donkeybot
1.0.0
Ce référentiel n'est pas maintenu et a été archivé.
Donkeybot est un système de réponse aux questions de bout en bout. Il utilise plusieurs sources de données, un tableau FAQ et des modèles linguistiques d'apprentissage par transfert comme BERT pour répondre aux questions d'assistance de Rucio.
L'objectif du projet GSoC 2020 est d'utiliser le traitement du langage naturel (NLP) pour développer un prototype de bot intelligent capable de fournir des réponses satisfaisantes aux utilisateurs de Rucio et de traiter les demandes d'assistance jusqu'à un certain niveau de complexité, en transmettant uniquement les autres au experts.
Donkeybot peut être étendu et appliqué comme système de questions-réponses pour vos besoins. Des modifications dans le code sont nécessaires pour utiliser Donkeybot pour votre cas d'utilisation et vos données spécifiques. La mise en œuvre actuelle s'applique aux sources de données spécifiques à Rucio.
Stockage de données : Un stockage de données contenant des données spécifiques au domaine Rucio. L'implémentation actuelle du module est dans SQLite pour le prototypage rapide qu'il fournit. Les sources de données incluent les e-mails d'assistance sécurisés et anonymes des utilisateurs de Rucio, les problèmes Rucio GitHub et la documentation Rucio.
Détection de questions : Un module de détection et d'extraction de questions à partir d'un texte donné. Ceci est utilisé pour extraire les questions passées des e-mails d'assistance et des problèmes GitHub en utilisant des expressions régulières. Ces questions sont archivées sous forme de documents et utilisées par les autres modules.
Récupération de documents : un module de moteur de recherche qui utilise l'algorithme BM25 pour récupérer les n documents les plus similaires (questions posées précédemment ou documentation Rucio) à utiliser comme contexte par le module de détection de réponses.
Answer Detection : Le module Answer Detection qui suit à la fois une approche d’apprentissage par transfert et une approche supervisée.
Les fonctionnalités supplémentaires incluent :
Interface graphique de création de FAQ : l'utilisateur peut utiliser une interface graphique fournie comme interface pour interagir avec le stockage de données, insérer des questions FAQ, réindexer le moteur de recherche et élargir la base de connaissances de Donkeybot.
Hachage de nom : un script qui utilise le tagger NER de Stanford pour détecter les informations privées des utilisateurs dans les e-mails d'assistance et les hacher. Ainsi, en suivant les directives de confidentialité du CERN et en gardant toutes les données anonymisées.
Consultez la documentation complète pour obtenir des exemples, des détails opérationnels et d’autres informations.
Voir FAQ : GSoC pour un calendrier détaillé, des informations sur les étudiants, les problèmes rencontrés, des suggestions d'amélioration future, une liste de lecture et plus encore.
Vous pouvez essayer de demander à Donkeybot vous-même !
Utiliser le slackbot :
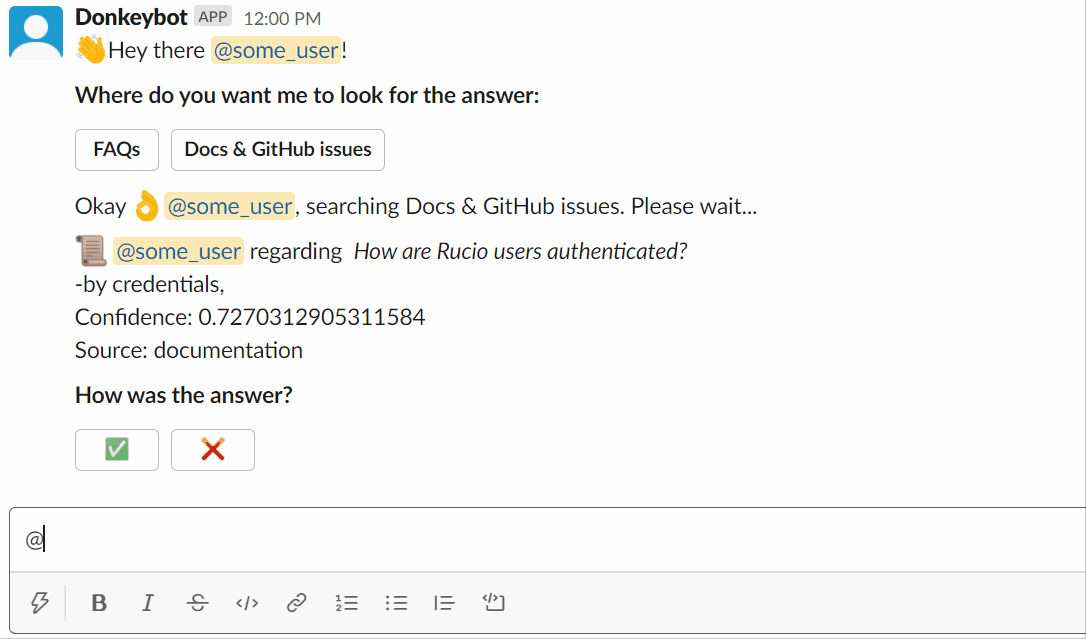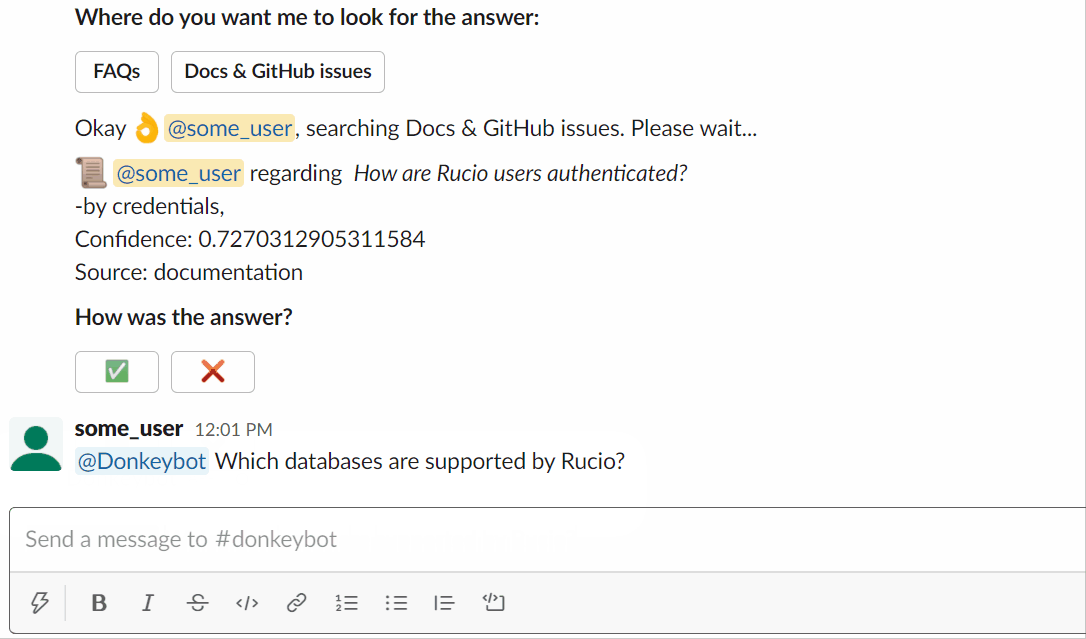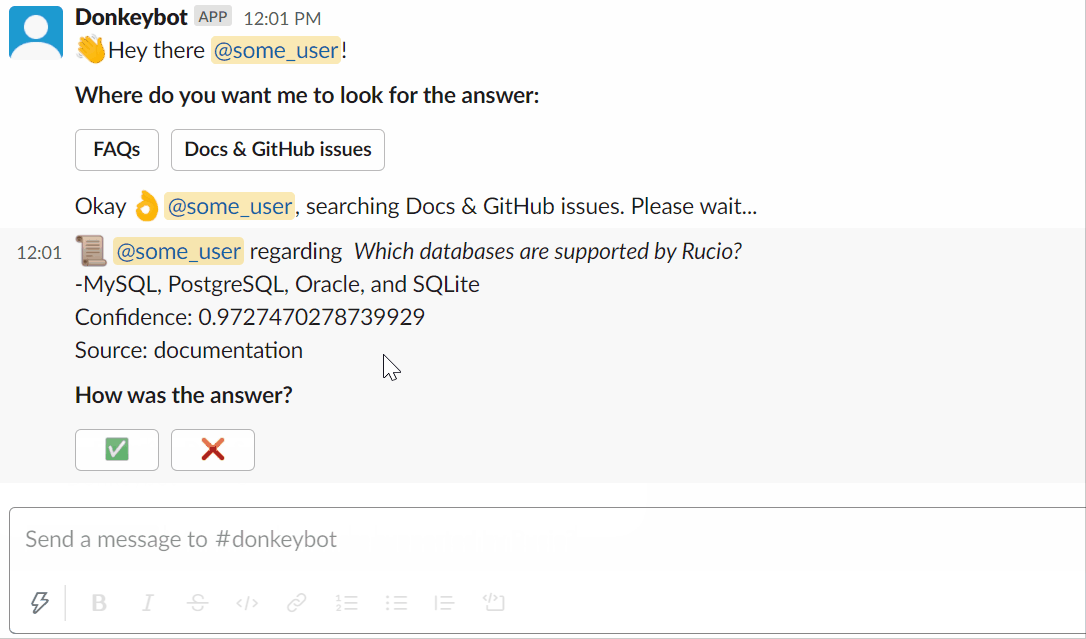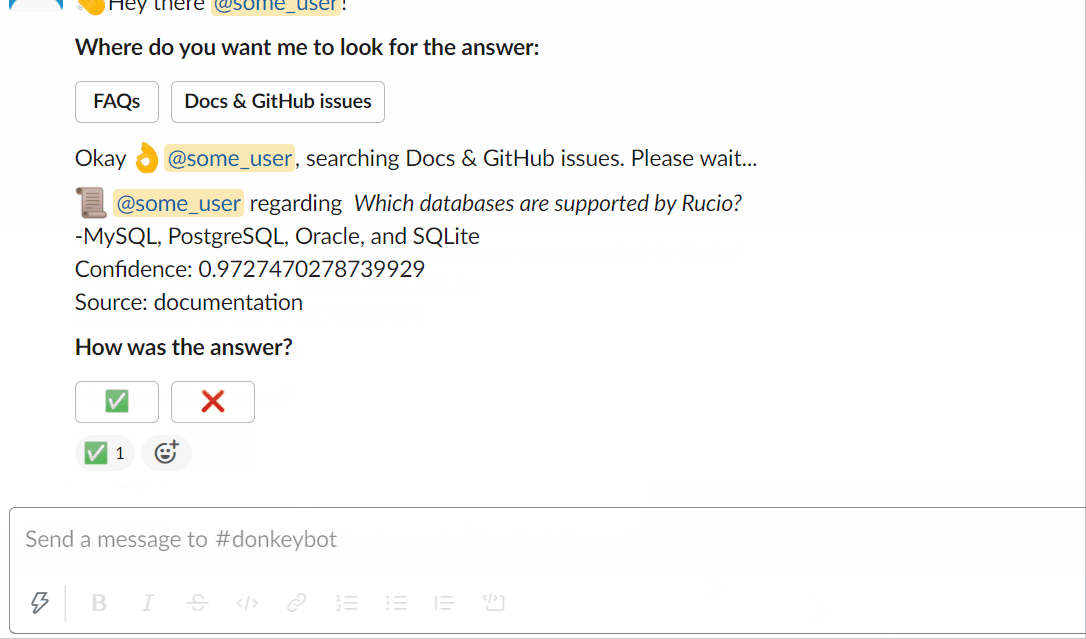
Ou vous pouvez utiliser la CLI :
$ python . s cripts a sk_donkeybot.py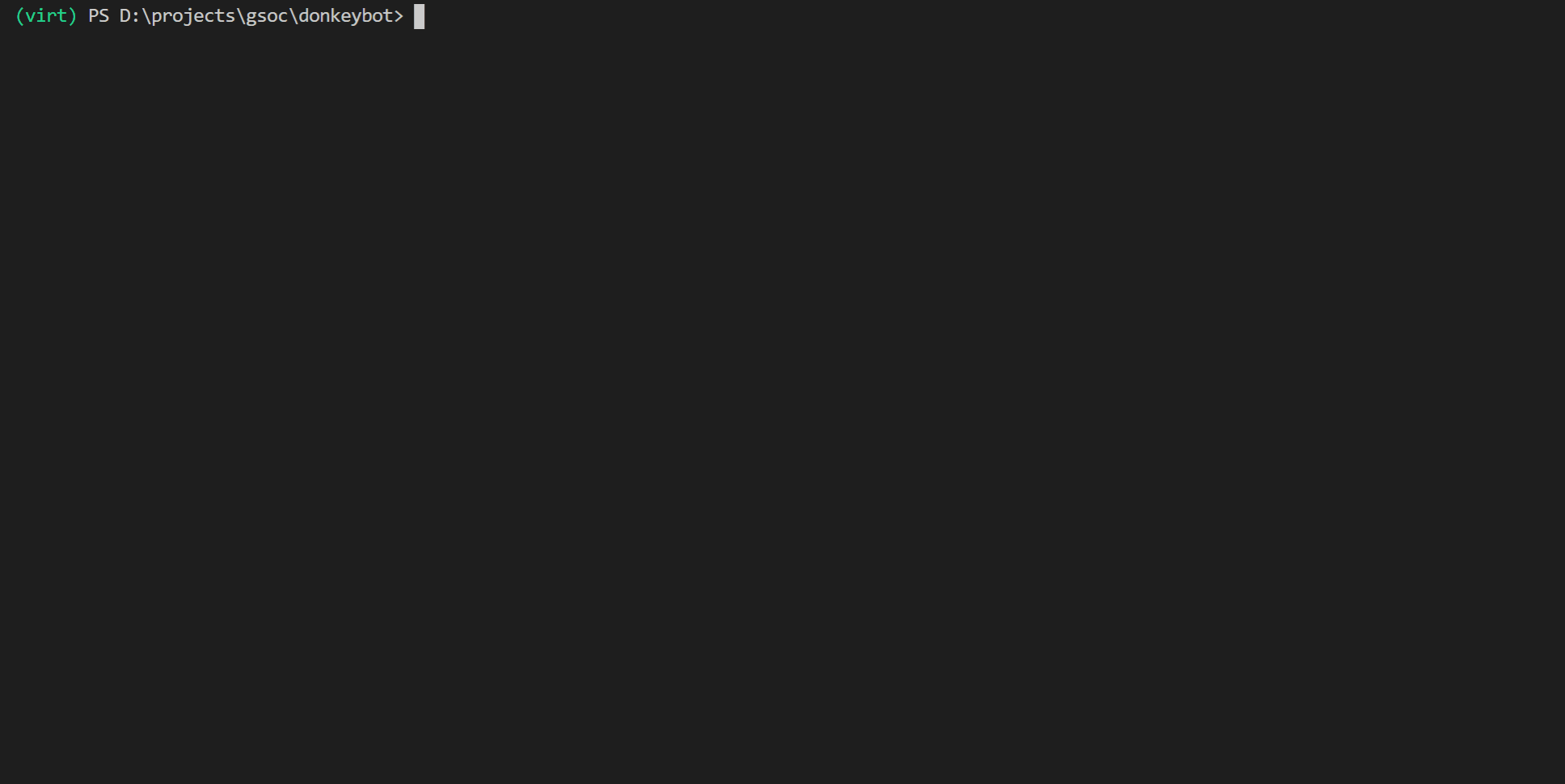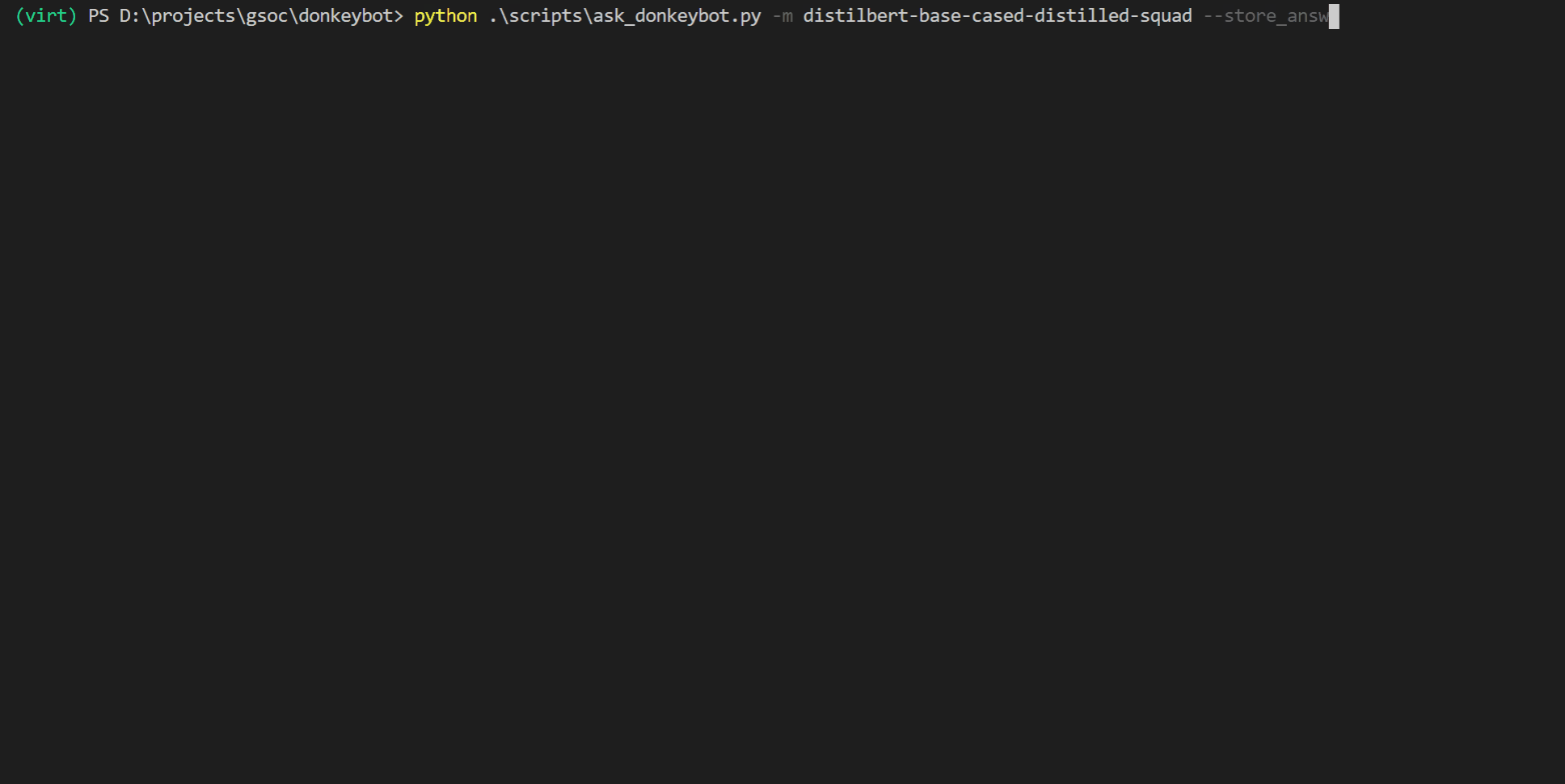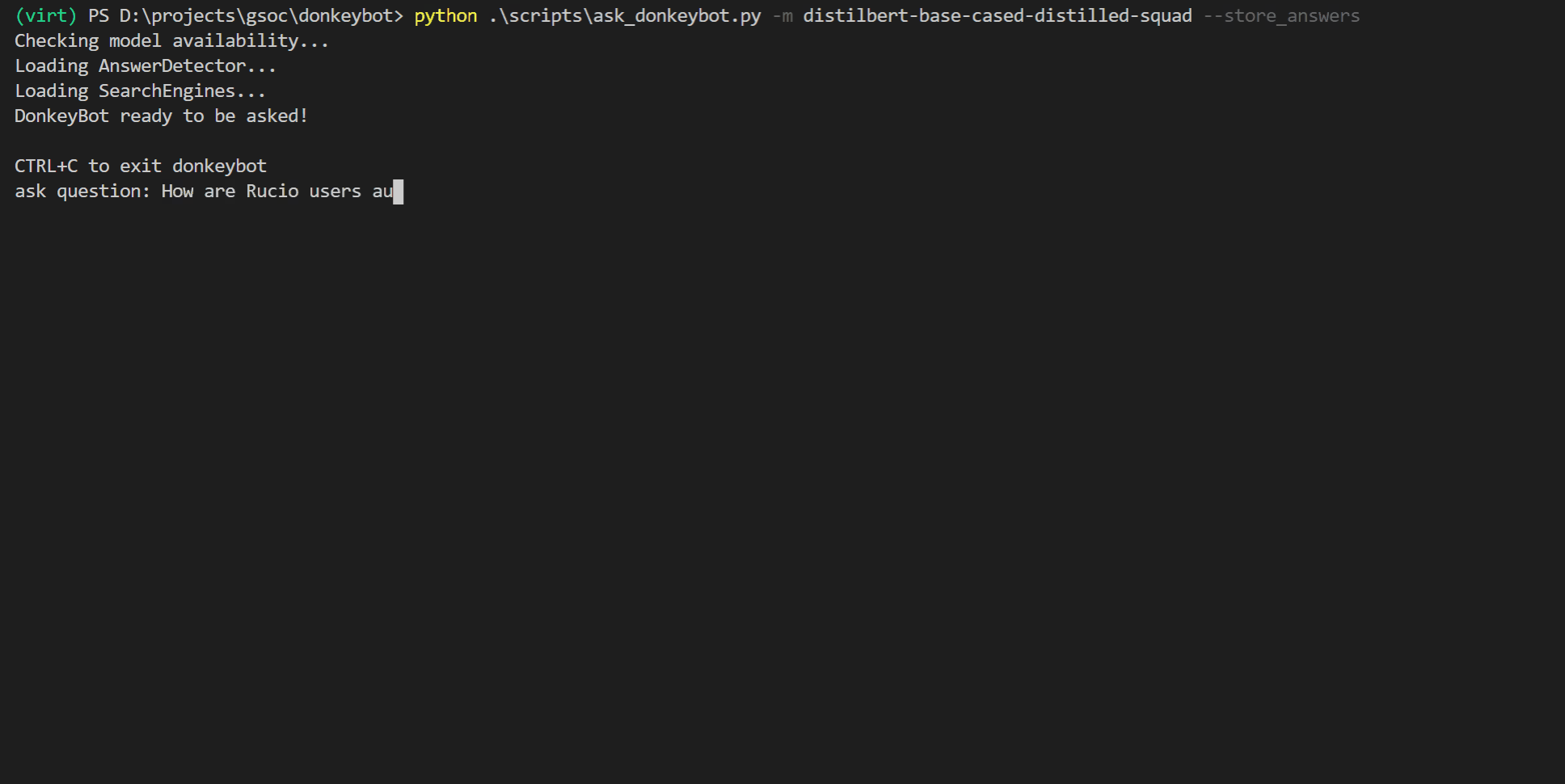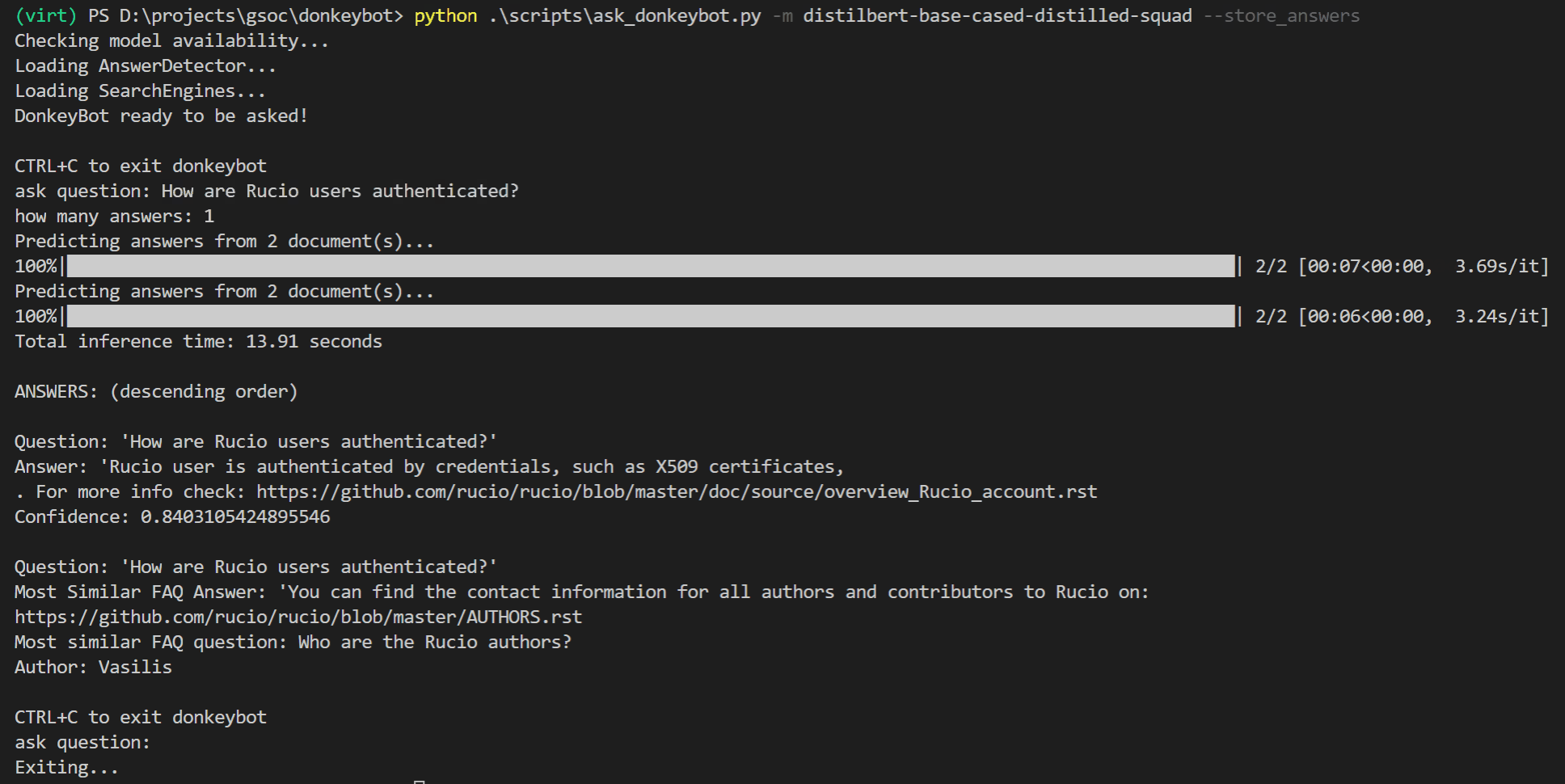
Plus d’exemples et d’informations peuvent être trouvés dans la section Comment utiliser.
Étape 1 : Une installation Python 3.x 64 bits est requise par PyTorch.
Étape 2 : Pour installer PyTorch, rendez-vous sur https://pytorch.org/ et suivez le guide de démarrage rapide en fonction de votre système d'exploitation.
# versions used in development
torch == 1.6 . 0 - - find - links https : // download . pytorch . org / whl / torch_stable . html
torchvision == 0.7 . 0 - - find - links https : // download . pytorch . org / whl / torch_stable . htmlÉtape 3 : Clonez le référentiel sur votre machine de développement.
$ git clone https://github.com/rucio/donkeybot.git
$ cd donkeybotÉtape 4 : Pour des exigences supplémentaires, exécutez.
$ pip install -r requirements.txtÉtape 5 : Créez et remplissez le stockage de données de Donkeybot.
$ python scripts/build_donkeybot -t < GITHUB_API_TOKEN >Consultez la page Mise en route pour plus de détails sur la contribution, le lancement du mode développeur et les tests.
Pour les bugs, les questions et les discussions, veuillez utiliser les problèmes GitHub ou contacter l'étudiant @mageirakos.
Sous licence Apache, version 2.0 ;
http://www.apache.org/licenses/LICENSE-2.0


