inverted_index
1.0.0
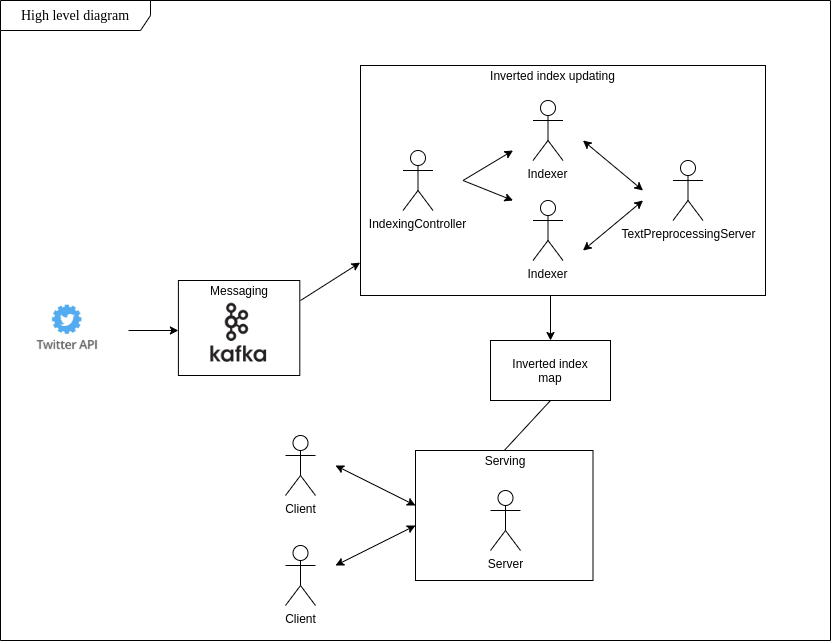
Rechercher des expressions que disent les gens autour peut être difficile. Qu’en est-il des mises à jour dynamiques de cet ensemble de données ? Stockage évolutif et faible latence ? Mon objectif principal dans ce projet est de construire un système qui répond à ces exigences et permet d'être au courant des tendances présentes dans les tweets en temps réel.
Suivant l'idée de l'index inversé, j'ai implémenté l'application qui trouve en temps réel les tweets avec un contenu spécifique, les stocke dans un système de fichiers local et permet d'effectuer une recherche par mot juste après l'initialisation de la connexion client.
Pour exécuter l'application, vous avez besoin de :
git clone https://github.com/cyberpunk317/inverted_index.git TWITTER_APP_KEY = 'YOUR APP KEY'
TWITTER_APP_SECRET = 'YOUR APP SECRET'
TWITTER_KEY = 'YOUR KEY'
TWITTER_SECRET = 'YOUR SECRET' Créez des Dockerfiles pour le client et le serveur :
./gradlew clean build createClientDockerfile createMainDockerfile
Cela produira app_server.Dockerfile et app_client.Dockerfile dans le répertoire racine.
Démarrer l'application :
docker-compose up
Lancez une session client :
docker build -f app_client.Dockerfile -t client:latest . && docker run -it --rm --network=host client:latest bash
Commencez à taper des mots qui vous intéressent. Le serveur renverra l'emplacement des tweets au format 'dataset_v2//tweet_N.txt'. Par exemple:
You entered: war
Server response: [dataset_v2/Veeresh Dambal/tweet_30.txt, dataset_v2/pedro schliesser/tweet_1.txt]
Consultez les problèmes ouverts pour une liste des fonctionnalités proposées (et des problèmes connus).
Distribué sous licence MIT. Voir LICENSE pour plus d’informations.


