turing
v0.3.8
Viglet Turing ES (https://openviglet.github.io/turing/) est une solution open source (https://github.com/openturing), qui a la navigation sémantique et le chat bot comme principales fonctionnalités. Vous pouvez choisir parmi plusieurs NLP pour enrichir les données. Tout le contenu est indexé dans Solr en tant que moteur de recherche.
La documentation technique sur Turing ES est disponible sur https://openviglet.github.io/docs/turing/.
Pour exécuter Turing ES, exécutez simplement les lignes suivantes :
# Turing Appmvn -Dmaven.repo.local=D:repo spring-boot:run -pl turing-app -Dskip.npm# Nouvelle interface utilisateur Turing ES utilisant Angular 18 et Primer CSS.cd turing-ui## Loginng serve bienvenue## Consoleng servir console## Searchng servir sn## Chat botng servir converse
Vous pouvez démarrer Turing ES en utilisant MariaDB, Solr et Nginx.
docker-composer
Console d'administration : http://localhost:2700. (administrateur/administrateur)
Exemple de navigation sémantique : http://localhost:2700/sn/Sample.
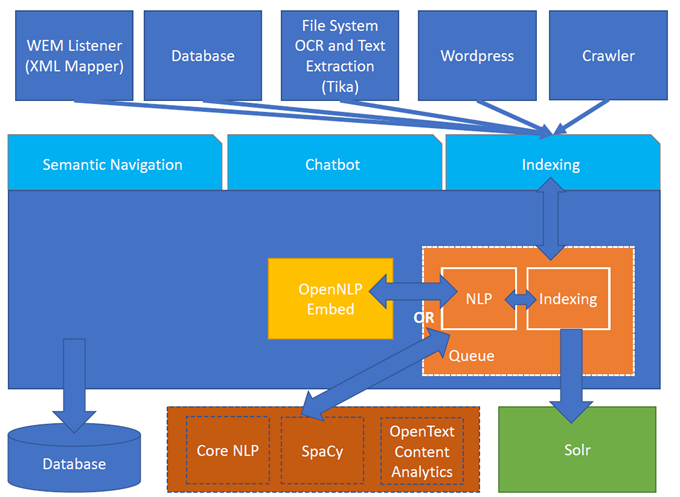
Figure 1. Architecture Turing ES
Turing prend en charge les fournisseurs suivants :
Apache OpenNLP est une boîte à outils basée sur l'apprentissage automatique pour le traitement de texte en langage naturel.
Site Web : https://opennlp.apache.org/
Il transforme les données en informations pour une meilleure prise de décision et une meilleure gestion de l'information tout en libérant des ressources et du temps.
Site Web : https://www.opentext.com/
CoreNLP est votre guichet unique pour le traitement du langage naturel en Java ! CoreNLP permet aux utilisateurs de dériver des annotations linguistiques pour le texte, y compris les limites de jetons et de phrases, les parties du discours, les entités nommées, les valeurs numériques et temporelles, les analyses de dépendances et de circonscriptions, la coréférence, les sentiments, les attributions de citations et les relations. CoreNLP prend actuellement en charge 6 langues : arabe, chinois, anglais, français, allemand et espagnol.
Site Web : https://stanfordnlp.github.io/CoreNLP/,
Il s'agit d'une bibliothèque open source gratuite pour le traitement du langage naturel en Python. Il comprend le NER, le marquage POS, l'analyse des dépendances, les vecteurs de mots et bien plus encore.
Site Web : https://spacy.io
Polyglot est un pipeline de langage naturel qui prend en charge des applications multilingues massives.
Site Web : https://polyglot.readthedocs.io
Il peut lire des PDF et des documents et les convertir en texte brut, et utilise également l'OCR pour détecter le texte dans les images et les images dans les documents.
La navigation sémantique utilise des connecteurs pour indexer le contenu de nombreuses sources.
Plugin pour Apache Nutch pour indexer le contenu à l'aide d'un robot d'exploration.
Apprenez-en plus sur https://docs.viglet.com/turing/connectors/#nutch
Ligne de commande qui utilise le même concept que sqoop (https://sqoop.apache.org/), pour créer des requêtes complexes et mapper les attributs à indexer en fonction du résultat.
Apprenez-en plus sur https://docs.viglet.com/turing/connectors/#database
Ligne de commande pour indexer des fichiers, extrayant le texte de fichiers tels que Word, Excel, PDF, y compris les images, via OCR.
Apprenez-en plus sur https://docs.viglet.com/turing/connectors/#file-system
OpenText WEM Listener pour publier du contenu sur Viglet Turing.
Apprenez-en plus sur https://docs.viglet.com/turing/connectors/#wem
Plugin WordPress qui permet d'indexer les publications.
Apprenez-en plus sur https://docs.viglet.com/turing/connectors/#wordpress
Avec le NLP, il est possible de détecter des entités telles que :
Personnes
Lieux
Organisations
Argent
Temps
Pourcentage
Définissez les attributs qui seront utilisés comme filtres pour votre navigation, en consolidant le contenu total de votre affichage
Grâce à des attributs définis dans les contenus, il est possible de les utiliser pour restreindre leur affichage en fonction du profil de l'utilisateur.
L'API Java (https://github.com/openturing/turing-java-sdk) facilite l'utilisation et l'accès à Viglet Turing ES, sans avoir besoin de contenu de recherche grand public avec des requêtes complexes.
Communiquez avec votre client et élaborez des intentions complexes, obtenez des rapports et faites évoluer progressivement votre interaction.
Ses composants :
Gère les conversations avec vos utilisateurs finaux. C'est un module de traitement du langage naturel qui comprend les nuances du langage humain
Une intention catégorise l’intention d’un utilisateur final de changer de conversation. Pour chaque agent, vous définissez plusieurs intentions, où vos intentions combinées peuvent gérer une conversation complète.
Le champ d'action est un simple champ de commodité qui permet d'exécuter la logique dans le service.
Chaque paramètre d'intention possède un type, appelé type d'entité, qui dicte exactement la manière dont les données d'une expression d'utilisateur final sont extraites.
Définit et corrige les intentions.
Affiche l'historique des conversations et les rapports.
Turing ES détecte les entités des documents OpenText Blazon à l'aide de l'OCR et du NLP, générant Blazon XML pour afficher les entités dans le document.
Turing ES comporte de nombreux composants : moteur de recherche, PNL, Converse (Chat bot), navigation sémantique
Lorsque vous accédez à Turing ES, une page de connexion apparaît. Par défaut, le login/mot de passe est admin / admin
Figure 2. Page de connexion
Le moteur de recherche est utilisé par Turing pour stocker et récupérer les données de Converse (Chat bot) et des sites de navigation sémantique.
Figure 3. Page du moteur de recherche
Il est possible de créer ou de modifier un moteur de recherche avec les attributs suivants :
| Attribut | Description |
|---|---|
Nom | Nom du moteur de recherche |
Description | Description du moteur de recherche |
Fournisseur | Sélectionnez le fournisseur du moteur de recherche. Pour l'instant, il ne prend en charge que Solr. |
Hôte | Nom d'hôte sur lequel le service Moteur de recherche est installé |
Port | Port du service de moteur de recherche |
Langue | Langue du service des moteurs de recherche. |
Activé | Si le moteur de recherche est activé. |
Figure 4. Page de navigation sémantique
Le Détail du Site de Navigation Sémantique contient les attributs suivants :
| Attribut | Description |
|---|---|
Nom | Nom du site de navigation sémantique. |
Description | Description du site de navigation sémantique. |
Moteur de recherche | Sélectionnez le moteur de recherche créé dans la section Moteur de recherche. Le site de navigation sémantique utilisera ce moteur de recherche pour stocker et récupérer des données. |
PNL | Sélectionnez le NLP créé dans la section NLP. Le site de navigation sémantique utilisera ce NLP pour détecter les entités lors de l'indexation. |
Thésaurus | Si vous utilisez le thésaurus. |
Langue | Langue du site de navigation sémantique. |
Cœur | Nom du noyau du moteur de recherche où seront stockées et récupérées les données. |
L'onglet Champs contient un tableau avec les colonnes suivantes : .Colonnes des champs du site de navigation sémantique
| Nom de la colonne | Description |
|---|---|
Taper | Type de champ. Cela peut être : - NER (Named Entity Recognition) utilisé par le NLP. - Moteur de recherche utilisé par Solr. |
Champ | Nom du champ. |
Activé | Si le champ est activé ou non. |
MLT | Si ce champ sera utilisé dans MLT. |
Facettes | Utiliser ce champ comme une facette (filtre) |
Mise en évidence | Si ce champ affichera les lignes en surbrillance. |
PNL | Si ce champ sera traité par NLP pour détecter des entités (NER) telles que des personnes, des organisations et des lieux. |
Lorsque vous cliquez dans Field, une nouvelle page avec les détails du champ apparaît avec les attributs suivants :
| Attribut | Description |
|---|---|
Nom | Nom du champ |
Description | Description du champ |
Taper | Type de champ. Il peut s'agir de : |
Valeurs multiples | Si est un tableau |
Nom de la facette | Nom de l’étiquette de la facette (filtre) sur la page de recherche. |
Facette | Utiliser ce champ comme une facette (filtre) |
Mise en évidence | Si ce champ affichera les lignes en surbrillance. |
MLT | Si ce champ sera utilisé dans MLT. |
Activé | Si le champ est activé. |
Requis | Si le champ est obligatoire. |
Valeur par défaut | Dans le cas où le contenu est indexé sans ces champs, c'est la valeur par défaut. |
PNL | Si ce champ sera traité par NLP pour détecter des entités (NER) telles que des personnes, des organisations et des lieux. |
Contient les attributs suivants :
| Section | Attribut | Description |
|---|---|---|
Apparence | Nombre d'éléments par page | Nombre d'éléments qui apparaîtront dans la recherche. |
Facette | Facette activée ? | Si ce sera afficher Facette (Filtres) lors de la recherche. |
Nombre d'éléments par facette | Nombre d'éléments qui apparaîtront dans chaque facette (filtre). | |
Mise en évidence | La mise en surbrillance est activée ? | Définissez s'il faut afficher les lignes en surbrillance. |
Pré-balise | Balise HTML qui sera utilisée en début de trimestre. Par exemple : <marque> | |
Balise de publication | Balise HTML qui sera utilisée à la fin du trimestre. Par exemple : </mark> | |
MLT | Plus comme ceci activé ? | Définir s'il faut afficher MLT |
Champs par défaut | Titre | Champ qui sera utilisé comme titre défini dans Solr schema.xml |
Texte | Champ qui sera utilisé comme titre défini dans Solr schema.xml | |
Description | Champ qui sera utilisé comme description définie dans Solr schema.xml | |
Date | Champ qui sera utilisé comme date définie dans Solr schema.xml | |
Image | Champ qui sera utilisé comme URL d'image définie dans Solr schema.xml | |
URL | Champ qui sera utilisé comme URL définie dans Solr schema.xml |
Dans Turing ES Console > Semantic Navigation > <SITE_NAME> , cliquez sur le bouton Configure et cliquez sur le bouton Search Page .
Cela ouvrira une page de recherche qui utilise le modèle :
OBTENIR http://localhost:2700/sn/<SITE_NAME>
Cette page demande l'API Turing Rest via AJAX. Par exemple, pour renvoyer tous les résultats du site de navigation sémantique au format JSON :
OBTENIR http://localhost:2700/api/sn/<SITE_NAME>/search?p=1&q=*&sort=relevance
| Attribut | Obligatoire / Facultatif | Description | Exemple |
|---|---|---|---|
q | Requis | Requête de recherche. | q=foo |
p | Requis | Numéro de page, la première page est 1. | p=1 |
trier | Requis | Trier les valeurs : | trier = pertinence |
fq[] | Facultatif | Champ de requête. Filtrez par champ, en utilisant le modèle suivant : FIELD : VALUE . | fq[]=titre:bar |
tr[] | Facultatif | Règle de ciblage. Restreindre la recherche en fonction de : FIELD : VALUE . | tr[]=département:foobar |
lignes | Facultatif | Nombre de lignes que la requête renverra. | lignes = 10 |
Sur l'intranet de la compagnie d'assurance qui utilise OpenText WEM et OpenText Portal intégré au module Dynamic Portal, une recherche consolidée a été créée dans Viglet Turing ES, en utilisant les connecteurs : WEM, Database with File System. De cette manière, il a été possible d'afficher tous les contenus et fichiers de l'Intranet de recherche, avec des règles de ciblage, permettant uniquement d'afficher le contenu pour lequel l'utilisateur a la permission. Le portail OpenText accède à l'API Java de Viglet Turing ES, il n'était donc pas nécessaire de créer des requêtes complexes pour renvoyer les résultats.
Un ensemble d'API Rest a été créé pour mettre tout le contenu de l'entreprise gouvernementale à la disposition des partenaires. Tous ces contenus sont dans OpenText WEM et le connecteur WEM a été utilisé pour indexer les contenus sur Viglet Turing ES. Une application Spring Boot a été créée avec l'ensemble d'API Rest qui consomme le contenu Turing ES via l'API Java Viglet Turing ES.
Le site Web de l'Université brésilienne a été développé à l'aide du CMS Viglet Shio (https://viglet.com/shio), et tous les contenus sont automatiquement indexés dans Viglet Turing ES. Cette configuration a été réalisée en modélisation de contenu et le développement du modèle de recherche a été réalisé dans Viglet Shio CMS.


