Seq2seqChatbots
1.0.0
Un wrapper autour de tensor2tensor pour former, interagir et générer des données de manière flexible pour les chatbots neuronaux.
Le wiki contient mes notes et résumés de plus de 150 publications récentes liées à la modélisation du dialogue neuronal.
? Organisez vos propres formations ou expérimentez avec des modèles pré-entraînés
✅ 4 ensembles de données de dialogue différents intégrés à tensor2tensor
? Fonctionne de manière transparente avec n'importe quel modèle ou hyperparamètre défini dans tensor2tensor
Classe de base facilement extensible pour les problèmes de dialogue
Exécutez setup.py qui installe les packages requis et vous guide dans le téléchargement de données supplémentaires :
python setup.py
Vous pouvez télécharger tous les modèles entraînés utilisés dans cet article à partir d'ici. Chaque formation contient deux points de contrôle, un pour la perte minimale de validation et un autre après 150 époques. Les données et la structure des dossiers de formations correspondent exactement.
python t2t_csaky/main.py --mode=train
L'argument mode peut être l'un des quatre suivants : {generate_data, train, decode, experimental} . En mode expérience , vous pouvez spécifier quoi faire dans la fonction expérience du fichier d'exécution . Une explication détaillée est donnée ci-dessous pour ce que fait chaque mode.
Vous pouvez contrôler les drapeaux et paramètres de chaque mode directement dans ce fichier. Pour chaque exécution que vous lancez, ce fichier sera copié dans le répertoire approprié, afin que vous puissiez accéder rapidement aux paramètres de n'importe quelle exécution. Il y a quelques indicateurs que vous devez définir pour chaque mode (le dictionnaire FLAGS dans le fichier de configuration) :
t2t_usr_dir : Chemin d'accès au répertoire où réside mon code. Vous n'êtes pas obligé de modifier cela, sauf si vous renommez le répertoire.
data_dir : Le chemin d'accès au répertoire dans lequel vous souhaitez générer les paires source et cible, ainsi que d'autres données. L'ensemble de données sera téléchargé un niveau supérieur de ce répertoire dans un dossier raw_data .
problème : C'est le nom d'un problème enregistré dont tensor2tensor a besoin. Détaillé dans la section generate_data ci-dessous. Tous les chemins doivent provenir de la racine du dépôt.
Ce mode téléchargera et prétraitera les données et générera des paires source et cible. Actuellement, il y a 6 problèmes enregistrés, que vous pouvez utiliser en plus de ceux donnés par tensor2tensor :
persona_chat_chatbot : Ce problème implémente l'ensemble de données Persona-Chat (sans utilisation de personas).
daily_dialog_chatbot : Ce problème implémente l'ensemble de données DailyDialog (sans utiliser de sujets, d'actes de dialogue ou d'émotions).
opensubtitles_chatbot : Ce problème peut être utilisé pour travailler avec l'ensemble de données OpenSubtitles.
cornell_chatbot_basic : Ce problème implémente le Cornell Movie-Dialog Corpus.
cornell_chatbot_separate_names : Ce problème utilise le même corpus Cornell, cependant les noms des locuteurs et des destinataires de chaque énoncé sont ajoutés, ce qui donne des énoncés sources comme ci-dessous.
BIANCA_m0 que de bonnes choses ? CAMERON_m0
Character_chatbot : Il s'agit d'un problème général basé sur les caractères qui fonctionne avec n'importe quel ensemble de données. Avant d'utiliser cela, les fichiers .txt générés par l'un des problèmes ci-dessus doivent être placés dans le répertoire de données, et après cela, ce problème peut être utilisé pour générer des fichiers de données basés sur des caractères tensor2tensor.
Le dictionnaire PROBLEM_HPARAMS dans le fichier de configuration contient des paramètres spécifiques au problème que vous pouvez définir avant de générer des données :
num_train_shards / num_dev_shards : Si vous souhaitez que les données de train ou de développement générées soient partagées sur plusieurs fichiers.
vocabulaire_size : Taille du vocabulaire que nous voulons utiliser pour le problème. Les mots en dehors de ce vocabulaire seront remplacés par le jeton.
dataset_size : Nombre de paires d'énoncés, si nous ne voulons pas utiliser l'ensemble de données complet (défini par 0).
dataset_split : spécifiez une répartition train-val-test pour le problème.
dataset_version : Ceci ne concerne que l'ensemble de données opensubtitles, puisqu'il existe plusieurs versions de cet ensemble de données, vous pouvez spécifier l'année de l'ensemble de données que vous souhaitez télécharger.
name_vocab_size : Ceci ne concerne que le problème Cornell avec des noms séparés. Vous pouvez définir la taille du vocabulaire contenant uniquement les personas.
Ce mode vous permet d'entraîner un modèle avec le problème et les hyperparamètres spécifiés. Le code appelle simplement le script de formation tensor2tensor, de sorte que n'importe quel modèle présent dans tensor2tensor peut être utilisé. En plus de cela, il existe également un modèle sous-classé avec de petites modifications :
gradient_checkpointed_seq2seq : Petite modification du modèle seq2seq basé sur lstm, afin que ses propres hparams puissent être entièrement utilisés. Avant de calculer le softmax, les unités cachées LSTM sont projetées sur 2048 unités linéaires comme ici. Enfin, j'ai essayé d'implémenter des points de contrôle de dégradé sur ce modèle, mais il est actuellement supprimé car il n'a pas donné de bons résultats.
Il existe plusieurs indicateurs supplémentaires que vous pouvez spécifier pour une exécution de formation dans le dictionnaire FLAGS du fichier de configuration, dont :
train_dir : Nom du répertoire où les fichiers de point de contrôle de formation seront enregistrés.
model : Nom du modèle : soit l'un des modèles ci-dessus, soit un modèle défini tensor2tensor.
hparams : Spécifiez un hparams_set enregistré, ou laissez vide si vous souhaitez définir hparams dans le fichier de configuration. Afin de spécifier des hparams pour un modèle seq2seq ou transformer , vous pouvez utiliser les dictionnaires SEQ2SEQ_HPARAMS et TRANSFORMER_HPARAMS dans le fichier de configuration (vérifiez-le pour plus de détails).
Avec ce mode, vous pouvez décoder à partir des modèles formés. Les paramètres suivants affectent le décodage (dans le dictionnaire FLAGS dans le fichier de configuration) :
decode_mode : Peut être interactif , où vous pouvez discuter avec le modèle à l'aide de la ligne de commande. Le mode fichier vous permet de spécifier un fichier avec des énoncés sources pour lesquels générer des réponses, et le mode ensemble de données échantillonnera de manière aléatoire les données de validation fournies et affichera les réponses.
decode_dir : répertoire dans lequel vous pouvez fournir un fichier à partir duquel décoder et les réponses générées seront enregistrées ici.
input_file_name : Nom du fichier que vous devez donner en mode fichier (placé dans le decode_dir ).
output_file_name : Nom du fichier, à l'intérieur dedecode_dir , où les réponses de sortie seront enregistrées.
Beam_size : Taille de la poutre, lors de l'utilisation de la recherche de poutre.
return_beams : Si False, renvoie uniquement la poutre supérieure, sinon renvoie le nombre de poutres Beam_size .
Les résultats suivants sont issus de ces deux articles.
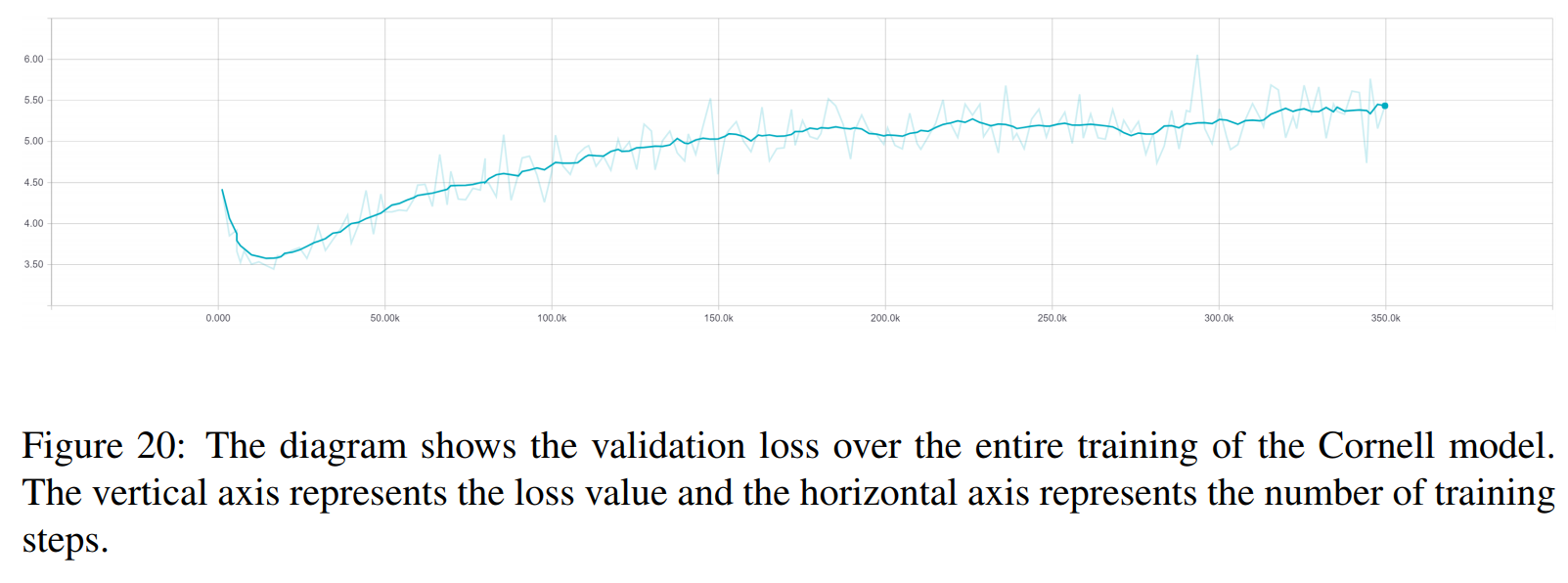

TRF est le modèle Transformer, tandis que RT signifie des réponses sélectionnées au hasard dans l'ensemble d'entraînement et GT signifie des réponses de vérité terrain. Pour une explication des métriques, voir le document.
S2S est un simple modèle seq2seq avec des LSTM formés sur Cornell, d'autres sont des modèles Transformer. Opensubtitles F est pré-entraîné sur Opensubtitles et affiné sur Cornell. 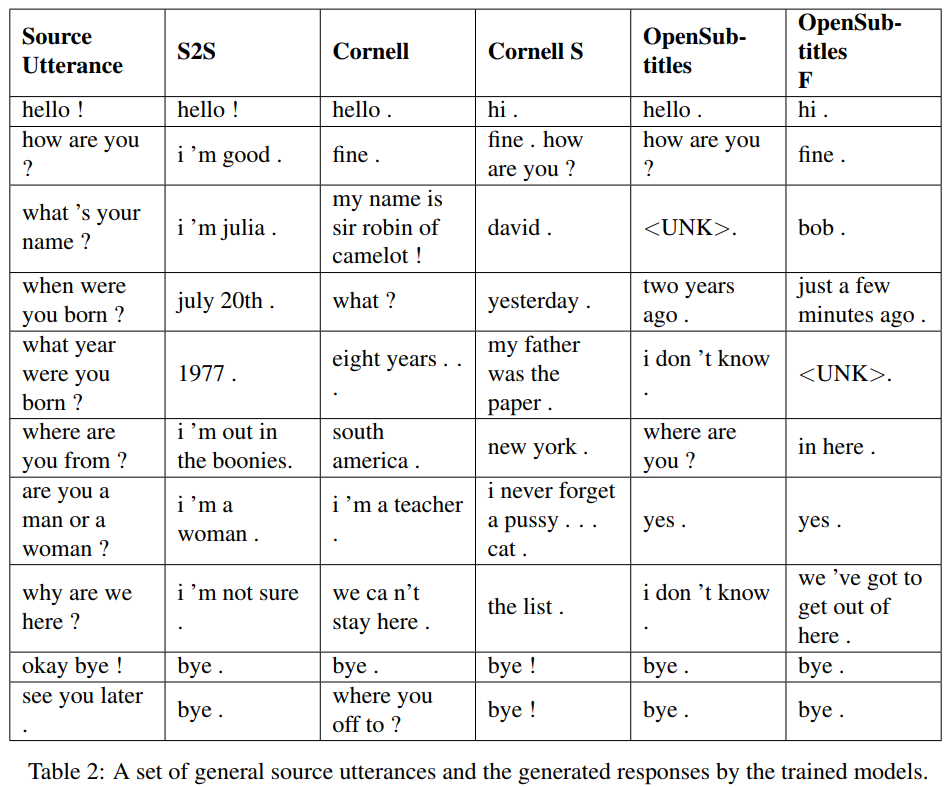
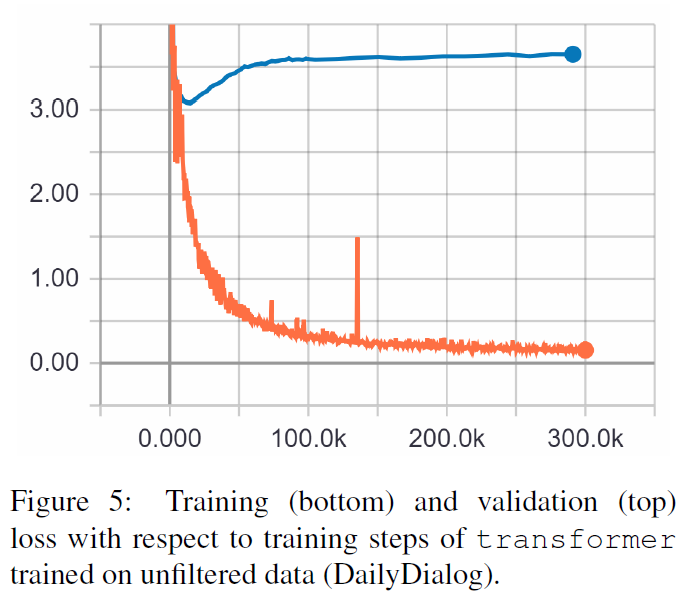

TRF est le modèle Transformer, tandis que RT signifie des réponses sélectionnées au hasard dans l'ensemble d'entraînement et GT signifie des réponses de vérité terrain. Pour une explication des métriques, voir le document.
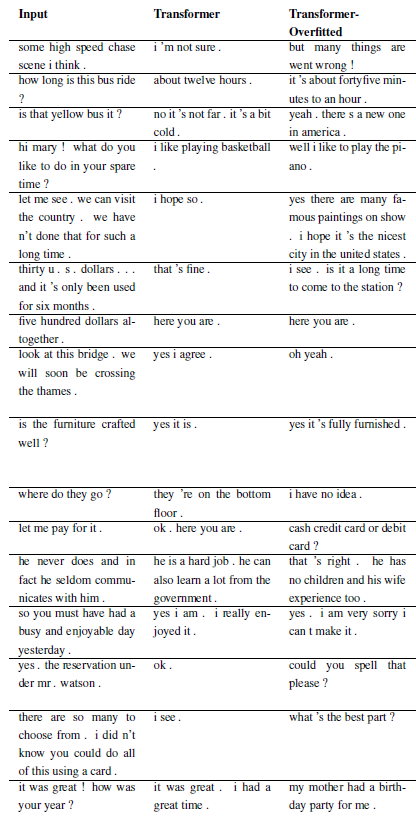
De nouveaux problèmes peuvent être enregistrés en sous-classant WordChatbot, ou mieux encore en sous-classant CornellChatbotBasic ou OpensubtitleChatbot, car ils implémentent des fonctionnalités supplémentaires. Il suffit généralement de remplacer les fonctions preprocess et create_data . Consultez la documentation pour plus de détails et consultez daily_dialog_chatbot pour un exemple.
De nouveaux modèles et hyperparamètres peuvent être ajoutés en suivant le didacticiel tensor2tensor.
Richard Csaky (Si vous avez besoin d'aide pour exécuter le code : [email protected])
Ce projet est sous licence MIT - voir le fichier LICENSE pour plus de détails.
Veuillez inclure un lien vers ce référentiel si vous l'utilisez dans votre travail et envisagez de citer l'article suivant :
@InProceedings{Csaky:2017,
title = {Deep Learning Based Chatbot Models},
author = {Csaky, Richard},
year = {2019},
publisher={National Scientific Students' Associations Conference},
url ={https://tdk.bme.hu/VIK/DownloadPaper/asdad},
note={https://tdk.bme.hu/VIK/DownloadPaper/asdad}
} 

