text dependency parser
1.0.0
Analyse des dépendances 
données
Exécuter le programme : former le modèle et évaluer
Parcourir les dépendances
Annexe : Parties de l'explication du discours
Annexe : Analyse syntaxique (arbre syntaxique)
Annexe : Représentation des relations
Description du format : Format CoNLL-U
Dans ce programme, au moins les 10 premières colonnes de données dans ce format sont requises :
| Liste | nom | signification |
|---|---|---|
| 1 | IDENTIFIANT | ID de mot à partir de 1 |
| 2 | FORMULAIRE | mot |
| 3 | LEMME | Racine anglaise, signification chinoise |
| 4 | ÉTAGÈRE SUPÉRIEURE | Parties du discours (un ensemble de parties du discours résumées dans toutes les langues) |
| 5 | XPOSTAG | Parties non universelles du discours (spécifiques à la langue) |
| 6 | FAITS | Caractéristiques morphologiques |
| 7 | TÊTE | Le nœud parent auquel appartient ce mot |
| 8 | DÉPRÉL | Relation avec le nœud parent |
| 9 | DÉPS | nœud secondaire associé |
| 10 | DIVERS | Autres informations supplémentaires |
Dans chacune des colonnes ci-dessus, une valeur de « _ » signifie indisponible.
Dans ce programme, les colonnes 3, 5, 6, 9 et 10 peuvent contenir « _ » et les autres colonnes doivent être des valeurs valides.
https://github.com/UniversalDependencies/UD_Chinese-GSD
https://github.com/UniversalDependencies/UD_English-EWT
Ensembles de formation et ensembles de développement fournis par l'Université Tsinghua et l'Institut de technologie de Harbin
Consultez d'autres ensembles de données.
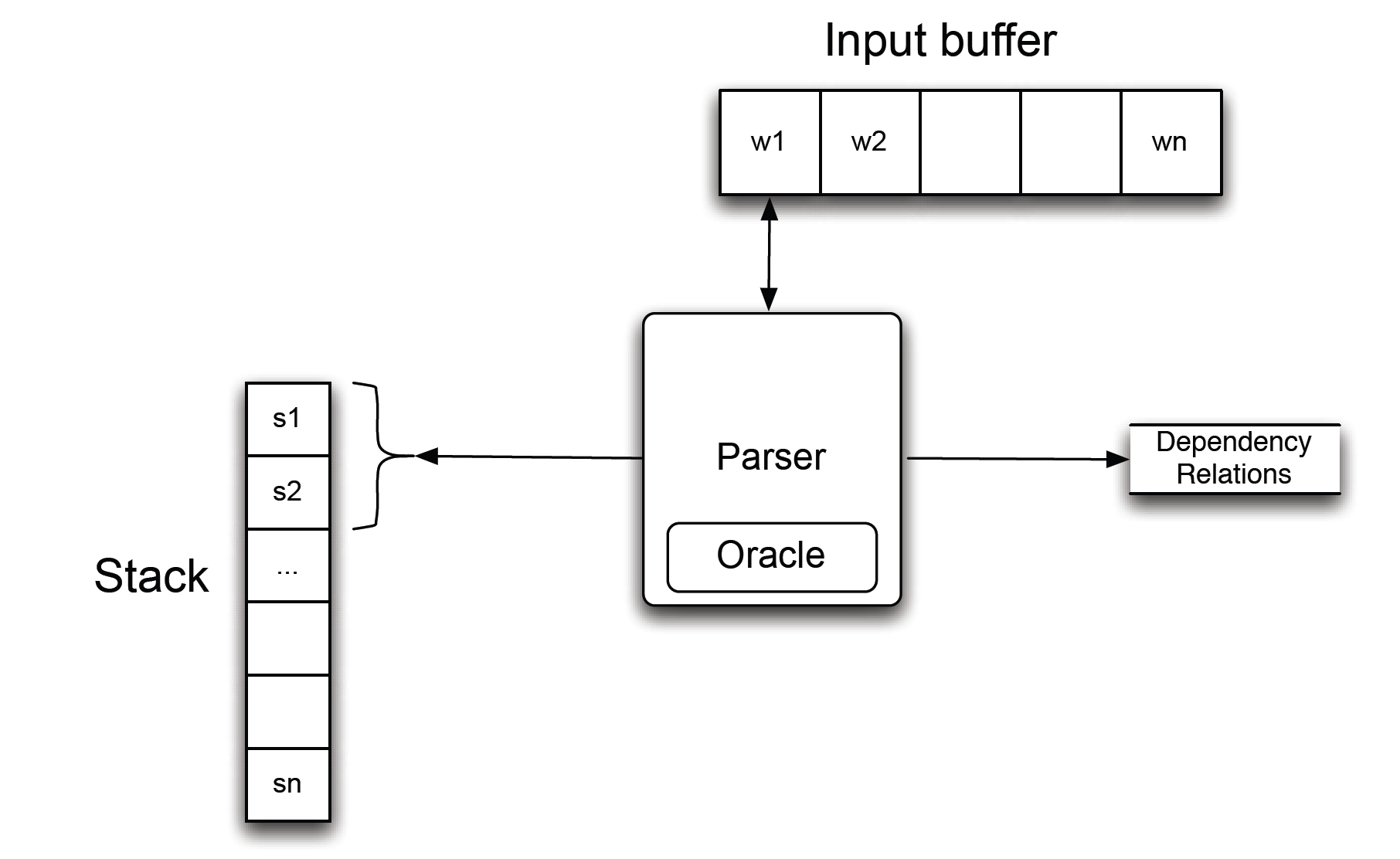
Introduction détaillée : analyse des dépendances
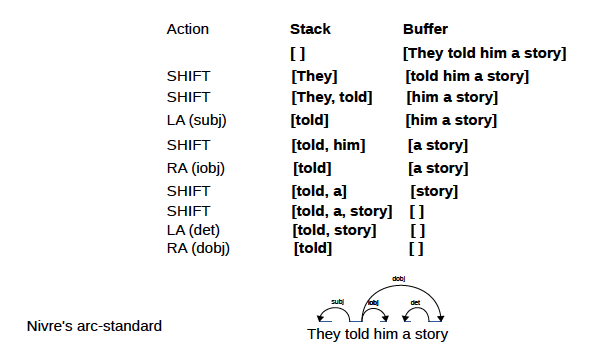
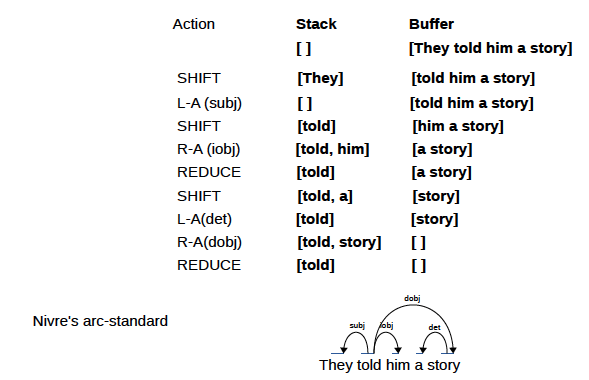
Lors de la mise à jour spécifique de l'arborescence des dépendances d'une phrase, il existe deux idées : standard (de bas en haut) et impatiente (de haut en bas).
Dépendances : py2.7
pip install -r requirements.txt
admin/standard.thu.train.sh # 训练中文模型
admin/standard.thu.test.sh # 测试中文模型
admin/standard.ewt.train.sh # 训练英文模型
admin/standard.ewt.test.sh # 测试英文模型
admin/eager.thu.train.sh # 训练中文模型
admin/eager.thu.test.sh # 测试中文模型
admin/eager.ewt.train.sh # 训练英文模型
admin/eager.ewt.test.sh # 测试英文模型
Résultats pour UD_Chinese-GSD :
I0316 23:19:25.249176 140736085984064 eager.py:152] accuracy: 0.760666326704
I0316 23:19:25.249367 140736085984064 eager.py:153] complete: 0.206
I0316 23:19:25.389566 140736085984064 eager.py:156] recall: 0.745088245088
I0316 23:19:25.391751 140736085984064 eager.py:158] precision: 0.760666326704
I0316 23:19:25.391916 140736085984064 eager.py:159] assigned: 0.97952047952
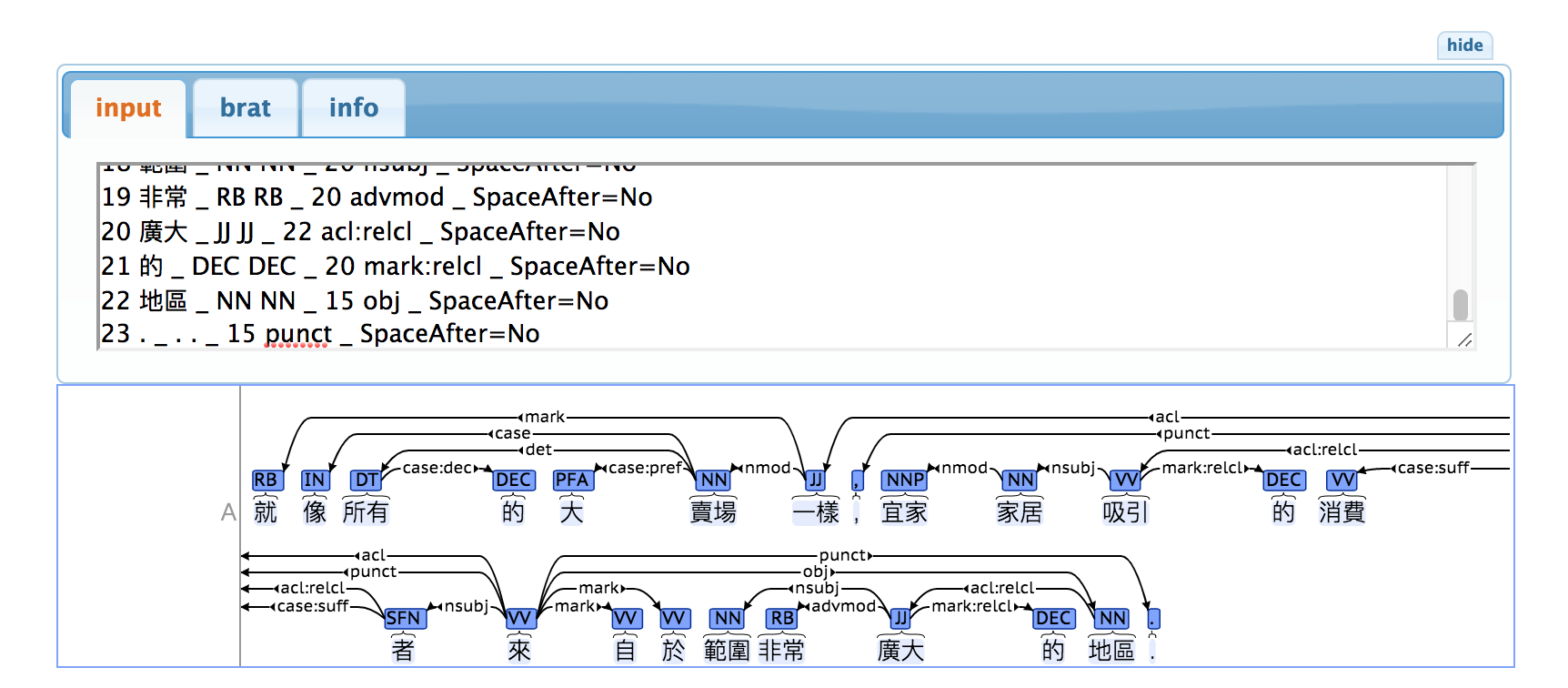
Utilisez conllu.js pour parcourir les dépendances : ouvrez la page Web, cliquez sur le bouton "modifier" et collez le contenu au format CoNLL-U dans l'éditeur. Par exemple, collez le contenu suivant dans la page Web conllu.js.
1 就 _ RB RB _ 7 mark _ SpaceAfter=No
2 像 _ IN IN _ 6 case _ SpaceAfter=No
3 所有 _ DT DT _ 6 det _ SpaceAfter=No
4 的 _ DEC DEC _ 3 case:dec _ SpaceAfter=No
5 大 _ PFA PFA _ 6 case:pref _ SpaceAfter=No
6 賣場 _ NN NN _ 7 nmod _ SpaceAfter=No
7 一樣 _ JJ JJ _ 15 acl _ SpaceAfter=No
8 , _ , , _ 15 punct _ SpaceAfter=No
9 宜家 _ NNP NNP _ 10 nmod _ SpaceAfter=No
10 家居 _ NN NN _ 11 nsubj _ SpaceAfter=No
11 吸引 _ VV VV _ 14 acl:relcl _ SpaceAfter=No
12 的 _ DEC DEC _ 11 mark:relcl _ SpaceAfter=No
13 消費 _ VV VV _ 14 case:suff _ SpaceAfter=No
14 者 _ SFN SFN _ 15 nsubj _ SpaceAfter=No
15 來 _ VV VV _ 0 root _ SpaceAfter=No
16 自 _ VV VV _ 15 mark _ SpaceAfter=No
17 於 _ VV VV _ 15 mark _ SpaceAfter=No
18 範圍 _ NN NN _ 20 nsubj _ SpaceAfter=No
19 非常 _ RB RB _ 20 advmod _ SpaceAfter=No
20 廣大 _ JJ JJ _ 22 acl:relcl _ SpaceAfter=No
21 的 _ DEC DEC _ 20 mark:relcl _ SpaceAfter=No
22 地區 _ NN NN _ 15 obj _ SpaceAfter=No
23 . _ . . _ 15 punct _ SpaceAfter=No
REMARQUE : incluez la ligne vide sous la ligne 17 lors du collage, car les lignes vides servent de marqueurs entre les phrases.
L’arbre de dépendances suivant est obtenu :
app/standard.py et app/eager.py sont des codes de formation, et l'implémentation principale de l'analyseur de transition se trouve dans app/transitionparser.py .
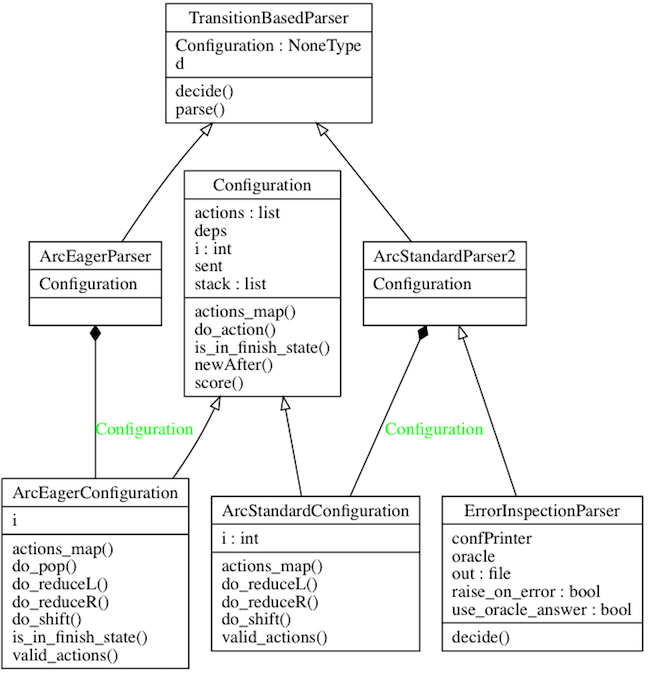
Dépendances : ArcEagerConfiguration --> ArcEagerParser, ArcStandardConfiguration --> ArcStandardParser2
Code: 
Code: 
Introduction à l'analyse syntaxique
Tâche partagée CoNLL-2009 : Dépendances syntaxiques et sémantiques dans plusieurs langues
Analyseurs de dépendances basés sur les transitions
conllu.js
python︱Essayez six modules de segmentation de mots chinois : jieba, THULAC, SnowNLP, pynlpir, CoreNLP, pyLTP
[1] Liang Huang, Wenbin Jiang et Qun Liu 2009. Analyse de réduction de décalage bilingue (monolingue).
CC: conjunction, coordinatin 表示连词
CD: numeral, cardinal 表示基数词
DT: determiner 表示限定词
EX: existential there 存在句
FW: foreign word 外来词
IN: preposition or conjunction, subordinating 介词或从属连词
JJ: adjective or numeral, ordinal 形容词或序数词
JJR: adjective, comparative 形容词比较级
JJS: adjective, superlative 形容词最高级
LS: list item marker 列表标识
MD: modal auxiliary 情态助动词
NN: noun, common, singular or mass
NNS: noun, common, plural
NNP: noun, proper, singular
NNPS: noun, proper, plural
PDT: pre-determiner 前位限定词
POS: genitive marker 所有格标记
PRP: pronoun, personal 人称代词
PRP:pronoun,possessive所有格代词RB:adverb副词RBR:adverb,comparative副词比较级RBS:adverb,superlative副词最高级RP:particle小品词SYM:symbol符号TO:”to”asprepositionorinfinitivemarker作为介词或不定式标记UH:interjection插入语VB:verb,baseformVBD:verb,pasttenseVBG:verb,presentparticipleorgerundVBN:verb,pastparticipleVBP:verb,presenttense,not3rdpersonsingularVBZ:verb,presenttense,3rdpersonsingularWDT:WH−determinerWH限定词WP:WH−pronounWH代词WP: WH-pronoun, possessive WH所有格代词
WRB:Wh-adverb WH副词
Norme chinoise de balisage de partie de discours : ensemble de balises de partie de discours ICTPOS3.0
ROOT:要处理文本的语句
IP:简单从句
NP:名词短语
VP:动词短语
PU:断句符,通常是句号、问号、感叹号等标点符号
LCP:方位词短语
PP:介词短语
CP:由‘的’构成的表示修饰性关系的短语
DNP:由‘的’构成的表示所属关系的短语
ADVP:副词短语
ADJP:形容词短语
DP:限定词短语
QP:量词短语
NN:常用名词
NR:固有名词:表示仅适用于该项事物的名词,含地名,人名,国名,书名,团体名称以及一事件的名称等。
NT:时间名词
PN:代词
VV:动词
VC:是
CC:表示连词
VE:有
VA:表语形容词
AS:内容标记(如:了)
VRD:动补复合词
CD: 表示基数词
DT: determiner 表示限定词
EX: existential there 存在句
FW: foreign word 外来词
IN: preposition or conjunction, subordinating 介词或从属连词
JJ: adjective or numeral, ordinal 形容词或序数词
JJR: adjective, comparative 形容词比较级
JJS: adjective, superlative 形容词最高级
LS: list item marker 列表标识
MD: modal auxiliary 情态助动词
PDT: pre-determiner 前位限定词
POS: genitive marker 所有格标记
PRP: pronoun, personal 人称代词
RB: adverb 副词
RBR: adverb, comparative 副词比较级
RBS: adverb, superlative 副词最高级
RP: particle 小品词
SYM: symbol 符号
TO:”to” as preposition or infinitive marker 作为介词或不定式标记
WDT: WH-determiner WH限定词
WP: WH-pronoun WH代词
WP$: WH-pronoun, possessive WH所有格代词
WRB:Wh-adverb WH副词
abbrev: abbreviation modifier,缩写
acomp: adjectival complement,形容词的补充;
advcl : adverbial clause modifier,状语从句修饰词
advmod: adverbial modifier状语
agent: agent,代理,一般有by的时候会出现这个
amod: adjectival modifier形容词
appos: appositional modifier,同位词
attr: attributive,属性
aux: auxiliary,非主要动词和助词,如BE,HAVE SHOULD/COULD等到
auxpass: passive auxiliary 被动词
cc: coordination,并列关系,一般取第一个词
ccomp: clausal complement从句补充
complm: complementizer,引导从句的词好重聚中的主要动词
conj : conjunct,连接两个并列的词。
cop: copula。系动词(如be,seem,appear等),(命题主词与谓词间的)连系
csubj : clausal subject,从主关系
csubjpass: clausal passive subject 主从被动关系
dep: dependent依赖关系
det: determiner决定词,如冠词等
dobj : direct object直接宾语
expl: expletive,主要是抓取there
infmod: infinitival modifier,动词不定式
iobj : indirect object,非直接宾语,也就是所以的间接宾语;
mark: marker,主要出现在有“that” or “whether”“because”, “when”,
mwe: multi-word expression,多个词的表示
neg: negation modifier否定词
nn: noun compound modifier名词组合形式
npadvmod: noun phrase as adverbial modifier名词作状语
nsubj : nominal subject,名词主语
nsubjpass: passive nominal subject,被动的名词主语
num: numeric modifier,数值修饰
number: element of compound number,组合数字
parataxis: parataxis: parataxis,并列关系
partmod: participial modifier动词形式的修饰
pcomp: prepositional complement,介词补充
pobj : object of a preposition,介词的宾语
poss: possession modifier,所有形式,所有格,所属
possessive: possessive modifier,这个表示所有者和那个’S的关系
preconj : preconjunct,常常是出现在 “either”, “both”, “neither”的情况下
predet: predeterminer,前缀决定,常常是表示所有
prep: prepositional modifier
prepc: prepositional clausal modifier
prt: phrasal verb particle,动词短语
punct: punctuation,这个很少见,但是保留下来了,结果当中不会出现这个
purpcl : purpose clause modifier,目的从句
quantmod: quantifier phrase modifier,数量短语
rcmod: relative clause modifier相关关系
ref : referent,指示物,指代
rel : relative
root: root,最重要的词,从它开始,根节点
tmod: temporal modifier
xcomp: open clausal complement
xsubj : controlling subject 掌控者
https://bot.chatopera.com/
Le service cloud Chatopera est un service cloud unique pour la mise en œuvre de robots de chat et est facturé en fonction du nombre d'appels d'interface. Chatopera Cloud Service est une instance Software-as-a-Service de la plateforme de robots Chatopera. Basé sur le cloud computing, le service cloud Chatopera est un service cloud chatbot-as-a-service .
La plate-forme robotique Chatopera comprend des composants tels qu'une base de connaissances, un dialogue multi-tours, une reconnaissance d'intention et une reconnaissance vocale, un développement de robot de chat standardisé et prend en charge des scénarios tels que des questions et réponses intelligentes en OA d'entreprise, des questions et réponses intelligentes en matière de RH, un service client intelligent et un marketing en ligne. Les services informatiques d'entreprise et les services commerciaux utilisent les services cloud Chatopera pour mettre rapidement les chatbots en ligne !
Dictionnaire personnalisé
Conditions personnalisées
Créer une intention
Ajouter des arguments et des emplacements
Modèle de formation
tester la conversation
Portrait de robot
Intégration du système
Historique des discussions
Utiliser maintenant