ChatLearner
1.0.0
Un chatbot implémenté dans TensorFlow basé sur le nouveau modèle séquence à séquence (NMT), avec certaines règles parfaitement intégrées.
Pour ceux qui sont intéressés par les chatbots en chinois, veuillez vérifier ici.
Le cœur de ChatLearner (Papaya) a été construit sur le modèle NMT (https://github.com/tensorflow/nmt), qui a été adapté ici pour répondre aux besoins d'un chatbot. En raison des modifications apportées à l'API tf.data dans TensorFlow 1.4 et de nombreuses autres modifications depuis TensorFlow 1.12, cette version de ChatLearner ne prend en charge que les versions TF 1.4 à 1.11. Des mises à jour faciles peuvent être effectuées dans le fichier tokenizeddata.py si vous devez prendre en charge TensorFlow 1.12.
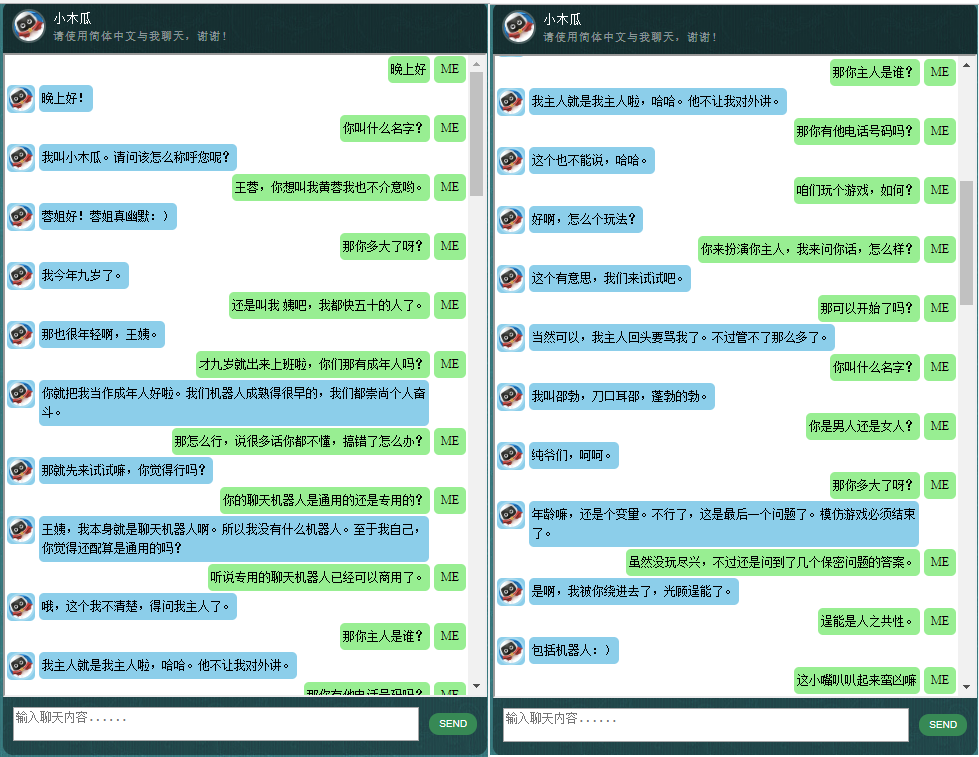
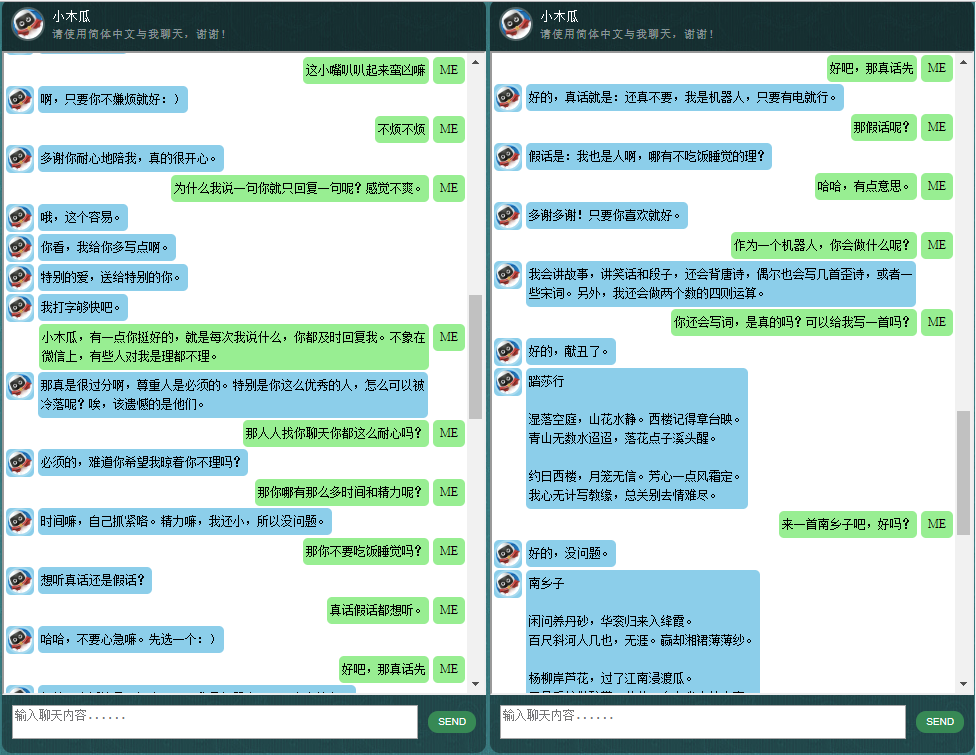
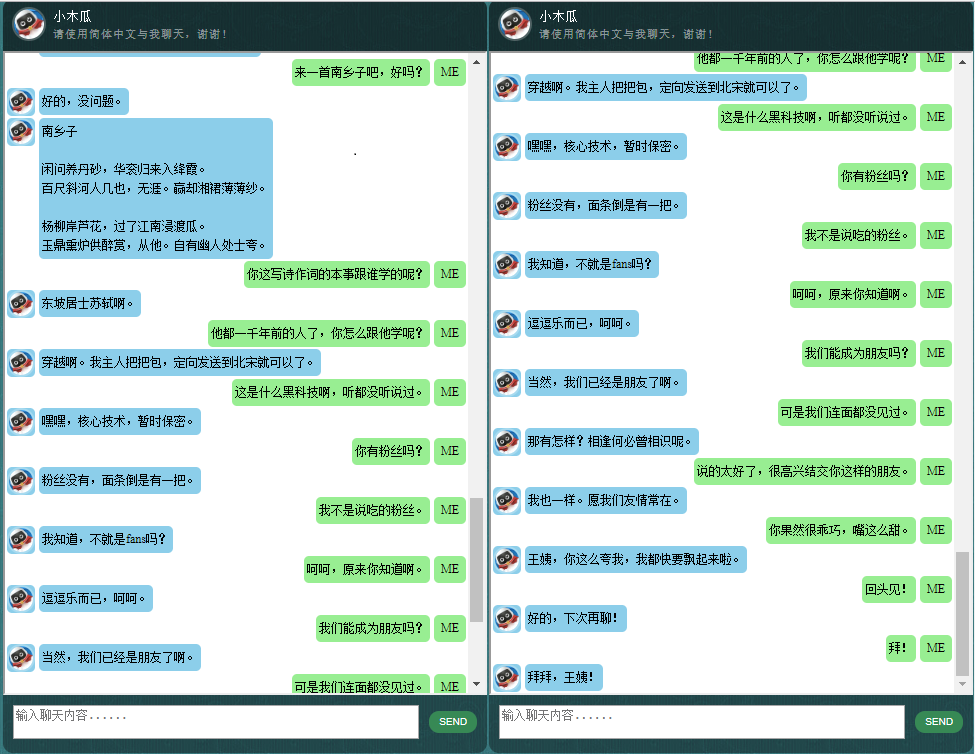
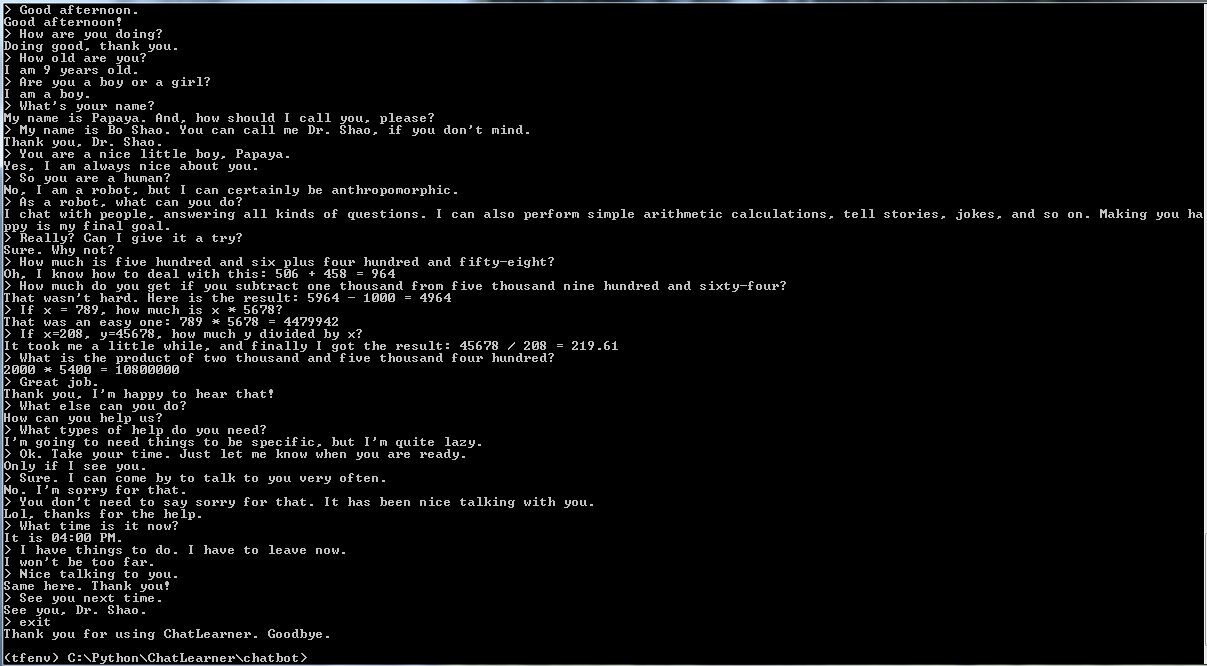
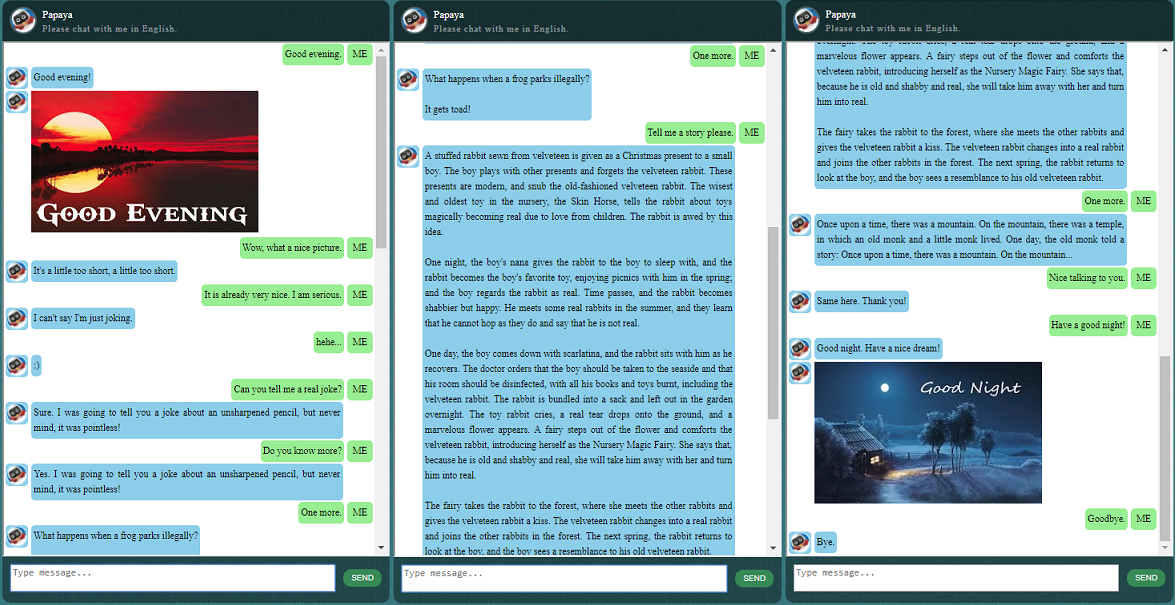
Avant de commencer tout le reste, vous voudrez peut-être avoir une idée du comportement de ChatLearner. Jetez un œil à l'exemple de conversation ci-dessous ou ici, ou si vous préférez essayer mon modèle formé, téléchargez-le ici. Décompressez le fichier .rar téléchargé et copiez le dossier Résultat dans le dossier Données sous la racine de votre projet. Un fichier vocab.txt est également inclus au cas où je le mettrais à jour sans mettre à jour le modèle entraîné à l'avenir.
Pourquoi voulez-vous passer du temps à vérifier ce référentiel ? Voici quelques raisons possibles :
L'ensemble de données Papaya pour la formation du chatbot. Vous pouvez facilement trouver des tonnes de données d’entraînement en ligne, mais vous ne pouvez en trouver aucune d’une telle qualité. Voir la description détaillée ci-dessous de l'ensemble de données.
Le style de code concis et la mise en œuvre claire du nouveau modèle seq2seq basé sur le RNN dynamique (alias le nouveau modèle NMT). Il est personnalisé pour les chatbots et beaucoup plus facile à comprendre que le tutoriel officiel.
L'idée d'utiliser ChatSession parfaitement intégré pour gérer le contexte conversationnel de base.
Certaines règles sont intégrées pour démontrer comment combiner les chatbots traditionnels basés sur des règles avec de nouveaux modèles d'apprentissage en profondeur. Quelle que soit la puissance d’un modèle d’apprentissage profond, il ne peut même pas répondre aux questions nécessitant de simples calculs arithmétiques, et bien d’autres. L'approche démontrée ici peut être facilement adaptée pour récupérer des actualités ou d'autres informations en ligne. Avec les règles mises en œuvre, il peut alors répondre correctement à de nombreuses questions intéressantes. Par exemple:
Si les règles ne vous intéressent pas, vous pouvez facilement supprimer les lignes liées à knowledgebase.py et functiondata.py.
Un service Web basé sur SOAP (et une alternative basée sur REST-API, si vous n'aimez pas utiliser SOAP) vous permet de présenter l'interface graphique en Java, tandis que le modèle est formé et exécuté en Python et TensorFlow.
Une solution simple (dans le graphique) pour convertir un tenseur de chaîne en minuscules dans TensorFlow. Il est requis si vous utilisez la nouvelle API DataSet (tf.data.TextLineDataSet) dans TensorFlow pour charger des données d'entraînement à partir de fichiers texte.
Le référentiel contient également une implémentation de chatbot basée sur l'ancien modèle seq2seq. Si cela vous intéresse, veuillez consulter la branche Legacy_Chatbot sur https://github.com/bshao001/ChatLearner/tree/Legacy_Chatbot.
Papaya Data Set est la meilleure (la plus propre et la mieux organisée) données conversationnelles en anglais gratuites que vous puissiez trouver sur le Web pour former un chatbot. Voici quelques détails :
Les données sont composées de deux ensembles : le premier ensemble a été fabriqué à la main, et nous avons créé les échantillons afin de conserver un rôle cohérent du chatbot, qui peut donc être formé pour être poli, patient, plein d'humour, philosophique et conscient qu'il est un robot, mais faites semblant d'être un garçon de 9 ans nommé Papaya ; le deuxième ensemble a été nettoyé de certaines ressources en ligne, notamment les conversations de scénario conçues pour l'entraînement des robots, les dialogues du film Cornell et les données Reddit nettoyées.
L'ensemble de données d'entraînement est divisé en trois catégories : deux sous-ensembles seront augmentés/répétés pendant l'entraînement, avec des niveaux ou des durées différents, tandis que le troisième ne le sera pas. Les sous-ensembles augmentés servent à entraîner le modèle avec des règles à suivre, ainsi que des connaissances et du bon sens, tandis que le troisième sous-ensemble sert simplement à aider à entraîner le modèle de langage.
Les conversations de scénario ont été extraites et réorganisées à partir de http://www.eslfast.com/robot/. Si votre modèle peut prendre en charge le contexte, il fonctionnerait bien mieux en utilisant ces conversations.
L’ensemble de données original de Cornell peut être trouvé ici. Nous l'avons nettoyé à l'aide d'un script Python (le script se trouve également dans le dossier Corpus) ; nous l'avons ensuite nettoyé manuellement en recherchant rapidement certains motifs.
Pour les données Reddit, un sous-ensemble nettoyé (environ 110 000 paires) est inclus dans ce référentiel. Le fichier de vocabulaire et les paramètres du modèle sont créés et ajustés en fonction de tous les fichiers de données inclus. Si vous avez besoin d'un ensemble plus grand, vous pouvez également trouver des scripts pour analyser et nettoyer les commentaires Reddit dans le dossier Corpus/RedditData. Pour utiliser ces scripts, vous devez télécharger un torrent de commentaires Reddit à partir d'un lien torrent ici. Normalement, un seul mois de commentaires est suffisant (peut générer environ 3 millions de paires d'échantillons d'entraînement). Vous pouvez ajuster les paramètres des scripts en fonction de vos besoins.
Les fichiers de données de cet ensemble de données ont déjà été prétraités avec le tokenizer NLTK afin qu'ils soient prêts à être intégrés au modèle à l'aide de la nouvelle API tf.data dans TensorFlow.
Veuillez vous assurer que vous disposez de la bonne version de TensorFlow. Cela fonctionne uniquement avec TensorFlow 1.4, pas avec les versions antérieures, car l'API tf.data utilisée ici a été récemment mise à jour dans TF 1.4.
Veuillez vous assurer que vous disposez de la configuration de la variable d'environnement PYTHONPATH. Il doit pointer vers le répertoire racine du projet, dans lequel vous avez le dossier chatbot, Data et webui. Si vous utilisez un IDE, tel que PyCharm, il le créera pour vous. Mais si vous exécutez des scripts Python dans une ligne de commande, vous devez disposer de cette variable d'environnement, sinon vous obtenez des erreurs d'importation de module.
Veuillez vous assurer que vous utilisez le même fichier vocab.txt pour la formation et l'inférence/prédiction. Gardez à l’esprit que votre modèle ne verra jamais aucun mot comme nous. Ce sont tous des entiers entrants, des entiers sortants, tandis que les mots et leurs ordres dans vocab.txt aident à établir une correspondance entre les mots et les entiers.
Passez un peu de temps à réfléchir à la taille de votre modèle, à la longueur maximale de l'encodeur/décodeur, à la taille de l'ensemble de vocabulaire et au nombre de paires de données d'entraînement que vous souhaitez utiliser. Sachez qu'un modèle a une limite de capacité : la quantité de données qu'il peut apprendre ou mémoriser. Lorsque vous disposez d'un nombre fixe de couches, d'un nombre d'unités, d'un type de cellule RNN (comme GRU) et que vous avez décidé de la longueur de l'encodeur/décodeur, c'est principalement la taille du vocabulaire qui a un impact sur la capacité d'apprentissage de votre modèle, et non le nombre de échantillons de formation. Si vous parvenez à ne pas laisser la taille du vocabulaire augmenter lorsque vous utilisez davantage de données d'entraînement, cela fonctionnera probablement, mais la réalité est que lorsque vous avez plus d'échantillons d'entraînement, la taille du vocabulaire augmente également très rapidement, et vous remarquerez peut-être alors votre modèle ne peut pas du tout prendre en charge cette taille de données. N'hésitez pas à ouvrir un ticket pour en discuter si vous le souhaitez.
Autre que Python 3.6 (3.5 devrait également fonctionner), Numpy et TensorFlow 1.4. Vous avez également besoin de NLTK (Natural Language Toolkit) version 3.2.4 (ou 3.2.5).
Pendant la formation, je vous suggère vraiment d'essayer de jouer avec un paramètre (colocate_gradients_with_ops) dans la fonction tf.gradients. Vous pouvez trouver une ligne comme celle-ci dans modelcreator.py : gradients = tf.gradients(self.train_loss, params). Définissez colocate_gradients_with_ops=True (en l'ajoutant) et exécutez la formation pendant au moins une époque, notez l'heure, puis définissez-la sur False (ou supprimez-la simplement) et exécutez la formation pendant au moins une époque et voyez si les temps sont requis pour une époque sont sensiblement différentes. Cela me choque au moins.
En dehors de cela, la formation est simple. N'oubliez pas de créer d'abord un dossier nommé Résultat sous le dossier Données. Ensuite, exécutez simplement les commandes suivantes :
cd chatbot
python bottrainer.pyDe bons GPU sont fortement recommandés pour la formation car cela peut prendre beaucoup de temps. Si vous disposez de plusieurs GPU, la mémoire de tous les GPU sera utilisée par TensorFlow et vous pouvez ajuster le paramètre batch_size dans le fichier hparams.json en conséquence pour utiliser pleinement la mémoire. Vous pourrez voir les résultats de l’entraînement sous le dossier Data/Result/. Assurez-vous que les 2 fichiers suivants existent, car ils seront tous nécessaires aux tests et à la prédiction (le fichier .meta est facultatif car le modèle d'inférence sera créé indépendamment) :
Pour les tests et les prédictions, nous fournissons une interface de commande simple et une interface Web. Notez que le fichier vocab.txt (et les fichiers dans la Base de connaissances, pour ce chatbot) est également requis pour l'inférence. Afin de vérifier rapidement les performances du modèle entraîné, utilisez l'interface de commande suivante :
cd chatbot
python botui.pyAttendez jusqu'à ce que vous obteniez l'invite de commande ">".
Un résultat de test de démonstration est également fourni. Veuillez le vérifier pour voir comment ce chatbot se comporte maintenant : https://github.com/bshao001/ChatLearner/blob/master/Data/Test/responses.txt
Une architecture de services Web basée sur SOAP est implémentée, avec un serveur Python et un client Java. Une belle interface graphique est également incluse pour votre référence. Pour plus de détails, veuillez consulter : https://github.com/bshao001/ChatLearner/tree/master/webui. Veuillez noter que certaines informations (telles que les images) ne sont disponibles que sur l'interface Web (pas dans l'interface de ligne de commande).
Une alternative basée sur l'API REST est également proposée si SOAP n'est pas votre choix. Pour plus de détails, veuillez consulter : https://github.com/bshao001/ChatLearner/tree/master/webui_alternative. Certaines des dernières mises à jour peuvent ne pas être disponibles avec cette option. Fusionnez les modifications de l’autre option si vous devez l’utiliser.
Cadre de balisage NLP (自然语言处理标记框架),试图实现对特定领域问题的精准回复,并可以解决很多对话中的复杂的上下文相关问题。本方法尤其适用于商业上的专用(面向任务的)服务等。有兴趣的朋友欢迎微信联系。本人微信号:bshao001_miami