Dialog
1.0.0
Dialog est un projet de chatbot japonais.
L'architecture utilisée dans ce projet est le modèle EncoderDecoder qui possède un encodeur BERT et un décodeur Transformer.
Article rédigé en japonais.
Vous pouvez exécuter un script de formation et d'évaluation sur Google Colab sans créer d'environnement.
Veuillez cliquer sur le lien suivant.
Notez que dans le cahier de formation, la commande de téléchargement est décrite à la fin de la note, mais elle n'a pas encore été testée. Par conséquent, si vous exécutez un carnet d'entraînement et que vous ne parvenez pas à télécharger un fichier de poids entraîné, veuillez le télécharger manuellement.
blog écrit en japonais
@ycat3 a créé un exemple de synthèse vocale en utilisant ce projet pour la génération de phrases et Parallel Wavenet pour la synthèse vocale. Le code source n'est pas partagé, mais vous pouvez le reproduire si vous utilisez Parallel Wavenet. Ce blog contient des échantillons audio, alors essayez de les écouter.
J'aimerais créer une application nous permettant de parler avec l'IA en voix en utilisant la synthèse vocale et la reconnaissance vocale si j'ai beaucoup de temps libre, mais maintenant je ne peux pas le faire à cause de la préparation des examens...
2époques
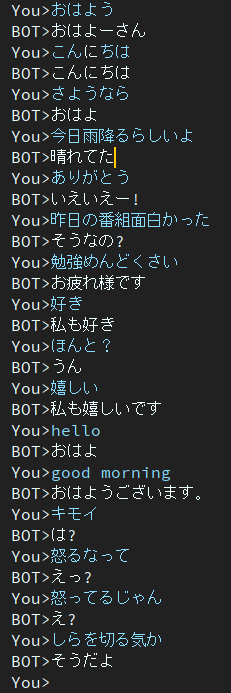
Ce modèle contient toujours le problème de la réponse sourde.
Pour résoudre ce problème, je recherche maintenant.
Ensuite, j'ai découvert que le document abordait ce problème.
Une autre fonction objective favorisant la diversité pour la génération d’un dialogue neuronal
Les auteurs appartiennent à l’Institut des sciences et technologies de Nara, également connu sous le nom de NAIST.
Ils proposent la nouvelle fonction objective de génération de dialogue neuronal.
J'espère que cette méthode pourra m'aider à résoudre ce problème.
dans Google Drive.
Les packages nécessaires sont
Si des erreurs se produisent à cause des packages, veuillez installer les packages manquants.
Exemple si vous utilisez conda.
# create new environment
$ conda create -n dialog python=3.7
# activate new environment
$ activate dialog
# install pytorch
$ conda install pytorch torchvision cudatoolkit={YOUR_VERSION} -c pytorch
# install rest of depending package except for MeCab
$ pip install transformers tqdm neologdn emoji
# #### Already installed MeCab #####
# ## Ubuntu ###
$ pip install mecab-python3
# ## Windows ###
# check that "path/to/MeCab/bin" are added to system envrionment variable
$ pip install mecab-python-windows
# #### Not Installed MeCab #####
# install Mecab in accordance with your OS.
# method described in below is one of the way,
# so you can use your way if you'll be able to use transformers.BertJapaneseTokenizer.
# ## Ubuntu ###
# if you've not installed MeCab, please execute following comannds.
$ apt install aptitude
$ aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
$ pip install mecab-python3
# ## Windows ###
# Install MeCab from https://github.com/ikegami-yukino/mecab/releases/tag/v0.996
# and add "path/to/Mecab/bin" to system environment variable.
# then run the following command.
$ pip install mecab-python-windows # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_training_data'si vous êtes prêt à commencer la formation, exécutez le script principal.
$ python main.py # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_pretrained'$ python run_eval.pySi vous souhaitez obtenir plus de données de conversation, veuillez utiliser get_tweet.py
Notez que vous devez modifier consumer_key et access_token pour pouvoir utiliser ce script.
Et puis, exécutez les commandes suivantes.
# usage
$ python get_tweet.py " query " " Num of continuous utterances "
# Example
# This command works until occurs errors
# and makes a file named "tweet_data_私は_5.txt" in "./data"
$ python get_tweet.py 私は 5Si vous exécutez la commande Exemple, le script commence à collecter 5 phrases consécutives si la dernière phrase contient "私は".
Quelle que soit la manière dont vous définissez 3 nombres ou plus sur "énoncés continus", make_training_data.py crée automatiquement une paire d'énoncés.
Exécutez ensuite la commande suivante.
$ python make_training_data.pyCe script crée des données d'entraînement en utilisant './data/tweet_data_*.txt', tout comme le nom.
Encodeur : BERT
Décodeur : Décodeur de Vanilla Transformer
Perte : CrossEntropy
Optimiseur : AdamW
Tokenizer : BertJapaneseTokenizer
Si vous souhaitez plus d'informations sur l'architecture de BERT ou de Transformer, veuillez vous référer à l'article suivant.


