Moteur de récupération de mèmes
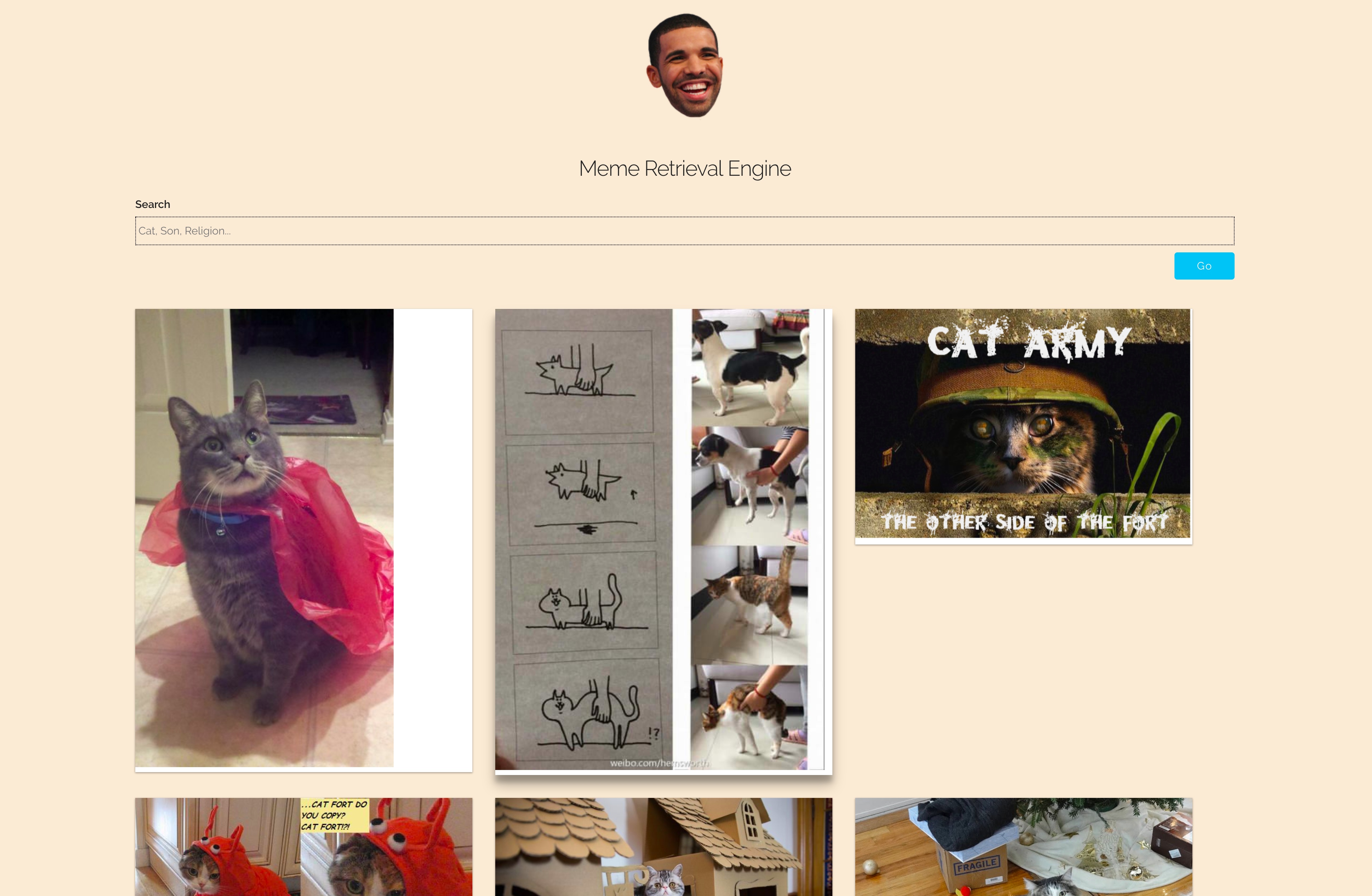
Description du projet
Technologies employées
- Traitement d'images
- Apprentissage automatique
- Traitement du langage naturel
- Scripts Shell
Collection
Les mèmes sont collectés à partir de subreddits populaires à l'aide d'un script scraper scrape/scraper.py
Standardisation
- Les mèmes collectés sont placés dans le dossier
raw et le script standard.py est exécuté - Chaque nom de fichier est extrait et stocké dans un fichier texte à côté du nouveau nom de fichier hexadécimal généré pour l'image.
- Les images standardisées sont stockées dans le dossier
processed
Extraction de requêtes
- La requête saisie est divisée en mots et les synonymes de chaque mot sont ajoutés à la liste des
related queries à l'aide de la bibliothèque nltk - Nous analysons la base de données pour faire correspondre les mots avec les mots dans
related queries - Cela élargit la zone de recherche et minimise les scénarios de sortie nulle
Pertinence pour la requête
- Les mèmes sont classés par ordre de pertinence par rapport à la requête de recherche
- Cela se fait en attribuant un score à chaque mème présent dans la base de données puis en triant par ordre décroissant des scores.
Reconnaissance optique de caractères
- L'OCR est effectuée à l'aide de Tesseract pour extraire le texte des mèmes, ce qui est une partie essentielle du projet.
- Le texte extrait n'est pas parfaitement précis, donc la sortie de l'ocr est introduite dans le correcteur orthographique de la bibliothèque
autocorrect Python. - Le correcteur orthographique rend la conversion plus précise
Tests rapides
Pour exécuter l'interface graphique et tester les fonctionnalités, tapez simplement
Collecter et exécuter
- Pour collecter les mèmes des subreddits
- Le script bash prépare la base de données qui permet au Meme Engine de fonctionner correctement
- Pour exécuter le type Meme Retrieval Engine (Meme Finder)
- Saisissez la requête dans le champ de texte et cliquez sur
Go - Les mèmes sont triés en fonction de leur pertinence
- Les mèmes sélectionnés peuvent être parcourus à l'aide des boutons
Next et Previous
Ajouter de nouveaux sous-reddits à la liste
Exigences
- cv2 (OpenCV)
- pytesseract
- nltk
- PIL
- hashlib
- fermer
- correction automatique
- pymongo
Améliorations futures
- Ajout de fonctionnalités à la barre de progression
- Corriger la mise à l'échelle de la taille des mèmes à afficher sur le canevas
- Ajout d'une fonctionnalité pour vider les mèmes stockés
- Stocker des modèles de mèmes populaires, vérifier la similarité des images et associer des mots-clés spéciaux
Documentation
Documentation de MemeFinder


