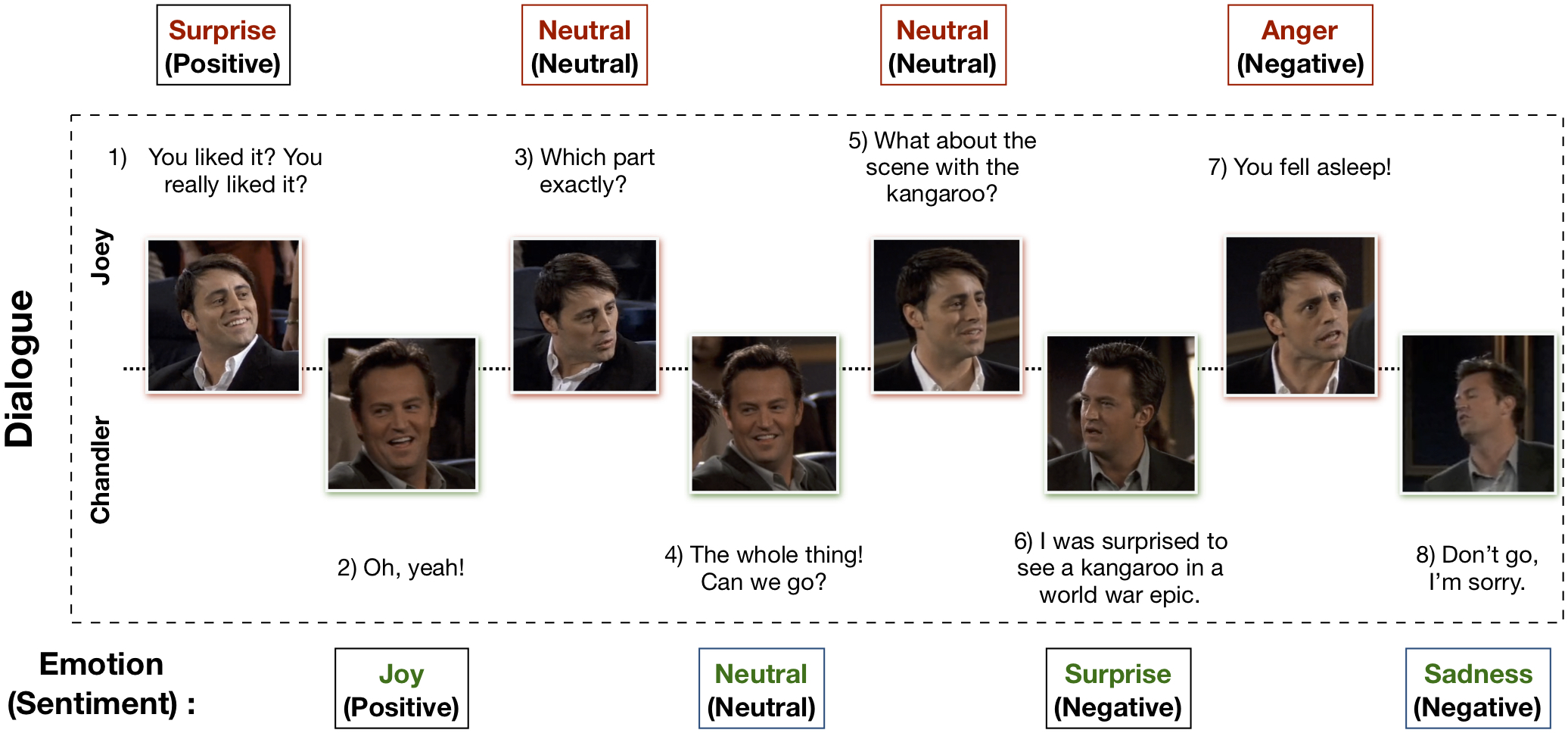
L'ensemble de données multimodal EmotionLines (MELD) a été créé en améliorant et en étendant l'ensemble de données EmotionLines. MELD contient les mêmes instances de dialogue disponibles dans EmotionLines, mais il englobe également les modalités audio et visuelles ainsi que le texte. MELD contient plus de 1 400 dialogues et 13 000 déclarations tirées de la série télévisée Friends. Plusieurs intervenants ont participé aux dialogues. Chaque énoncé dans un dialogue a été étiqueté par l'une de ces sept émotions : colère, dégoût, tristesse, joie, neutre, surprise et peur. MELD a également une annotation de sentiment (positif, négatif et neutre) pour chaque énoncé.
| Statistiques | Former | Développeur | Test |
|---|---|---|---|
| # de modalité | {a,v,t} | {a,v,t} | {a,v,t} |
| # de mots uniques | 10 643 | 2 384 | 4 361 |
| Moy. longueur de l'énoncé | 8.03 | 7,99 | 8.28 |
| Max. longueur de l'énoncé | 69 | 37 | 45 |
| Moy. # d'émotions par dialogue | 15h30 | 3.35 | 3.24 |
| # de dialogues | 1039 | 114 | 280 |
| # d'énoncés | 9989 | 1109 | 2610 |
| # d'intervenants | 260 | 47 | 100 |
| Nombre de changements d'émotions | 4003 | 427 | 1003 |
| Moy. durée d'un énoncé | 3,59s | 3,59s | 3,58s |
Veuillez visiter https://affective-meld.github.io pour plus de détails.
| Former | Développeur | Test | |
|---|---|---|---|
| Colère | 1109 | 153 | 345 |
| Dégoût | 271 | 22 | 68 |
| Peur | 268 | 40 | 50 |
| Joie | 1743 | 163 | 402 |
| Neutre | 4710 | 470 | 1256 |
| Tristesse | 683 | 111 | 208 |
| Surprendre | 1205 | 150 | 281 |
L'analyse des données multimodales exploite les informations provenant de plusieurs canaux de données parallèles pour la prise de décision. Avec la croissance rapide de l'IA, la reconnaissance multimodale des émotions a acquis un intérêt majeur en recherche, principalement en raison de ses applications potentielles dans de nombreuses tâches difficiles, telles que la génération de dialogues, l'interaction multimodale, etc. Un système de reconnaissance des émotions conversationnelles peut être utilisé pour générer des réponses appropriées en analyser les émotions des utilisateurs. Bien qu’il existe de nombreux travaux menés sur la reconnaissance multimodale des émotions, seuls très peu d’entre eux se concentrent réellement sur la compréhension des émotions dans les conversations. Cependant, leur travail se limite uniquement à la compréhension des conversations dyadiques et n’est donc pas adaptable à la reconnaissance des émotions dans les conversations multipartites ayant plus de deux participants. EmotionLines peut être utilisé comme ressource pour la reconnaissance des émotions pour le texte uniquement, car il n'inclut pas les données provenant d'autres modalités telles que le visuel et l'audio. Dans le même temps, il convient de noter qu’il n’existe aucun ensemble de données conversationnelles multimodales et multipartites disponibles pour la recherche sur la reconnaissance des émotions. Dans ce travail, nous avons étendu, amélioré et développé l'ensemble de données EmotionLines pour le scénario multimodal. La reconnaissance des émotions dans des tours séquentiels présente plusieurs défis et la compréhension du contexte en fait partie. Le changement d'émotion et le flux d'émotion dans la séquence de tours d'un dialogue rendent la modélisation précise du contexte une tâche difficile. Dans cet ensemble de données, comme nous avons accès aux sources de données multimodales pour chaque dialogue, nous émettons l'hypothèse que cela améliorera la modélisation du contexte, bénéficiant ainsi aux performances globales de reconnaissance des émotions. Cet ensemble de données peut également être utilisé pour développer un système de dialogue affectif multimodal. IEMOCAP, SEMAINE sont des ensembles de données conversationnelles multimodales qui contiennent une étiquette d'émotion pour chaque énoncé. Cependant, ces ensembles de données sont de nature dyadique, ce qui justifie l'importance de notre ensemble de données Multimodal-EmotionLines. Les autres ensembles de données multimodales de reconnaissance des émotions et des sentiments accessibles au public sont MOSEI, MOSI, MOUD. Cependant, aucun de ces ensembles de données n’est conversationnel.
La première étape consiste à trouver l'horodatage de chaque énoncé dans chacun des dialogues présents dans l'ensemble de données EmotionLines. Pour ce faire, nous avons parcouru les fichiers de sous-titres de tous les épisodes qui contiennent l'horodatage de début et de fin des énoncés. Ce processus nous a permis d'obtenir l'identifiant de la saison, l'identifiant de l'épisode et l'horodatage de chaque énoncé de l'épisode. Nous mettons deux contraintes lors de l'obtention des horodatages : (a) les horodatages des énoncés d'un dialogue doivent être par ordre croissant, (b) tous les énoncés d'un dialogue doivent appartenir au même épisode et à la même scène. La contrainte avec ces deux conditions a révélé que dans EmotionLines, quelques dialogues sont constitués de multiples dialogues naturels. Nous avons filtré ces cas de l'ensemble de données. En raison de cette étape de correction d'erreur, dans notre cas, nous avons un nombre de dialogues différent de celui des EmotionLines. Après avoir obtenu l'horodatage de chaque énoncé, nous avons extrait les clips audiovisuels correspondants de l'épisode source. Séparément, nous avons également supprimé le contenu audio de ces clips vidéo. Enfin, l'ensemble de données contient des modalités visuelles, audio et textuelles pour chaque dialogue.
Le document expliquant cet ensemble de données peut être trouvé - https://arxiv.org/pdf/1810.02508.pdf
Veuillez visiter - http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz pour télécharger les données brutes. Les données sont stockées au format .mp4 et peuvent être trouvées dans les fichiers XXX.tar.gz. Les annotations peuvent être trouvées sur https://github.com/declare-lab/MELD/tree/master/data/MELD.
| Nom de la colonne | Description |
|---|---|
| Sr Non. | Numéros de série des énoncés principalement destinés à référencer les énoncés en cas de versions différentes ou de copies multiples avec différents sous-ensembles |
| Énonciation | Énoncés individuels d’EmotionLines sous forme de chaîne. |
| Conférencier | Nom du locuteur associé à l'énoncé. |
| Émotion | L'émotion (neutre, joie, tristesse, colère, surprise, peur, dégoût) exprimée par le locuteur dans l'énoncé. |
| Sentiment | Le sentiment (positif, neutre, négatif) exprimé par le locuteur dans l'énoncé. |
| ID_dialogue | L'index du dialogue à partir de 0. |
| ID_énoncé | L'indice de l'énoncé particulier dans le dialogue à partir de 0. |
| Saison | La saison non. de l'émission télévisée Friends à laquelle appartient un énoncé particulier. |
| Épisode | L'épisode n°. de l'émission télévisée Friends dans une saison particulière à laquelle appartient l'énoncé. |
| Heure de début | L'heure de début de l'énoncé dans l'épisode donné au format « hh:mm:ss,ms ». |
| Heure de fin | L'heure de fin de l'énoncé dans l'épisode donné au format « hh:mm:ss,ms ». |
Il existe 13 fichiers pickle comprenant les données et les fonctionnalités utilisées pour former les modèles de base. Voici une brève description de chacun des fichiers cornichon.
import pickle
data , W , vocab , word_idx_map , max_sentence_length , label_index = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_avg_emb , val_text_avg_emb , test_text_avg_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_CNN_emb , val_text_CNN_emb , test_text_CNN_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_emb , val_text_emb , test_text_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_bimodal_emb , val_bimodal_emb , test_bimodal_emb = pickle . load ( open ( filepath , 'rb' ))Il y a 2 scripts python fournis dans './utils/' :
Pour l'expérimentation, toutes les étiquettes sont représentées sous forme d'encodages one-hot, dont les indices sont les suivants :
Pour la base de référence sur la classification des émotions, les pondérations de classe suivantes ont été utilisées. L'indexation est la même que celle mentionnée ci-dessus. Pondérations des classes : [4,0, 15,0, 15,0, 3,0, 1,0, 6,0, 3,0].
Veuillez suivre ces étapes pour exécuter la ligne de base :
./data/pickles/baseline/baseline.py comme suit :python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]python baseline.py -classify Sentiment -modality text -trainpython baseline.py -h pour obtenir le texte d'aide pour les paramètres../data/models/ . Veuillez citer les articles suivants si vous trouvez cet ensemble de données utile dans votre recherche
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD : un ensemble de données multimodales multipartites pour la reconnaissance des émotions dans les conversations. LCA 2019.
Chen, SY, Hsu, CC, Kuo, CC et Ku, LW EmotionLines : un corpus émotionnel de conversations multipartites. Préimpression arXiv arXiv:1802.08379 (2018).
L'ensemble de données multimodal de détection d'émotion EmoryNLP a été créé en améliorant et en étendant l'ensemble de données de détection d'émotion EmoryNLP. Il contient les mêmes instances de dialogue disponibles dans l'ensemble de données EmoryNLP Emotion Detection, mais il englobe également les modalités audio et visuelles ainsi que le texte. Il existe plus de 800 dialogues et 9 000 énoncés de la série télévisée Friends dans l'ensemble de données multimodal EmoryNLP. Plusieurs intervenants ont participé aux dialogues. Chaque énoncé dans un dialogue a été étiqueté par l'une de ces sept émotions : neutre, joyeuse, paisible, puissante, effrayée, folle et triste. Les annotations sont empruntées à l'ensemble de données d'origine.
| Statistiques | Former | Développeur | Test |
|---|---|---|---|
| # de modalité | {a,v,t} | {a,v,t} | {a,v,t} |
| # de mots uniques | 9 744 | 2 123 | 2 345 |
| Moy. longueur de l'énoncé | 7,86 | 6,97 | 7,79 |
| Max. longueur de l'énoncé | 78 | 60 | 61 |
| Moy. # d'émotions par scène | 4.10 | 16h00 | 4h40 |
| # de dialogues | 659 | 89 | 79 |
| # d'énoncés | 7551 | 954 | 984 |
| # d'intervenants | 250 | 46 | 48 |
| Nombre de changements d'émotions | 4596 | 575 | 653 |
| Moy. durée d'un énoncé | 5,55s | 5,46 s | 5,27 s |
| Former | Développeur | Test | |
|---|---|---|---|
| Joyeux | 1677 | 205 | 217 |
| Fou | 785 | 97 | 86 |
| Neutre | 2485 | 322 | 288 |
| Pacifique | 638 | 82 | 111 |
| Puissant | 551 | 70 | 96 |
| Triste | 474 | 51 | 70 |
| Effrayé | 941 | 127 | 116 |
Des clips vidéo de cet ensemble de données peuvent être téléchargés à partir de ce lien. Les fichiers d'annotation peuvent être trouvés sur https://github.com/SenticNet/MELD/tree/master/data/emorynlp. Il existe 3 fichiers .csv. Chaque entrée de la première colonne de ces fichiers csv contient un énoncé dont le clip vidéo correspondant peut être trouvé ici. Chaque énoncé et son clip vidéo sont indexés par numéro de saison, numéro d'épisode, identifiant de scène et identifiant d'énoncé. Par exemple, sea1_ep2_sc6_utt3.mp4 implique que le clip correspond à l'énoncé avec la saison n°. 1, épisode n° 2, scene_id 6 et utterance_id 3. Une scène est simplement un dialogue. Cette indexation est cohérente avec l'ensemble de données d'origine. Les fichiers .csv et les fichiers vidéo sont divisés en ensembles d'entraînement, de validation et de test conformément à l'ensemble de données d'origine. Les annotations ont été directement empruntées à l'ensemble de données original EmoryNLP (Zahiri et al. (2018)).
| Nom de la colonne | Description |
|---|---|
| Énonciation | Énoncés individuels d'EmoryNLP sous forme de chaîne. |
| Conférencier | Nom du locuteur associé à l'énoncé. |
| Émotion | L'émotion (neutre, joyeuse, paisible, puissante, effrayée, folle et triste) exprimée par le locuteur dans l'énoncé. |
| ID_scène | L'index du dialogue à partir de 0. |
| ID_énoncé | L'indice de l'énoncé particulier dans le dialogue à partir de 0. |
| Saison | La saison non. de l'émission télévisée Friends à laquelle appartient un énoncé particulier. |
| Épisode | L'épisode n°. de l'émission télévisée Friends dans une saison particulière à laquelle appartient l'énoncé. |
| Heure de début | L'heure de début de l'énoncé dans l'épisode donné au format « hh:mm:ss,ms ». |
| Heure de fin | L'heure de fin de l'énoncé dans l'épisode donné au format « hh:mm:ss,ms ». |
Remarque : Il y a quelques énoncés pour lesquels nous n'avons pas pu trouver l'heure de début et de fin en raison de quelques incohérences dans les sous-titres. De tels énoncés ont été omis de l'ensemble de données. Cependant, nous encourageons les utilisateurs à rechercher les énoncés correspondants dans l'ensemble de données d'origine et à générer des clips vidéo pour ceux-ci.
Veuillez citer les articles suivants si vous trouvez cet ensemble de données utile dans votre recherche
S. Zahiri et JD Choi. Détection d'émotions dans les transcriptions d'émissions télévisées avec des réseaux de neurones convolutifs basés sur des séquences. Dans l'atelier AAAI sur l'analyse du contenu affectif, AFFCON'18, 2018.
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD : un ensemble de données multimodales multipartites pour la reconnaissance des émotions dans les conversations. LCA 2019.


