amazon bedrock rag
1.0.0
La génération de récupération augmentée (RAG) est le processus d'optimisation de la sortie d'un grand modèle de langage. Elle fait donc référence à une base de connaissances faisant autorité en dehors de ses sources de données de formation avant de générer une réponse. Les grands modèles linguistiques (LLM) sont formés sur de vastes volumes de données et utilisent des milliards de paramètres pour générer un résultat original pour des tâches telles que répondre à des questions, traduire des langues et compléter des phrases. RAG étend les capacités déjà puissantes des LLM à des domaines spécifiques ou à la base de connaissances interne d'une organisation, le tout sans qu'il soit nécessaire de recycler le modèle. Il s'agit d'une approche rentable pour améliorer les résultats du LLM afin qu'ils restent pertinents, précis et utiles dans divers contextes. Apprenez-en davantage sur RAG ici.
Amazon Bedrock est un service entièrement géré qui offre un choix de modèles de base (FM) hautes performances provenant de grandes sociétés d'IA telles que AI21 Labs, Anthropic, Cohere, Meta, Stability AI et Amazon via une seule API, ainsi qu'un large ensemble de capacités dont vous avez besoin pour créer des applications d’IA générative avec sécurité, confidentialité et IA responsable. Grâce à Amazon Bedrock, vous pouvez facilement expérimenter et évaluer les meilleurs FM pour votre cas d'utilisation, les personnaliser en privé avec vos données à l'aide de techniques telles que le réglage fin et le RAG, et créer des agents qui exécutent des tâches à l'aide des systèmes et des sources de données de votre entreprise. Étant donné qu'Amazon Bedrock est sans serveur, vous n'avez à gérer aucune infrastructure et vous pouvez intégrer et déployer en toute sécurité des fonctionnalités d'IA générative dans vos applications à l'aide des services AWS que vous connaissez déjà.
Les bases de connaissances pour Amazon Bedrock sont une fonctionnalité entièrement gérée qui vous aide à mettre en œuvre l'intégralité du flux de travail RAG, de l'ingestion à la récupération et à l'augmentation rapide, sans avoir à créer des intégrations personnalisées aux sources de données et à gérer les flux de données. La gestion du contexte de session est intégrée, de sorte que votre application peut facilement prendre en charge les conversations à plusieurs tours.
Dans le cadre de la création d'une base de connaissances, vous configurez une source de données et un magasin de vecteurs de votre choix. Un connecteur de source de données vous permet de connecter vos données propriétaires à une base de connaissances. Une fois que vous avez configuré un connecteur de source de données, vous pouvez synchroniser ou maintenir vos données à jour avec votre base de connaissances et rendre vos données disponibles pour les requêtes. Amazon Bedrock divise d'abord vos documents ou votre contenu en morceaux gérables pour une récupération efficace des données. Les morceaux sont ensuite convertis en intégrations et écrits dans un index vectoriel (représentation vectorielle des données), tout en conservant un mappage avec le document d'origine. Les intégrations vectorielles permettent de comparer mathématiquement les textes en termes de similarité.
Ce projet est mis en œuvre avec deux sources de données ; une source de données pour les documents stockés dans Amazon S3 et une autre source de données pour le contenu publié sur un site Web. Une collection de recherche vectorielle est créée dans Amazon OpenSearch Serverless pour le stockage vectoriel.
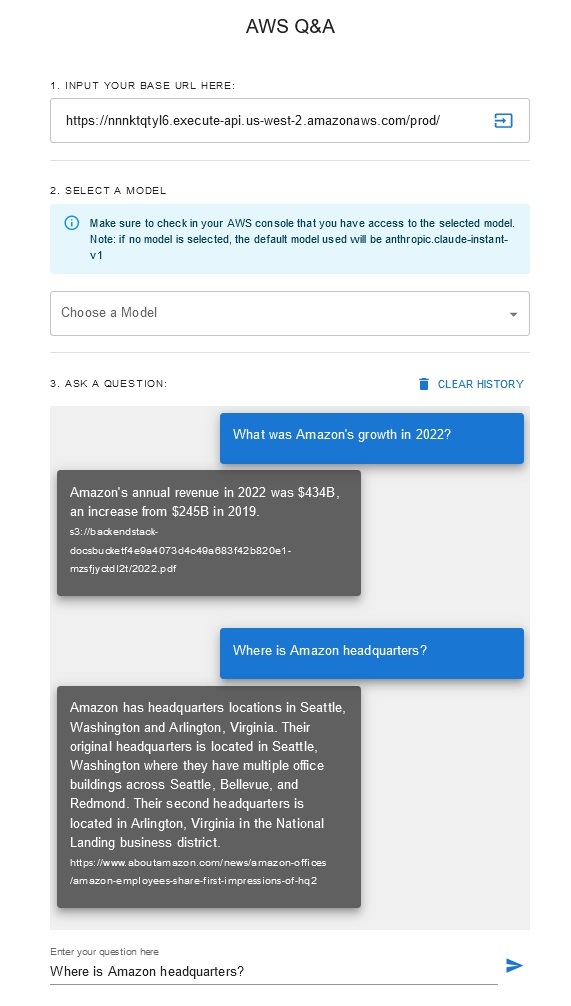
Chatbot questions-réponses 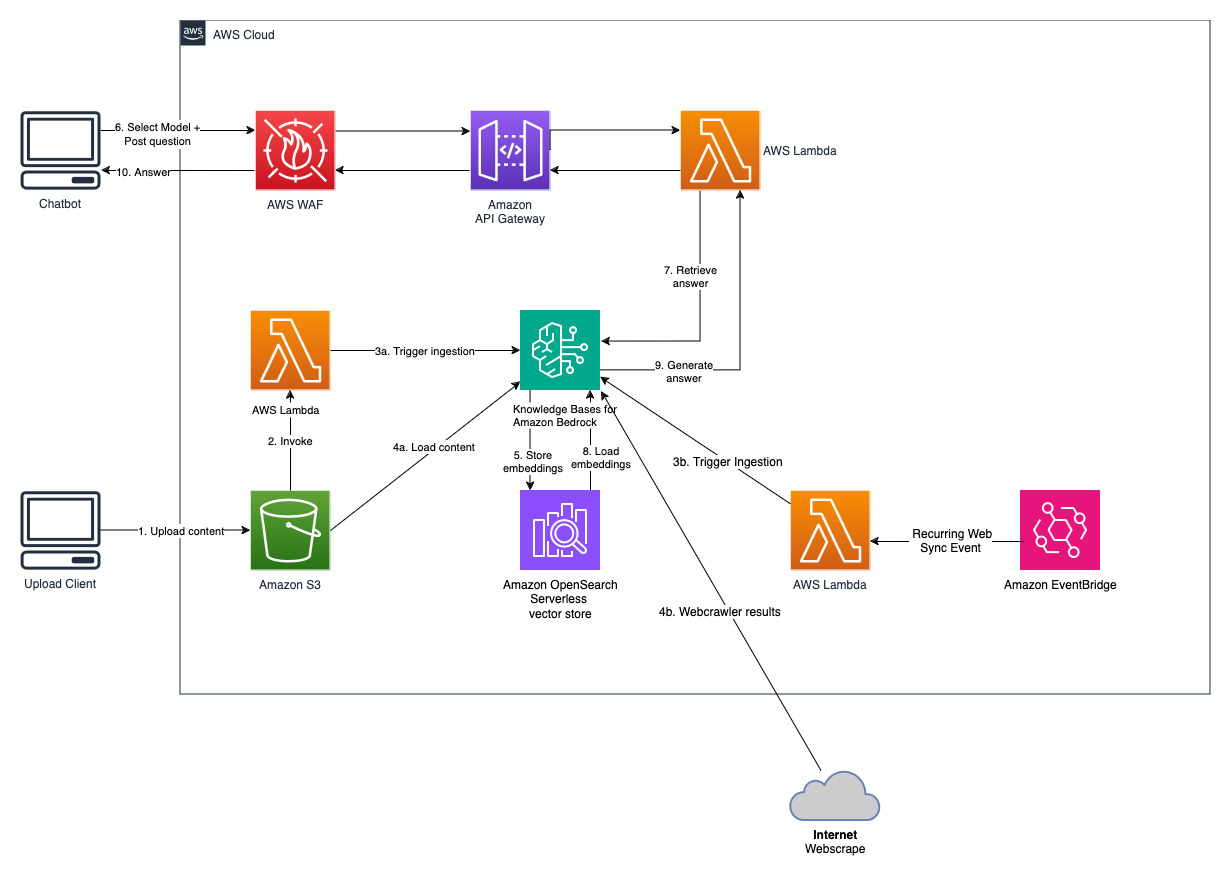
Ajouter de nouveaux sites Web pour la source de données Web 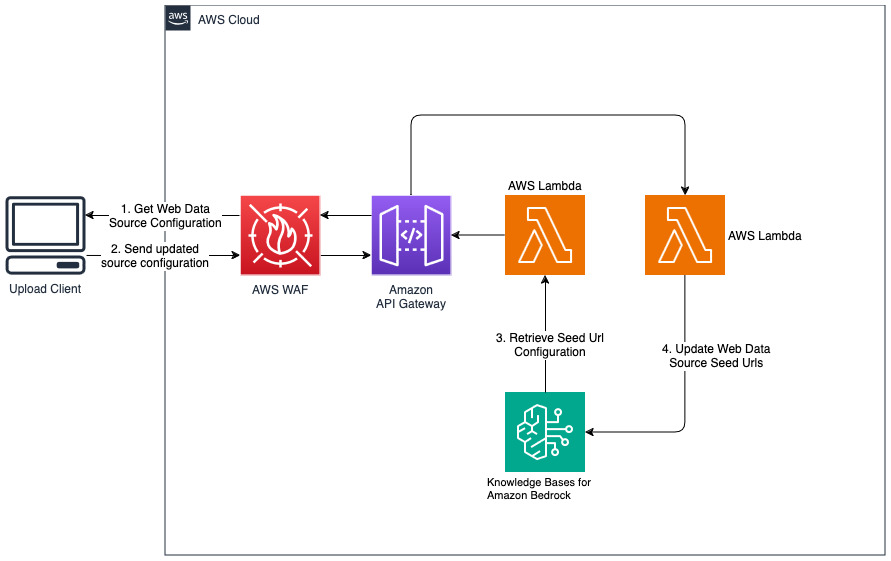
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
Fournissez une adresse IP client autorisée à accéder à API Gateway au format CIDR dans le cadre de la variable contextuelle «allowedip».
Une fois le déploiement terminé,
Cette solution permet aux utilisateurs de sélectionner le modèle fondamental qu'ils souhaitent utiliser pendant la phase de récupération et de génération. Le modèle par défaut est Anthropic Claude Instant . Pour le modèle d'intégration de la base de connaissances, cette solution utilise Amazon Titan Embeddings G1 - Modèle texte . Assurez-vous d’avoir accès à ces modèles de fondation.
Obtenez un rapport annuel récent d'Amazon accessible au public et copiez-le dans le nom du compartiment S3 indiqué précédemment. Pour un test rapide, vous pouvez copier le rapport annuel 2022 d'Amazon à l'aide de la console AWS S3. Le contenu du compartiment S3 sera automatiquement synchronisé avec la base de connaissances car le déploiement de la solution surveille le nouveau contenu dans le compartiment S3 et déclenche un workflow d'ingestion.
La solution déployée initialise la source de données web appelée « WebCrawlerDataSource » avec l'url https://www.aboutamazon.com/news/amazon-offices . Vous devez synchroniser manuellement cette source de données Web Crawler avec la base de connaissances de la console AWS pour effectuer une recherche sur le contenu du site Web, car l'ingestion du site Web est prévue dans le futur. Sélectionnez cette source de données dans la console Knowledge basée sur Amazon Bedrock et lancez une opération de « Sync ». Consultez Synchroniser votre source de données avec votre base de connaissances Amazon Bedrock pour plus de détails. Notez que le contenu du site Web ne sera disponible pour le chatbot Q&A qu'une fois la synchronisation terminée. Veuillez utiliser ces conseils lors de la configuration de sites Web en tant que source de données.
Utilisez « cdk destroy » pour supprimer la pile de ressources cloud créée dans ce déploiement de solution.


