auto rag eval
1.0.0
Ce référentiel accompagne l'article ICML 2024 Automated Evaluation of Retrieval-Augmented Language Models with Task-Specific Exam Generation (Blog)
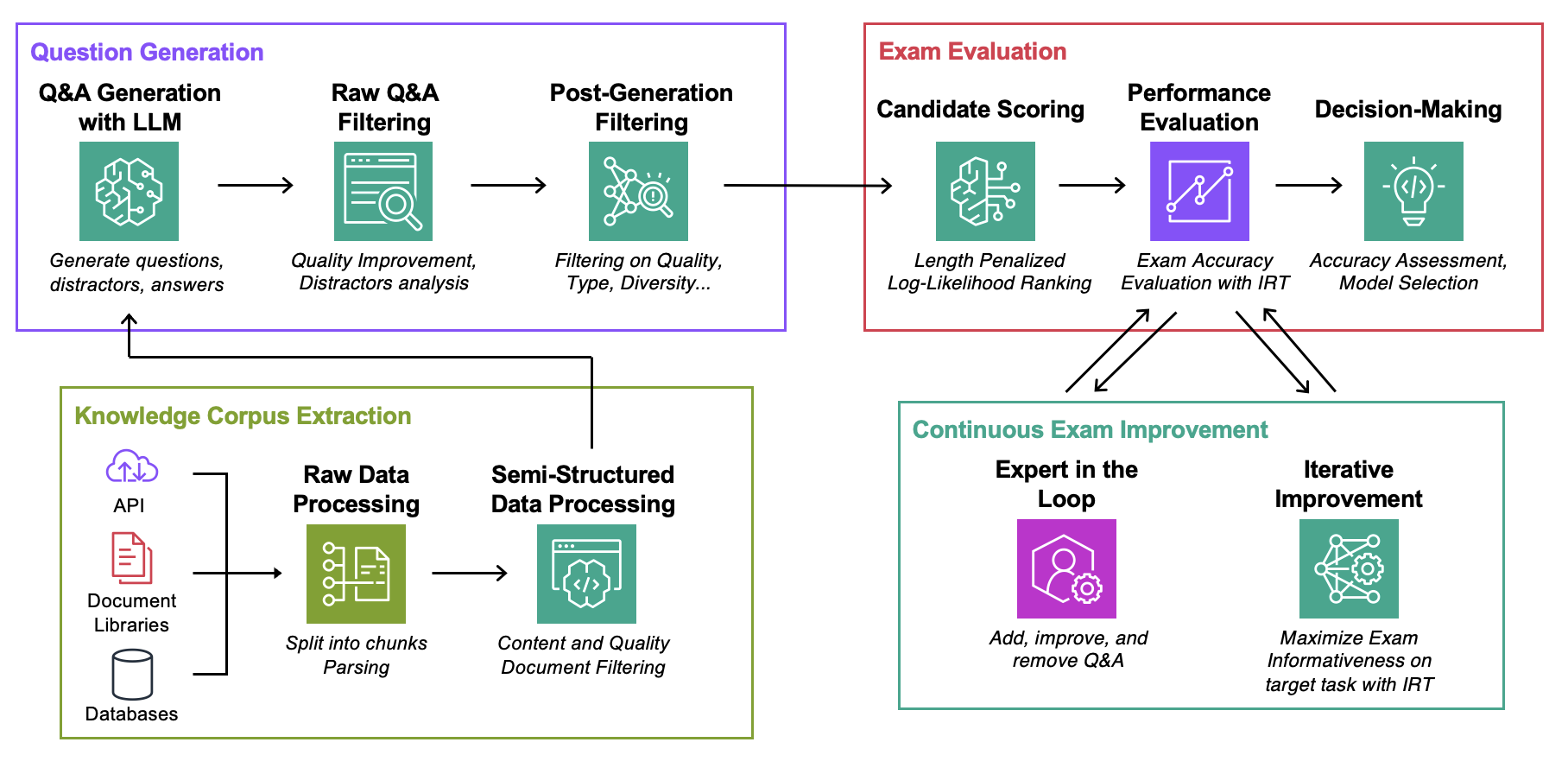
Objectif : Pour un corpus de connaissances donné :
La seule chose dont vous avez besoin pour expérimenter ce code est un fichier json avec votre corpus de connaissances au format décrit ci-dessous.
Data : Pour chaque cas d'utilisation, contient :ExamGenerator : Code pour générer et traiter l'examen à choix multiples à l'aide de corpus de connaissances et de générateur(s) LLM.ExamEvaluator : Code pour évaluer l'examen à l'aide d'une combinaison (Retrieval System, LLM, ExamCorpus) , s'appuyant sur la bibliothèque lm-harness .LLMServer : points de terminaison LLM unifiés pour générer l'examen.RetrievalSystems : Classes du système de récupération unifié (par exemple DPR, BM25, Embedding Similarity...). Nous illustrons notre méthodologie sur 4 tâches d'intérêt : AWS DevOPS Troubleshooting, StackExchange Q&A, Sec Filings Q&A et Arxiv Q&A. Nous montrons ensuite comment adapter la méthodologie à n'importe quelle tâche.
Exécutez les commandes ci-dessous, où question-date correspond aux données avec la génération de données brutes. Ajoutez --save-exam si vous souhaitez enregistrer l'examen et supprimez-le si vous n'êtes intéressé que par les analyses.
cd auto-rag-eval
rm -rf Data/StackExchange/KnowledgeCorpus/main/ *
python3 -m Data.StackExchange.preprocessor
python3 -m ExamGenerator.question_generator --task-domain StackExchange
python3 -m ExamGenerator.multi_choice_exam --task-domain StackExchange --question-date " question-date " --save-exam cd auto-rag-eval
rm -rf Data/Arxiv/KnowledgeCorpus/main/ *
python3 -m Data.Arxiv.preprocessor
python3 -m ExamGenerator.question_generator --task-domain Arxiv
python3 -m ExamGenerator.multi_choice_exam --task-domain Arxiv --question-date " question-date " --save-exam cd auto-rag-eval
rm -rf Data/SecFilings/KnowledgeCorpus/main/ *
python3 -m Data.SecFilings.preprocessor
python3 -m ExamGenerator.question_generator --task-domain SecFilings
python3 -m ExamGenerator.multi_choice_exam --task-domain SecFilings --question-date " question-date " --save-exam cd src/llm_automated_exam_evaluation/Data/
mkdir MyOwnTask
mkdir MyOwnTask/KnowledgeCorpus
mkdir MyOwnTask/KnowledgeCorpus/main
mkdir MyOwnTask/RetrievalIndex
mkdir MyOwnTask/RetrievalIndex/main
mkdir MyOwnTask/ExamData
mkdir MyOwnTask/RawExamData Stockez dans MyOwnTask/KnowledgeCorpus/main un fichier json , contenant une liste de documentation, chacune avec le format ci-dessous. Voir DevOps/html_parser.py , DevOps/preprocessor.py ou StackExchange/preprocessor.py pour quelques exemples.
{ ' source ' : ' my_own_source ' ,
' docs_id ' : ' Doc1022 ' ,
' title ' : ' Dev Desktop Set Up ' ,
' section ' : ' How to [...] ' ,
' text ' : " Documentation Text, should be long enough to make informative questions but shorter enough to fit into context " ,
' start_character ' : ' N/A ' ,
' end_character ' : ' N/A ' ,
' date ' : ' N/A ' ,
} Générez d’abord l’examen brut et l’index de récupération. Notez que vous devrez peut-être ajouter la prise en charge de votre propre LLM, plus d'informations ci-dessous. Vous souhaiterez peut-être modifier l'invite utilisée pour la génération de l'examen dans la classe LLMExamGenerator dans ExamGenerator/question_generator.py .
python3 -m ExamGenerator.question_generator --task-domain MyOwnTaskUne fois cela fait (cela peut prendre quelques heures selon la taille de la documentation), générez l'examen traité. Pour ce faire, vérifiez MyRawExamDate dans RawExamData (par exemple 2023091223) et exécutez :
python3 -m ExamGenerator.multi_choice_exam --task-domain MyOwnTask --question-date MyRawExamDate --save-exam Nous prenons actuellement en charge les points de terminaison pour Bedrock (Claude) dans le fichier LLMServer . La seule chose nécessaire pour apporter la vôtre est une classe, avec une fonction inference qui prend une invite en entrée et en sortie à la fois l'invite et le texte complété. Modifiez la classe LLMExamGenerator dans ExamGenerator/question_generator.py pour l'incorporer. Différents LLM génèrent différents types de questions. Par conséquent, vous souhaiterez peut-être modifier l'analyse brute de l'examen dans ExamGenerator/multi_choice_questions.py . Vous pouvez expérimenter en utilisant le notebook failed_questions.ipynb de ExamGenerator .
Nous exploitons le package lm-harness pour évaluer le système (LLM&Retrieval) sur l'examen généré. Pour ce faire, suivez les étapes suivantes :
Créez un dossier de référence pour votre tâche, ici DevOpsExam , voir ExamEvaluator/DevOpsExam pour le modèle. Il contient un fichier de code preprocess_exam,py pour les modèles d'invite et, plus important encore, un ensemble de tâches pour évaluer les modèles sur :
DevOpsExam contient les tâches associées à ClosedBook (pas de récupération) et OpenBook (Oracle Retrieval).DevOpsRagExam contient les tâches associées aux variantes de Retrieval (DPR/Embeddings/BM25...). Le script task_evaluation.sh fourni illustre l'évaluation de Llamav2:Chat:13B et Llamav2:Chat:70B sur la tâche, en utilisant In-Context-Learning (ICL) avec respectivement 0, 1 et 2 échantillons.
Pour citer cet ouvrage, veuillez utiliser
@misc{autorageval2024,
title={Automated Evaluation of Retrieval-Augmented Language Models with Task-Specific Exam Generation},
author={Gauthier Guinet and Behrooz Omidvar-Tehrani and Anoop Deoras and Laurent Callot},
year={2024},
eprint={2405.13622},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Voir CONTRIBUTION pour plus d'informations.
Ce projet est sous licence Apache-2.0.


