dstoolkit km solution accelerator
V1.6

Accélérateur de solutions Knowledge Mining
Ce référentiel contient tout le code permettant de déployer une solution de Knowledge Mining de bout en bout basée sur Azure Cognitive Search.
Il est construit sur les services Azure standards tels que les fonctions, les services d'application Web, les services Congitive et la recherche cognitive. Il fournit un pipeline de déploiement permettant une configuration rapide et facile de pipelines CI/CD pour vos projets.
Pour une documentation détaillée, veuillez vous référer à la section documentation du dépôt contenant le wiki de la solution.
Afin de réussir la configuration de votre solution, vous devrez avoir accès et/ou provisionner les éléments suivants :
Un rôle de propriétaire ou de contributeur est assumé sur l’abonnement Azure ou le groupe de ressources ciblé.
Veuillez vous référer au README pour déployer cet accélérateur de solution.
Les instructions fournies dans tous les guides supposent que vous possédez une connaissance pratique fondamentale du portail Azure, d’Azure Functions, de la recherche cognitive Azure, des fonctions, du stockage et d’Azure Cognitives Services.
Pour une formation et une assistance supplémentaires, veuillez consulter :
L'exploration de connaissances (KM) est une discipline émergente de l'intelligence artificielle (IA) qui utilise une combinaison de services intelligents pour apprendre rapidement à partir de grandes quantités d'informations. Il permet aux organisations de comprendre en profondeur et d’explorer facilement les informations, de découvrir des informations cachées et de trouver des relations et des modèles à grande échelle.
Exploration des connaissances dans Azure
Cet accélérateur de solutions KM vise à vous fournir une solution de Knowledge Mining de bout en bout fonctionnelle composée de :
Avec cet accélérateur basé sur le cloud, vous obtiendrez une solution de bout en bout avec les outils nécessaires pour déployer, étendre, exploiter et surveiller.
À cet égard, la solution prévoit
Cet accélérateur de solutions Knowledge Mining est inspiré d’un autre accélérateur Knowledge Mining Solution Accelerator.
Sur la base de notre expérience sur le terrain, nous avons développé des fonctionnalités/compétences pour relever les défis courants liés aux données non structurées en nous concentrant sur la convivialité et l'expérience d'exploration des données.
Vous trouverez ci-dessous une liste non exhaustive des principaux faits saillants :
Indexation des images intégrées
Normalisation des images :
Métadonnées
Conversion HTML
Extraction de tableaux : les informations tabulaires sont courantes dans les corpus de données non structurées. La solution extraira, indexera et projettera les tables dans une banque de connaissances dédiée (facultatif).
Traduction " : il y a deux fonctionnalités de traduction dans cette solution
Analyse de texte : extrayez les entités (nommées, liées) de n'importe quel document et texte d'image traité par OCR.
Exporter vers Excel : demande courante lors de l'exploration de données non structurées.
Interface utilisateur configurable : la création d'une interface utilisateur prend du temps, nous souhaitions apporter une grande configurabilité de l'interface utilisateur afin que vous puissiez donner vie à de nouvelles solutions de KM en temps opportun.
Cet esprit d’accélérateur de solutions s’inscrit dans un scénario de Content Research KM.
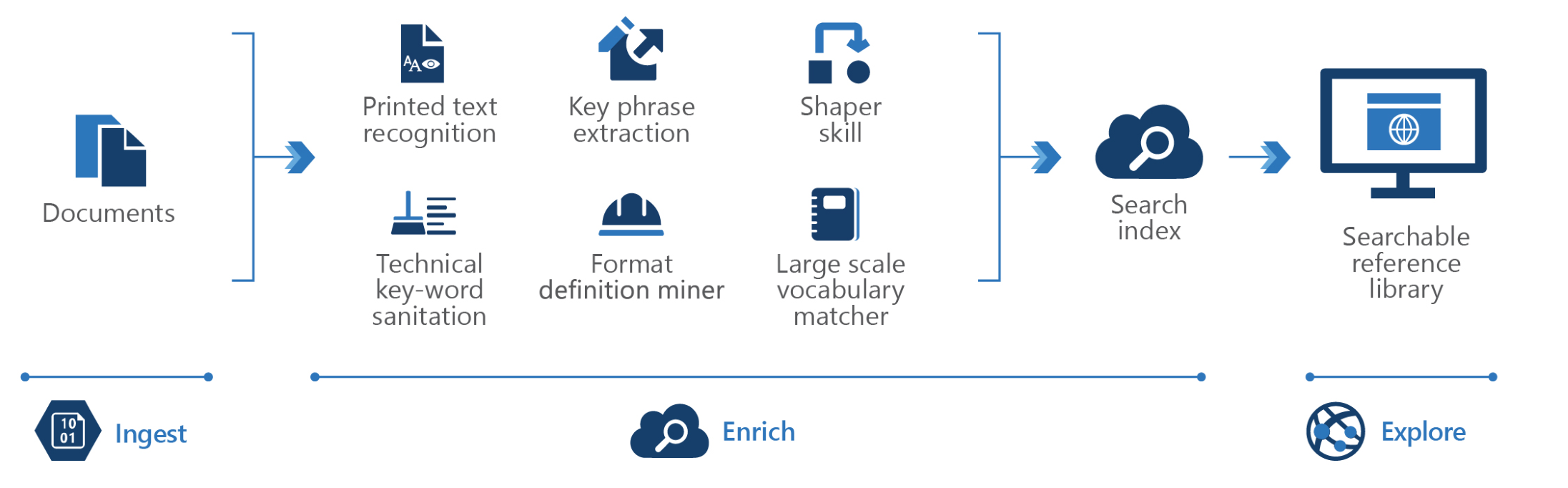
Néanmoins, puisque son architecture est ouverte, vous pouvez l’utiliser comme base pour des scénarios de KM plus spécialisés.
Cet accélérateur de solutions n'est destiné à aucun domaine, même si son extensibilité vous donnerait les outils nécessaires pour le rendre spécifique à un domaine.
Quelques cas d'utilisation inspirants
Vous pourriez envisager de produire un tel accélérateur pour votre organisation.
Cet accélérateur de solutions s'adresse à tous ceux qui ont besoin de
Cet accélérateur de solutions a également pour objectif de faciliter l’intégration des modules Data Science dans votre solution de Knowledge Mining.
L'équipe Data Science Toolkit a créé des accélérateurs pour votre charge de travail en science des données.
| Solution | Description |
|---|---|
| Polyvalence | Verseagility est une boîte à outils basée sur Python pour accélérer votre tâche personnalisée de traitement du langage naturel (NLP), vous permettant d'apporter vos propres données, d'utiliser vos frameworks préférés et de mettre des modèles en production. Il s'agit d'un composant central de Microsoft Data Science Toolkit. |
| Base MLOps | Ce référentiel contient la structure de référentiel de base pour les projets d'apprentissage automatique basés sur les technologies Azure (Azure ML et Azure DevOps). Les noms de dossiers et de fichiers sont choisis en fonction de votre expérience personnelle. Vous pouvez trouver les principes et les idées derrière la structure, que nous vous recommandons de suivre lors de la personnalisation de votre propre projet et de votre processus MLOps. Nous attendons également des utilisateurs qu’ils soient familiarisés avec les concepts d’apprentissage automatique Azure et comment utiliser la technologie. |
| MLOps pour DataBricks | Ce référentiel contient le cadre de développement Databricks pour la réalisation de tous les projets d'ingénierie de données et de projets d'apprentissage automatique basés sur les technologies Azure. |
| Accélérateur de solutions de classification | Ce référentiel contient la structure de référentiel de base permettant de fournir des solutions de classification pour les projets d'apprentissage automatique (ML) basées sur les technologies Azure (Azure ML et Azure DevOps). |
| Accélérateur de solution de détection d'objets | Ce référentiel contient tout le code pour la formation des modèles de détection d'objets TensorFlow dans Azure Machine Learning (AML) avec des configurations pour la formation sur le calcul Azure, la surveillance des expériences et le déploiement des points de terminaison en tant que service Web. Il est construit sur l'accélérateur MLOps et fournit des pipelines de formation et de déploiement de bout en bout permettant une configuration rapide et facile de pipelines CI/CD pour vos projets. |
Vous pouvez vous référer à la documentation de l'accélérateur de solutions comme suit :
| Sujet | Description | Lien vers la documentation |
|---|---|---|
| Pré-requis | De quoi avez-vous besoin pour déployer et exploiter la solution | LISEZMOI |
| Architecture | Comment la solution est architecturée | LISEZMOI |
| Déploiement | Comment déployer cet accélérateur de solution | LISEZMOI |
| Configuration | Tout ce qu'il faut savoir sur la configuration de l'accélérateur de solutions | LISEZMOI |
| Science des données | Intégration avec la science des données | LISEZMOI |
| Déploiement | Comment commencer par déployer la solution | LISEZMOI |
| Surveillance | Comment surveiller la solution | LISEZMOI |
| Recherche | Comment la recherche est configurée et gérée | LISEZMOI |
| Rechercher et explorer (interface utilisateur) | Interface utilisateur pour rechercher et explorer | LISEZMOI |
La structure du référentiel de cet accélérateur est la suivante
Clonez ou téléchargez ce référentiel, puis accédez au dossier Déploiement, en suivant les étapes décrites dans le guide de déploiement.
Une fois toutes les étapes terminées, vous disposerez d’une solution d’exploration de connaissances de bout en bout fonctionnelle qui combine l’ingestion de sources de données avec des compétences d’enrichissement des données et une application Web optimisée par Azure Cognitive Search.
Cette solution s'inspire du travail original du
Les principaux contributeurs à cet accélérateur de solutions sont
L’équipe de parrainage de la boîte à outils de science des données
Pour la grande conversation sur l'exploration de connaissances et les données non structurées
Ce projet accueille les contributions et suggestions. La plupart des contributions nécessitent que vous acceptiez un contrat de licence de contributeur (CLA) déclarant que vous avez le droit de nous accorder, et que vous nous accordez effectivement, le droit d'utiliser votre contribution. Pour plus de détails, visitez https://cla.opensource.microsoft.com.
Lorsque vous soumettez une pull request, un robot CLA déterminera automatiquement si vous devez fournir un CLA et décorera le PR de manière appropriée (par exemple, vérification du statut, commentaire). Suivez simplement les instructions fournies par le bot. Vous n’aurez besoin de le faire qu’une seule fois pour tous les dépôts utilisant notre CLA.
Ce projet a adopté le code de conduite Microsoft Open Source. Pour plus d’informations, consultez la FAQ sur le code de conduite ou contactez [email protected] pour toute question ou commentaire supplémentaire.
Ce projet peut contenir des marques ou des logos pour des projets, des produits ou des services. L'utilisation autorisée des marques ou logos Microsoft est soumise et doit respecter les directives relatives aux marques et aux marques de Microsoft. L'utilisation des marques ou logos Microsoft dans les versions modifiées de ce projet ne doit pas prêter à confusion ni impliquer le parrainage de Microsoft. Toute utilisation de marques ou de logos tiers est soumise aux politiques de ces tiers.


