GenDataAttribution
1.0.0
Projet | Papier
Sheng-Yu Wang 1 , Alexei A. Efros 2 , Jun-Yan Zhu 1 , Richard Zhang 3 .
Université Carnegie Mellon 1 , UC Berkeley 2 , Adobe Research 2
Dans ICCV, 2023.
Même si les grands modèles de conversion texte-image sont capables de synthétiser des images « inédites », ces images sont nécessairement le reflet des données d'entraînement. Le problème de l’attribution des données dans de tels modèles – quelles images de l’ensemble d’apprentissage sont les plus responsables de l’apparence d’une image générée donnée – est un problème difficile mais important. Comme première étape vers ce problème, nous évaluons l’attribution au moyen de méthodes de « personnalisation », qui adaptent un modèle à grande échelle existant à un objet ou un style exemplaire donné. Notre idée clé est que cela nous permet de créer efficacement des images synthétiques qui sont influencées informatiquement par l'exemplaire par construction. Grâce à notre nouvel ensemble de données de ces images influencées par des exemples, nous sommes en mesure d'évaluer divers algorithmes d'attribution de données et différents espaces de fonctionnalités possibles. De plus, en nous entraînant sur notre ensemble de données, nous pouvons adapter les modèles standard, tels que DINO, CLIP et ViT, au problème d'attribution. Même si la procédure est adaptée aux petits ensembles exemplaires, nous montrons une généralisation à des ensembles plus grands. Enfin, en prenant en compte l'incertitude inhérente au problème, nous pouvons attribuer des scores d'attribution douce à un ensemble d'images d'entraînement.
conda env create -f environment.yaml
conda activate gen-attr # Download precomputed features of 1M LAION images
bash feats/download_laion_feats.sh
# Download jpeg-ed 1M LAION images for visualization
bash dataset/download_dataset.sh laion_jpeg
# Download pretrained models
bash weights/download_weights.sh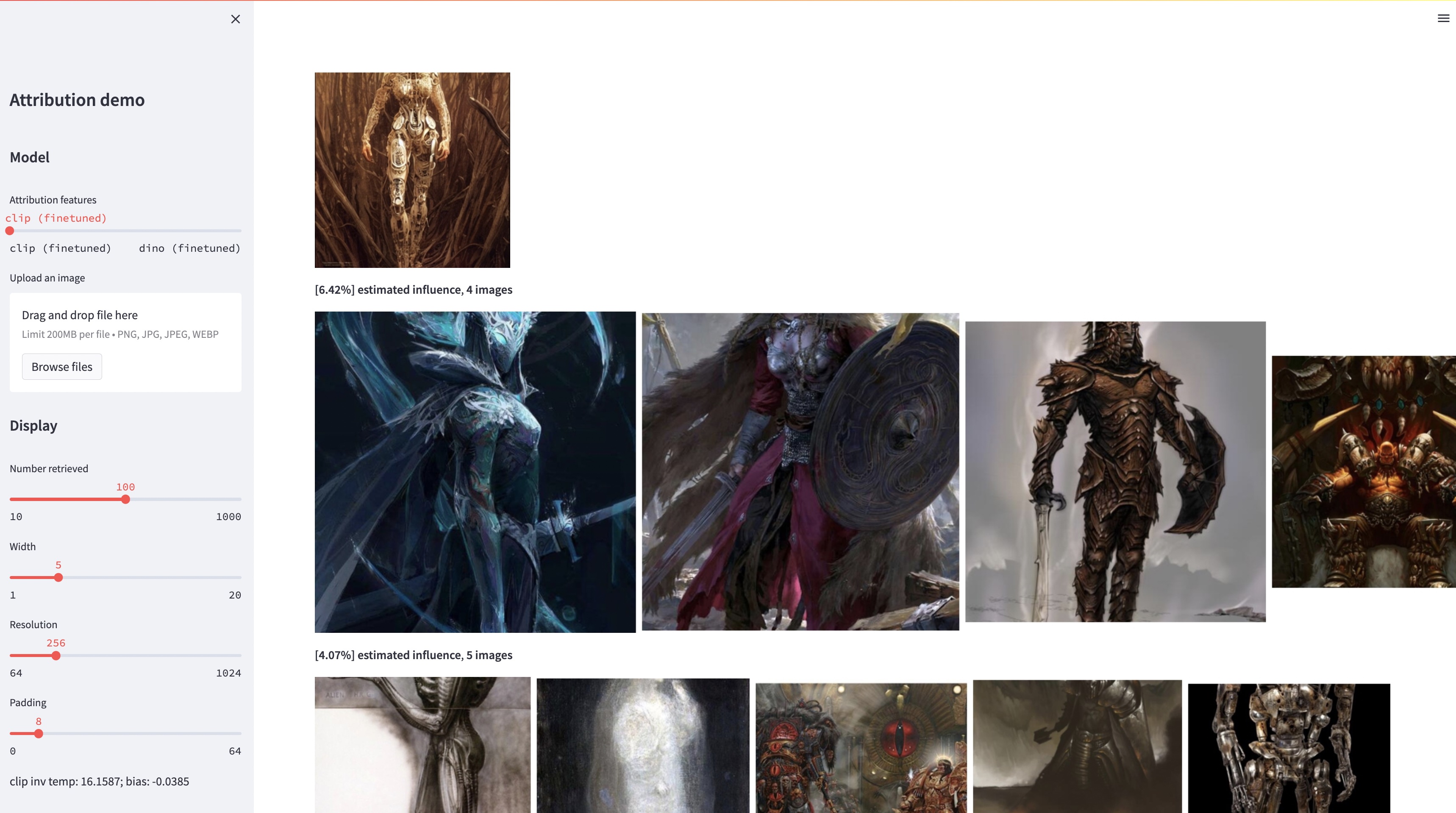
streamlit run streamlit_demo.pyNous publions notre ensemble de tests pour évaluation. Pour télécharger l'ensemble de données :
# Download the exemplar real images
bash dataset/download_dataset.sh exemplar
# Download the testset portion of images synthesized from Custom Diffusion
bash dataset/download_dataset.sh testset
# (Optional, can download precomputed features instead!)
# Download the uncompressed 1M LAION subset in pngs
bash dataset/download_dataset.sh laionL'ensemble de données est structuré comme suit :
dataset
├── exemplar
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── synth
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── laion_subset
└── json
├──test_artchive.json
├──test_bamfg.json
├──...
Toutes les images exemplaires sont stockées dans dataset/exemplar , toutes les images synthétisées sont stockées dans dataset/synth et 1 million d'images laion au format png sont stockées dans dataset/laion_subset . Les fichiers JSON dans dataset/json spécifient les répartitions train/val/test, y compris différents cas de test, et servent d'étiquettes de vérité terrain. Chaque entrée dans un fichier JSON est un modèle unique et affiné. Une entrée enregistre également la ou les images exemplaires utilisées pour le réglage fin et les images synthétisées générées par le modèle. Nous avons quatre cas de test : test_artchive.json , test_bamfg.json , test_observed_imagenet.json et test_unobserved_imagenet.json .
Une fois l'ensemble de tests, les fonctionnalités LAION précalculées et les poids pré-entraînés téléchargés, nous pouvons précalculer les fonctionnalités de l'ensemble de tests en exécutant extract_feat.py , puis évaluer les performances en exécutant eval.py . Vous trouverez ci-dessous les scripts bash qui exécutent l'évaluation par lots :
# precompute all features from the testset
bash scripts/preprocess_feats.sh
# run evaluation in batches
bash scripts/run_eval.sh Les métriques sont stockées dans des fichiers .pkl dans results . Actuellement, le script exécute chaque commande de manière séquentielle. N'hésitez pas à le modifier pour exécuter les commandes en parallèle. La commande suivante analysera les fichiers .pkl dans des tables stockées sous forme de fichiers .csv :
python results_to_csv.py Mise à jour du 18/12/2023 Pour télécharger des modèles formés uniquement sur des modèles centrés sur les objets ou centrés sur le style, exécutez bash weights/download_style_object_ablation.sh
@inproceedings{wang2023evaluating,
title={Evaluating Data Attribution for Text-to-Image Models},
author={Wang, Sheng-Yu and Efros, Alexei A. and Zhu, Jun-Yan and Zhang, Richard},
booktitle={ICCV},
year={2023}
}
Nous remercions Aaron Hertzmann pour avoir lu une version antérieure et pour ses commentaires perspicaces. Nous remercions nos collègues d'Adobe Research, notamment Eli Shechtman, Oliver Wang, Nick Kolkin, Taesung Park, John Collomosse et Sylvain Paris, ainsi qu'Alex Li et Yonglong Tian pour leurs discussions utiles. Nous apprécions Nupur Kumari pour ses conseils concernant la formation sur la diffusion personnalisée, Ruihan Gao pour la relecture du brouillon, Alex Li pour les pointeurs permettant d'extraire les fonctionnalités de diffusion stable et Dan Ruta pour son aide avec l'ensemble de données BAM-FG. Nous remercions Bryan Russell pour sa randonnée et son brainstorming en cas de pandémie. Ce travail a commencé lorsque SYW était stagiaire chez Adobe et a été soutenu en partie par un don d'Adobe et le prix de recherche universitaire JP Morgan Chase.


