EasyNLU
1.0.0
EasyNLU est une bibliothèque Natural Language Understanding (NLU) écrite en Java pour les applications mobiles. Étant basé sur la grammaire, il convient parfaitement aux domaines restreints mais nécessitant un contrôle strict.
Le projet dispose d'un exemple d'application Android qui peut planifier des rappels à partir d'une saisie en langage naturel :
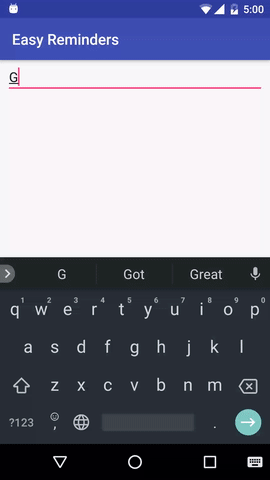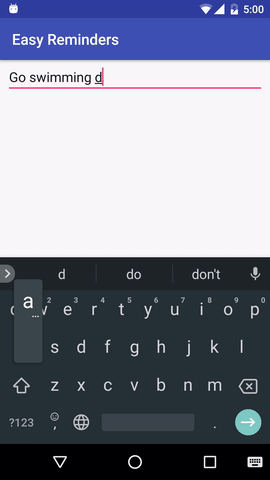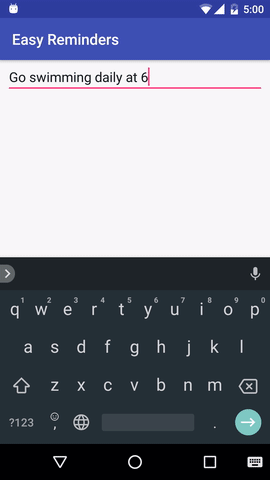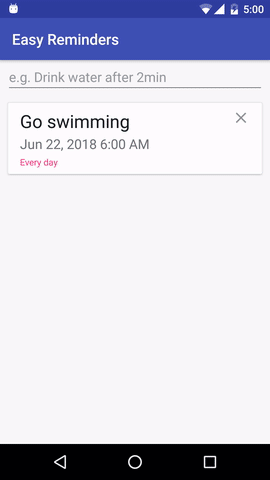
EasyNLU est sous licence Apache 2.0.
À la base, EasyNLU est un analyseur sémantique basé sur CCG. Une bonne introduction à l’analyse sémantique peut être trouvée ici. Un analyseur sémantique peut analyser une entrée comme :
Va chez le dentiste demain à 17h
sous une forme structurée :
{task: "Go to the dentist", startTime:{offset:{day:1}, hour:5, shift:"pm"}}
EasyNLU fournit la forme structurée sous forme de carte Java récursive. Cette forme structurée peut ensuite être résolue en un objet spécifique à une tâche qui est « exécuté ». Par exemple, dans l'exemple de projet, le formulaire structuré est résolu en un objet Reminder qui comporte des champs tels que task , startTime et repeat et est utilisé pour configurer une alarme avec le service AlarmManager.
En général, voici les étapes générales pour configurer la fonctionnalité NLU :
Avant d'écrire des règles, nous devons définir la portée de la tâche et les paramètres du formulaire structuré. À titre d'exemple de jouet, disons que notre tâche consiste à activer et désactiver les fonctionnalités du téléphone telles que Bluetooh, Wifi et GPS. Les champs sont donc :
Un exemple de formulaire structuré serait :
{feature: "bluetooth", action: "enable" }
Il est également utile d'avoir quelques exemples d'entrées pour comprendre les variations :
En poursuivant l'exemple du jouet, nous pouvons dire qu'au niveau supérieur nous avons une action de réglage qui doit avoir une fonctionnalité et une action. Nous utilisons ensuite des règles pour capturer ces informations :
Rule r1 = new Rule ( "$Setting" , "$Feature $Action" );
Rule r2 = new Rule ( "$Setting" , "$Action $Feature" ); Une règle contient au minimum un LHS et un RHS. Par convention, nous ajoutons un « $ » à un mot pour indiquer une catégorie. Une catégorie représente une collection de mots ou d'autres catégories. Dans les règles ci-dessus, $Feature représente des mots comme bluetooth, bt, wifi, etc. que nous capturons à l'aide de règles « lexicales » :
List < Rule > lexicals = Arrays . asList (
new Rule ( "$Feature" , "bluetooth" ),
new Rule ( "$Feature" , "bt" ),
new Rule ( "$Feature" , "wifi" ),
new Rule ( "$Feature" , "gps" ),
new Rule ( "$Feature" , "location" ),
); Pour normaliser les variations dans les noms de fonctionnalités, nous structurons $Features en sous-fonctionnalités :
List < Rule > featureRules = Arrays . asList (
new Rule ( "$Feature" , "$Bluetooth" ),
new Rule ( "$Feature" , "$Wifi" ),
new Rule ( "$Feature" , "$Gps" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" )
); De même pour $Action :
List < Rule > actionRules = Arrays . asList (
new Rule ( "$Action" , "$EnableDisable" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" ),
new Rule ( "$EnableDisable" , "$Enable" ),
new Rule ( "$EnableDisable" , "$Disable" ),
new Rule ( "$OnOff" , "on" ),
new Rule ( "$OnOff" , "off" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
); Notez le « ? » dans la troisième règle ; cela signifie que la catégorie $Switch est facultative. Pour déterminer si une analyse réussit, l'analyseur recherche une catégorie spéciale appelée catégorie racine. Par convention, il est noté $ROOT . Nous devons ajouter une règle pour accéder à cette catégorie :
Rule root = new Rule ( "$ROOT" , "$Setting" );Avec cet ensemble de règles, notre analyseur devrait être capable d'analyser les exemples ci-dessus, en les convertissant en ce qu'on appelle des arbres syntaxiques.
L'analyse syntaxique ne sert à rien si nous ne pouvons pas extraire le sens de la phrase. Ce sens est capté par la forme structurée (Forme logique dans le jargon de la PNL). Dans EasyNLU, nous passons un troisième paramètre dans la définition de la règle pour définir comment la sémantique sera extraite. Nous utilisons la syntaxe JSON avec des marqueurs spéciaux pour faire ceci :
new Rule ( "$Action" , "$EnableDisable" , "{action:@first}" ), @first indique à l'analyseur de choisir la valeur de la première catégorie de la règle RHS. Dans ce cas, il s'agira soit de « activer » soit de « désactiver » en fonction de la phrase. D'autres marqueurs incluent :
@identity : fonction d'identité@last : Choisissez la valeur de la dernière catégorie RHS@N : Choisissez la valeur de la N ème catégorie RHS, par exemple @3 choisira la 3ème@merge : Fusionne les valeurs de toutes les catégories. Seules les valeurs nommées (par exemple {action: enable} ) seront fusionnées@append : Ajoutez les valeurs de toutes les catégories dans une liste. La liste résultante doit être nommée. Seules les valeurs nommées sont autoriséesAprès avoir ajouté des marqueurs sémantiques, nos règles deviennent :
List < Rule > rules = Arrays . asList (
new Rule ( "$ROOT" , "$Setting" , "@identity" ),
new Rule ( "$Setting" , "$Feature $Action" , "@merge" ),
new Rule ( "$Setting" , "$Action $Feature" , "@merge" ),
new Rule ( "$Feature" , "$Bluetooth" , "{feature: bluetooth}" ),
new Rule ( "$Feature" , "$Wifi" , "{feature: wifi}" ),
new Rule ( "$Feature" , "$Gps" , "{feature: gps}" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" ),
new Rule ( "$Action" , "$EnableDisable" , "{action: @first}" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" , "@last" ),
new Rule ( "$EnableDisable" , "$Enable" , "enable" ),
new Rule ( "$EnableDisable" , "$Disable" , "disable" ),
new Rule ( "$OnOff" , "on" , "enable" ),
new Rule ( "$OnOff" , "off" , "disable" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
);Si le paramètre sémantique n'est pas fourni, l'analyseur créera une valeur par défaut égale au RHS.
Pour exécuter l'analyseur, clonez ce référentiel et importez le module d'analyseur dans votre projet Android Studio/IntelliJ. L'analyseur EasyNLU prend un objet Grammar qui contient les règles, un objet Tokenizer pour convertir la phrase saisie en mots et une liste facultative d'objets Annotator pour annoter des entités telles que des nombres, des dates, des lieux, etc. Exécutez le code suivant après avoir défini les règles :
Grammar grammar = new Grammar ( rules , "$ROOT" );
Parser parser = new Parser ( grammar , new BasicTokenizer (), Collections . emptyList ());
System . out . println ( parser . parse ( "kill bt" ));
System . out . println ( parser . parse ( "wifi on" ));
System . out . println ( parser . parse ( "enable location" ));
System . out . println ( parser . parse ( "turn off GPS" ));Vous devriez obtenir le résultat suivant :
23 rules
[{feature=bluetooth, action=disable}]
[{feature=wifi, action=enable}]
[{feature=gps, action=enable}]
[{feature=gps, action=disable}]
Essayez d'autres variantes. Si une analyse échoue pour un exemple de variante, vous n'obtiendrez aucune sortie. Vous pouvez ensuite ajouter ou modifier les règles et répéter le processus d'ingénierie grammaticale.
EasyNLU prend désormais en charge les listes sous forme structurée. Pour le domaine ci-dessus, il peut gérer des entrées telles que
Désactiver la localisation BT GPS
Ajoutez ces 3 règles supplémentaires à la grammaire ci-dessus :
new Rule("$Setting", "$Action $FeatureGroup", "@merge"),
new Rule("$FeatureGroup", "$Feature $Feature", "{featureGroup: @append}"),
new Rule("$FeatureGroup", "$FeatureGroup $Feature", "{featureGroup: @append}"),
Exécutez une nouvelle requête comme :
System.out.println(parser.parse("disable location bt gps"));
Vous devriez obtenir ce résultat :
[{action=disable, featureGroup=[{feature=gps}, {feature=bluetooth}, {feature=gps}]}]
Notez que ces règles ne sont déclenchées que s'il existe plusieurs fonctionnalités dans la requête.
Les annotateurs facilitent l'utilisation de types spécifiques de jetons qui seraient autrement encombrants ou carrément impossibles à gérer via des règles. Par exemple, prenez la classe NumberAnnotator . Il détectera et annotera tous les nombres sous la forme $NUMBER . Vous pouvez alors référencer directement la catégorie dans vos règles, par exemple :
Rule r = new Rule("$Conversion", "$Convert $NUMBER $Unit $To $Unit", "{convertFrom: {unit: @2, quantity: @1}, convertTo: {unit: @last}}"
EasyNLU est actuellement livré avec quelques annotateurs :
NumberAnnotator : Annote les nombresDateTimeAnnotator : Annote certains formats de date. Fournit également ses propres règles que vous ajoutez à l'aide de DateTimeAnnotator.rules()TokenAnnotator : Annote chaque jeton de l'entrée en tant que $TOKENPhraseAnnotator : annote chaque phrase contiguë d'entrée sous la forme $PHRASE Pour utiliser votre propre annotateur personnalisé, implémentez l'interface Annotator et transmettez-la à l'analyseur. Référez-vous aux annotateurs intégrés pour avoir une idée de la manière d'en implémenter un.
EasyNLU prend en charge les règles de chargement à partir de fichiers texte. Chaque règle doit figurer sur une ligne distincte. Les LHS, RHS et la sémantique doivent être séparés par des tabulations :
$EnableDisable ?$Switch $OnOff @last
Attention à ne pas utiliser d'IDE qui convertissent automatiquement les tabulations en espaces
Au fur et à mesure que d'autres règles sont ajoutées à l'analyseur, vous constaterez que l'analyseur trouve plusieurs analyses pour certaines entrées. Cela est dû à l’ambiguïté générale des langues humaines. Pour déterminer la précision de l'analyseur pour votre tâche, vous devez l'exécuter à l'aide d'exemples étiquetés.
Comme les règles précédentes, EasyNLU prend des exemples définis en texte brut. Chaque ligne doit être un exemple distinct et doit contenir le texte brut et le formulaire structuré séparés par une tabulation :
take my medicine at 4pm {task:"take my medicine", startTime:{hour:4, shift:"pm"}}
Il est important que vous couvriez un nombre ou des variations acceptables dans la saisie. Vous obtiendrez plus de variété si vous demandez à différentes personnes d'effectuer cette tâche. Le nombre d'exemples dépend de la complexité du domaine. L'exemple d'ensemble de données fourni dans ce projet contient plus de 100 exemples.
Une fois que vous avez les données, vous pouvez les intégrer dans un ensemble de données. La partie apprentissage est gérée par le module trainer ; importez-le dans votre projet. Chargez un ensemble de données comme celui-ci :
Dataset dataset = Dataset . fromText ( 'filename.txt' )Nous évaluons l'analyseur pour déterminer deux types de précisions
Pour exécuter l'évaluation, nous utilisons la classe Model :
Model model = new Model(parser);
model.evaluate(dataset, 2);
Le deuxième paramètre de la fonction d'évaluation est le niveau détaillé. Plus le nombre est élevé, plus la sortie est détaillée. La fonction evaluate() exécute l'analyseur sur chaque exemple et affiche les analyses incorrectes, affichant enfin la précision. Si vous obtenez les deux précisions dans les années 90, alors la formation n'est pas nécessaire, vous pourriez probablement gérer ces quelques mauvaises analyses avec le post-traitement. Si la précision de l'oracle est élevée mais la précision des prédictions faible, la formation du système sera utile. Si la précision d'Oracle est elle-même faible, vous devez faire davantage d'ingénierie grammaticale.
Pour obtenir l'analyse correcte, nous les notons et choisissons celui avec le score le plus élevé. EasyNLU utilise un modèle linéaire simple pour calculer les scores. La formation est effectuée à l'aide de la descente de gradient stochastique (SGD) avec une fonction de perte de charnière. Les fonctionnalités d’entrée sont basées sur le nombre de règles et les champs du formulaire structuré. Les poids entraînés sont ensuite enregistrés dans un fichier texte.
Vous pouvez ajuster certains paramètres du modèle/entraînement pour obtenir une meilleure précision. Pour les modèles de rappels, les paramètres suivants ont été utilisés :
HParams hparams = HParams . hparams ()
. withLearnRate ( 0.08f )
. withL2Penalty ( 0.01f )
. set ( SVMOptimizer . CORRECT_PROB , 0.4f );Exécutez le code de formation comme suit :
Experiment experiment = new Experiment ( model , dataset , hparams , "yourdomain.weights" );
experiment . train ( 100 , false );Cela entraînera le modèle pendant 100 époques avec une répartition train-test de 0,8. Il affichera les précisions sur l'ensemble de test et enregistrera les poids du modèle dans le chemin de fichier fourni. Pour effectuer un entraînement sur l'intégralité de l'ensemble de données, définissez le paramètre de déploiement sur true. Vous pouvez exécuter un mode interactif en prenant des entrées depuis la console :
experiement.interactive();
REMARQUE : cette formation n'est pas garantie de produire une grande précision, même avec un grand nombre d'exemples. Pour certains scénarios, les fonctionnalités fournies peuvent ne pas être suffisamment discriminantes. Si vous êtes bloqué dans un tel cas, veuillez enregistrer un problème et nous pourrons trouver des fonctionnalités supplémentaires.
Les poids du modèle sont un fichier texte brut. Pour un projet Android, vous pouvez le placer dans le dossier assets et le charger à l'aide d'AssetManager. Veuillez consulter ReminderNlu.java pour plus de détails. Vous pouvez même stocker vos poids et vos règles dans le cloud et mettre à jour votre modèle sans fil (Firebase, ça vous tente ?).
Une fois que l'analyseur fait du bon travail en convertissant les entrées en langage naturel en une forme structurée, vous souhaiterez probablement ces données dans un objet spécifique à la tâche. Pour certains domaines comme l’exemple de jouet ci-dessus, cela peut être assez simple. Pour d'autres, vous devrez peut-être résoudre des références à des éléments tels que des dates, des lieux, des contacts, etc. Dans l'exemple de rappel, les dates sont souvent relatives (par exemple « demain », « après 2 heures », etc.) qui doivent être converties en valeurs absolues. Veuillez vous référer à ArgumentResolver.java pour voir comment la résolution est effectuée.
CONSEIL : conservez la logique de résolution au minimum lors de la définition des règles et effectuez l'essentiel de cette opération en post-traitement. Cela simplifiera les règles.


