clearml fractional gpu
1.0.0
? Leave a star to support the project! ?
Le partage de GPU haut de gamme ou même de GPU grand public et grand public entre plusieurs utilisateurs est le moyen le plus rentable d'accélérer le développement de l'IA. Malheureusement, jusqu'à présent la seule solution existante s'appliquait aux GPU haut de gamme MIG/Slicing (A100+) et nécessitait Kubernetes,
? Bienvenue dans le GPU fractionnaire basé sur des conteneurs pour n'importe quelle carte Nvidia ! ?
Nous présentons des conteneurs pré-emballés prenant en charge CUDA 11.x et CUDA 12.x avec une limitation de mémoire dure prédéfinie ! Cela signifie que plusieurs conteneurs peuvent être lancés sur le même GPU, garantissant qu'un utilisateur ne peut pas allouer la totalité de la mémoire du GPU hôte ! (Plus de processus gourmands récupérant toute la mémoire du GPU ! Enfin, nous avons une option de limitation stricte de la mémoire au niveau du pilote).
ClearML propose plusieurs options pour optimiser l'utilisation des ressources GPU en partitionnant les GPU :
Grâce à ces options, ClearML permet d'exécuter des charges de travail d'IA avec une utilisation matérielle et des performances de charge de travail optimisées. Ce référentiel couvre les GPU fractionnaires basés sur des conteneurs. Pour plus d'informations sur les offres GPU fractionnaires de ClearML, consultez la documentation ClearML.
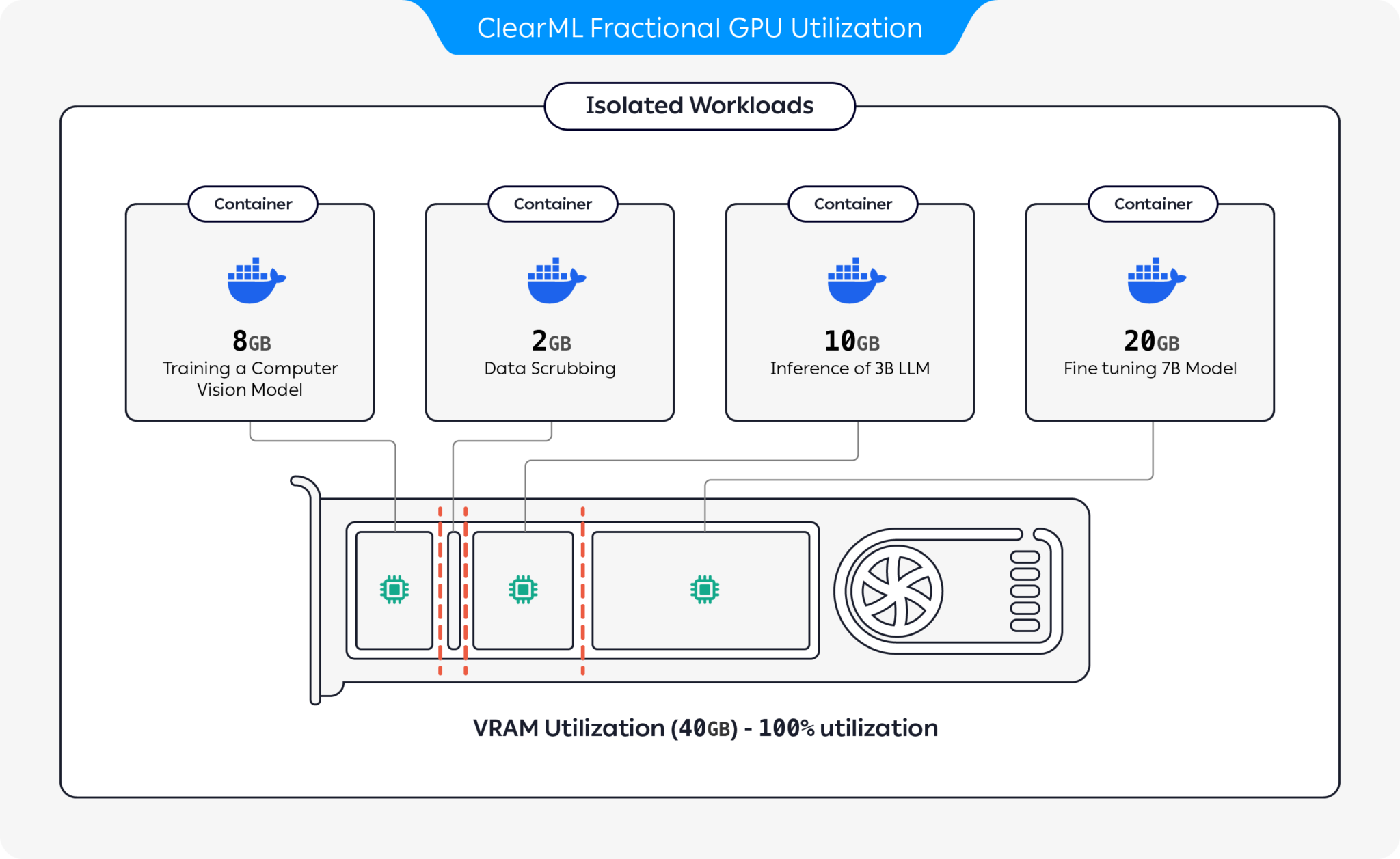
Choisissez le conteneur qui vous convient et lancez-le :
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bashPour vérifier que la limite de mémoire GPU fonctionne correctement, exécutez à l'intérieur du conteneur :
nvidia-smiVoici un exemple de sortie du GPU A100 :
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A |
| 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
| Limite de mémoire | Version CUDA | Version Ubuntu | Image Docker |
|---|---|---|---|
| 12 Gio | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-12gb |
| 12 Gio | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-12gb |
| 12 Gio | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-12gb |
| 12 Gio | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-12gb |
| 8 Gio | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-8gb |
| 8 Gio | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-8gb |
| 8 Gio | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-8gb |
| 8 Gio | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-8gb |
| 4 Gio | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-4gb |
| 4 Gio | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-4gb |
| 4 Gio | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-4gb |
| 4 Gio | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-4gb |
| 2 Gio | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-2gb |
| 2 Gio | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-2gb |
| 2 Gio | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-2gb |
| 2 Gio | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-2gb |
Important
Vous devez exécuter le conteneur avec --pid=host !
Note
--pid=host est requis pour permettre au pilote de faire la différence entre les processus du conteneur et les autres processus hôtes lors de la limitation de l'utilisation de la mémoire/de l'utilisation
Conseil
Les utilisateurs de ClearML-Agent ajoutent [--pid=host] à votre section agent.extra_docker_arguments dans votre fichier de configuration
Créez vos propres conteneurs et héritez des conteneurs d'origine.
Vous pouvez trouver quelques exemples ici.
Les conteneurs GPU fractionnaires peuvent être utilisés sur des exécutions nues ainsi que sur les POD Kubernetes. Oui! En utilisant l'un des conteneurs GPU fractionnaires, vous pouvez limiter la consommation de mémoire de votre Job/Pod et partager facilement des GPU sans craindre qu'ils ne se crashent mutuellement !
Voici un modèle POD Kubernetes simple :
apiVersion : v1
kind : Pod
metadata :
name : train-pod
labels :
app : trainme
spec :
hostPID : true
containers :
- name : train-container
image : clearml/fractional-gpu:u22-cu12.3-8gb
command : ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")'] Important
Vous devez exécuter le pod avec hostPID: true !
Note
hostPID: true est requis pour permettre au pilote de faire la différence entre les processus du pod et les autres processus hôtes lors de la limitation de l'utilisation de la mémoire/de l'utilisation.
Les conteneurs prennent en charge les pilotes Nvidia <= 545.xx . Nous continuerons à mettre à jour et à prendre en charge les nouveaux pilotes au fur et à mesure de leur publication.
GPU pris en charge : RTX séries 10, 20, 30, 40, série A et Data-Center P100, A100, A10/A40, L40/s, H100
Limitations : Les machines hôtes Windows ne sont actuellement pas prises en charge. Si cela est important pour vous, laissez une demande dans la section Problèmes
Q : L'exécution nvidia-smi à l'intérieur du conteneur signalera-t-elle la consommation du GPU des processus locaux ?
R : Oui, nvidia-smi communique directement avec les pilotes de bas niveau et signale à la fois la mémoire GPU précise du conteneur ainsi que la limitation de la mémoire locale du conteneur.
Notez que l'utilisation du GPU sera l'utilisation globale (c'est-à-dire côté hôte) du GPU et non l'utilisation spécifique du GPU du conteneur local.
Q : Comment puis-je m'assurer que mes Python / Pytorch / Tensorflow sont réellement limités en mémoire ?
R : Pour PyTorch, vous pouvez exécuter :
import torch
print ( f'Free GPU Memory: (free, global) { torch . cuda . mem_get_info () } ' )Exemple de Numba :
from numba import cuda
print ( f'Free GPU Memory: { cuda . current_context (). get_memory_info () } ' ) Q : La limitation peut-elle être brisée par un utilisateur ?
R : Nous sommes sûrs qu'un utilisateur malveillant trouvera un moyen. Nous n’avons jamais eu l’intention de nous protéger contre les utilisateurs malveillants.
Si vous avez un utilisateur malveillant ayant accès à vos machines, les GPU fractionnés ne sont pas votre problème numéro 1 ?
Q : Comment puis-je détecter par programme la limitation de mémoire ?
R : Vous pouvez vérifier la variable d'environnement du système d'exploitation GPU_MEM_LIMIT_GB .
Notez que le modifier ne supprimera ni ne réduira la limitation.
Q : L'exécution du conteneur avec --pid=host est-elle sécurisée ?
R : Il doit être à la fois sécurisé et sécurisé. Du point de vue de la sécurité, le principal inconvénient est qu'un processus conteneur peut voir n'importe quelle ligne de commande exécutée sur le système hôte. Si une ligne de commande de processus contient un « secret », alors oui, cela pourrait devenir une fuite potentielle de données. Notez que transmettre des « secrets » dans la ligne de commande est déconseillé et nous ne considérons donc pas cela comme un risque pour la sécurité. Cela dit, si la sécurité est la clé, l'édition entreprise (voir ci-dessous) élimine le besoin de fonctionner avec pid-host et est donc entièrement sécurisée.
Q : Pouvez-vous exécuter le conteneur sans --pid=host ?
R : Vous pouvez ! Mais vous devrez utiliser la version entreprise du conteneur clearml-fractional-gpu (sinon la limite de mémoire est appliquée à l'échelle du système plutôt qu'à l'échelle du conteneur). Si cette fonctionnalité est importante pour vous, veuillez contacter les ventes et l'assistance ClearML.
La licence d'utilisation de ClearML est accordée uniquement à des fins de recherche ou de développement. ClearML peut être utilisé à des fins éducatives, personnelles ou commerciales internes.
Une licence commerciale étendue pour une utilisation dans un produit ou un service est disponible dans le cadre de la solution ClearML Scale ou Enterprise.
ClearML propose une licence d'entreprise et commerciale ajoutant de nombreuses fonctionnalités supplémentaires en plus des GPU fractionnaires, notamment l'orchestration, les files d'attente prioritaires, la gestion des quotas, le tableau de bord du cluster de calcul, la gestion des ensembles de données et la gestion des expériences, ainsi que la sécurité et le support de niveau entreprise. Apprenez-en davantage sur ClearML Orchestration ou contactez-nous directement au service commercial ClearML.
Parlez-en à tout le monde ! #ClearMLFractionalGPU
Rejoignez notre chaîne Slack
Dites-nous quand quelque chose ne fonctionne pas et aidez-nous à le déboguer sur la page des problèmes.
Ce produit vous est présenté par l'équipe ClearML avec ❤️


