NekoImageGallery
v1.3.0
Un moteur de recherche d'images IA en ligne basé sur le modèle Clip et la base de données vectorielles Qdrant. Prend en charge la recherche par mot-clé et la recherche d'images similaires.
中文文档

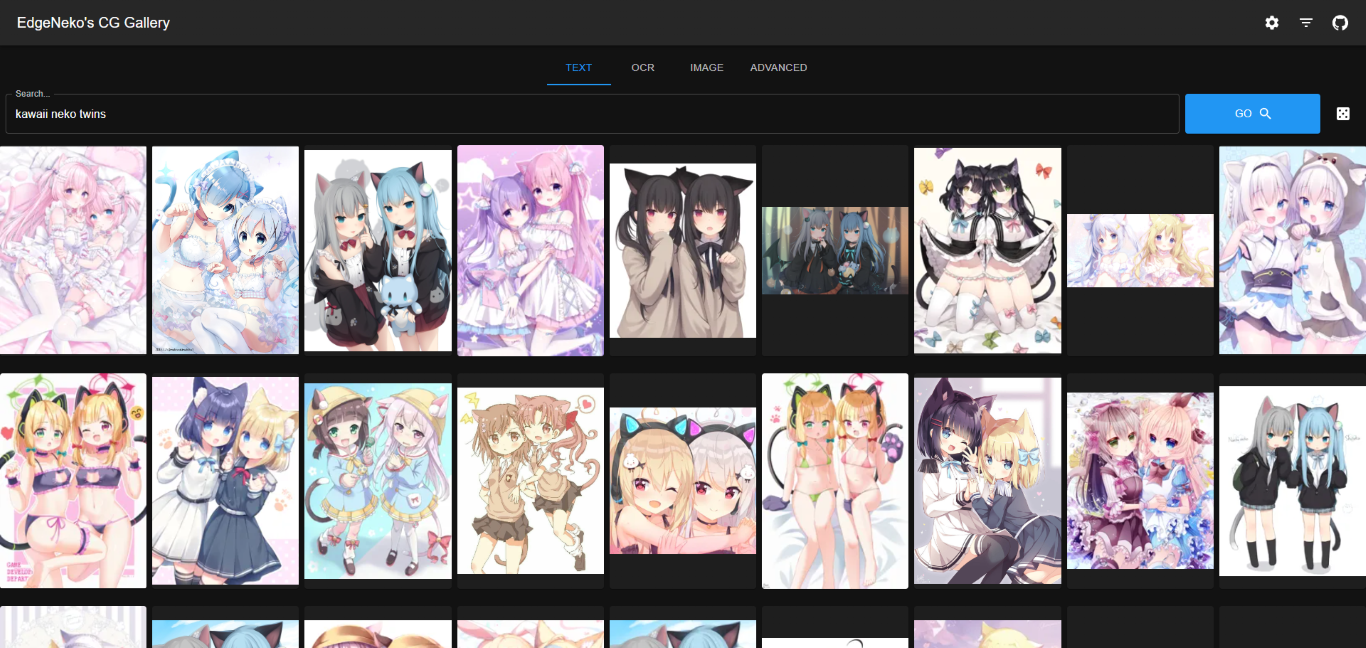
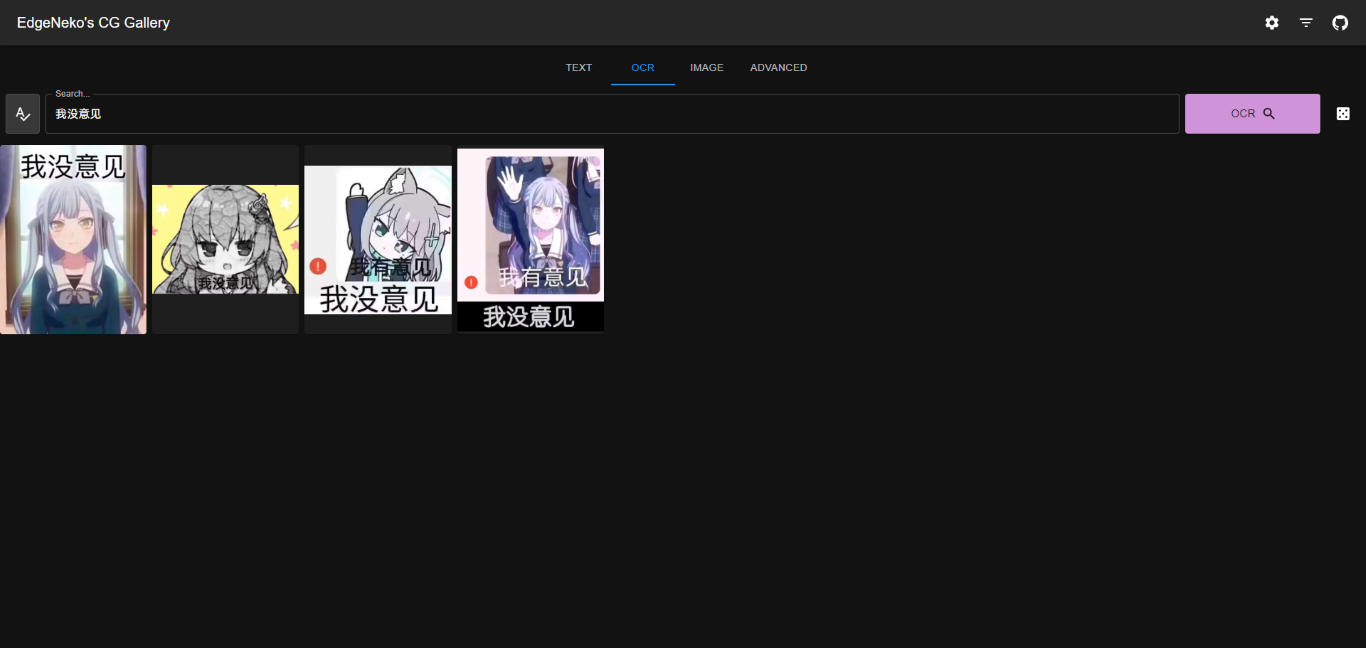
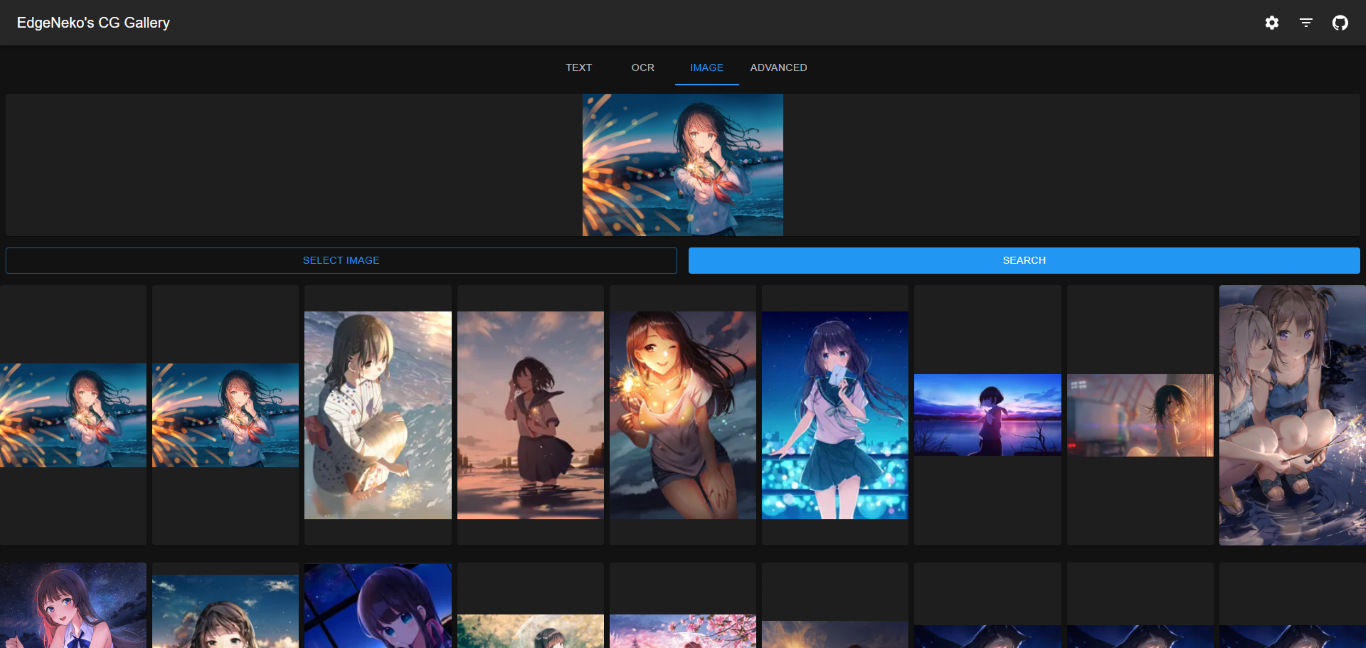
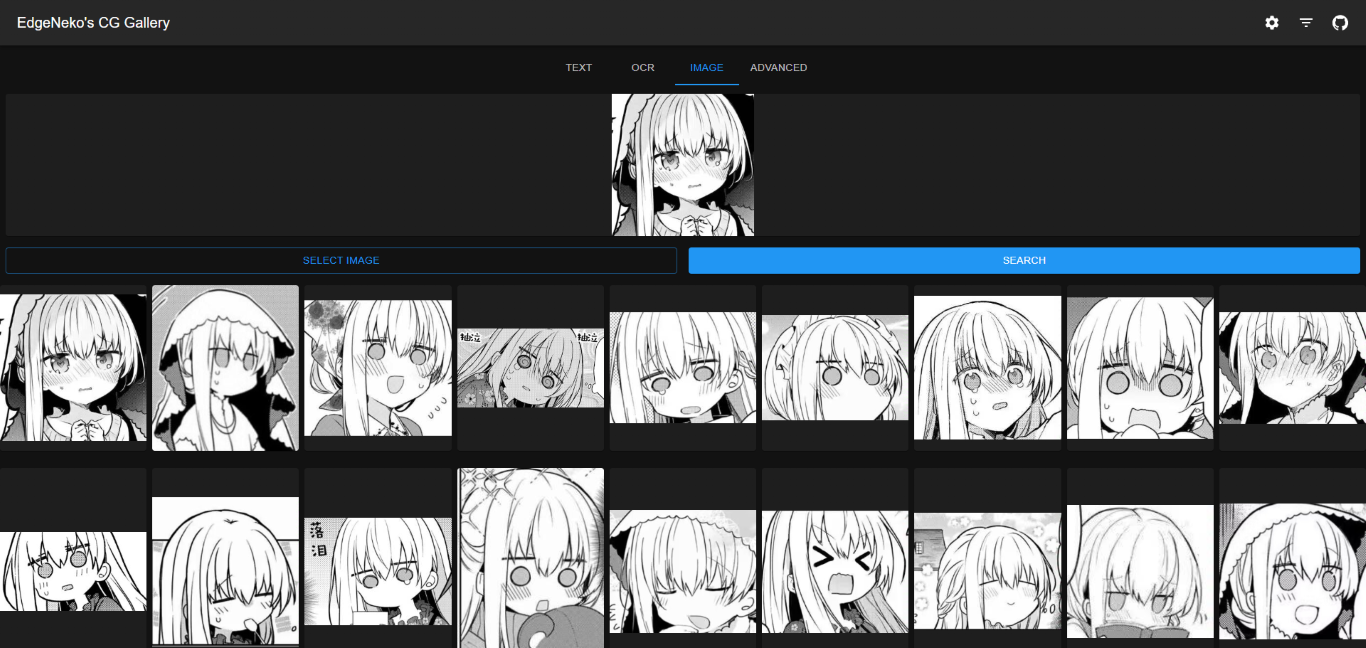
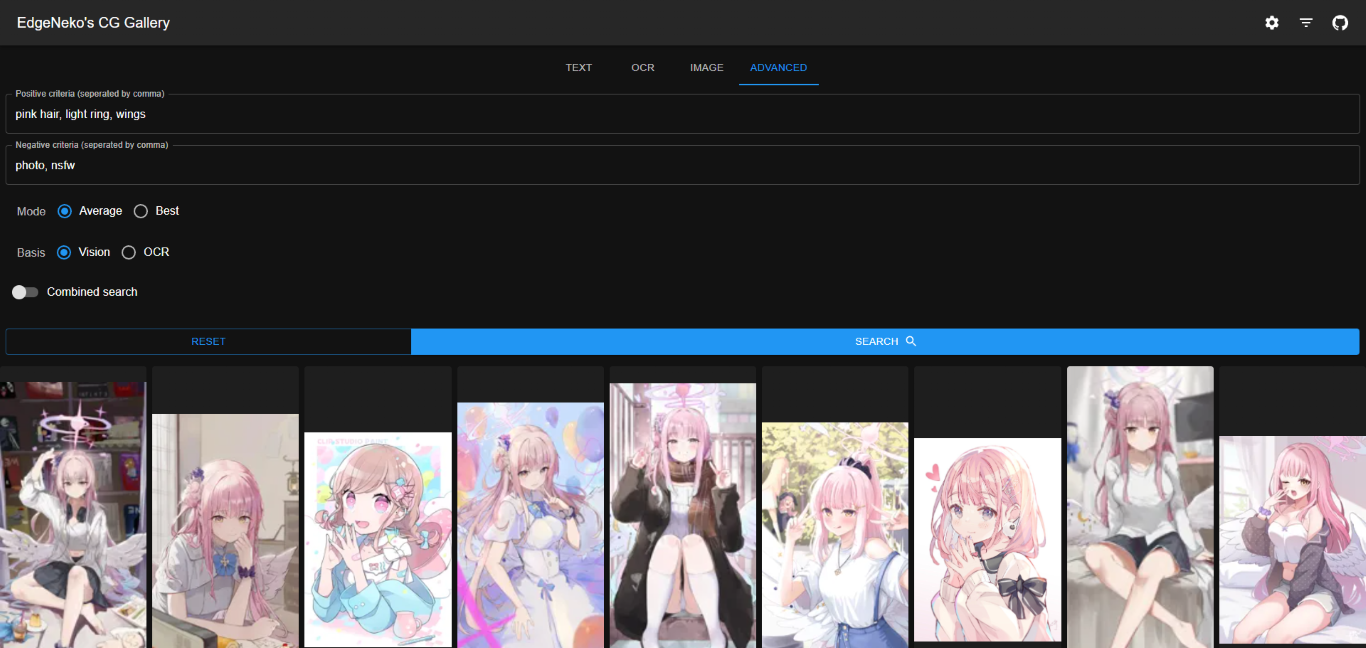
Les captures d'écran ci-dessus peuvent contenir des images protégées par le droit d'auteur de différents artistes, veuillez ne pas les utiliser à d'autres fins.
Dans la plupart des cas, nous recommandons d'utiliser la base de données Qdrant pour stocker les métadonnées. La base de données Qdrant offre des performances de récupération efficaces, une évolutivité flexible et une meilleure sécurité des données.
Veuillez déployer la base de données Qdrant conformément à la documentation Qdrant. Il est recommandé d'utiliser Docker pour le déploiement.
Si vous ne souhaitez pas déployer Qdrant vous-même, vous pouvez utiliser le service en ligne fourni par Qdrant.
Le stockage de fichiers local stocke directement les métadonnées des images (y compris les vecteurs de caractéristiques, etc.) dans une base de données SQLite locale. Il n’est recommandé que pour les déploiements à petite échelle ou les déploiements de développement.
Le stockage de fichiers local ne nécessite pas de processus de déploiement de base de données supplémentaire, mais présente les inconvénients suivants :
O(n) . Par conséquent, si l’échelle des données est grande, les performances de recherche et d’indexation diminueront.v1.0.0 ).python -m venv .venv
. .venv/bin/activateSi vous souhaitez utiliser l'accélération CUDA pour l'inférence, assurez-vous d'installer une version de PyTorch prise en charge par CUDA à cette étape. Après l'installation, vous pouvez utiliser
torch.cuda.is_available()pour confirmer si CUDA est disponible.
pip install -r requirements.txtconfig/ , vous pouvez modifier directement default.env , mais il est recommandé de créer un nouveau fichier nommé local.env et de remplacer la configuration dans default.env .python main.py--host pour spécifier l'adresse IP à laquelle vous souhaitez vous lier (la valeur par défaut est 0.0.0.0) et --port pour spécifier le port auquel vous souhaitez vous lier (la valeur par défaut est 8000).python main.py --help .Les images Docker de NekoImageGallery sont créées et publiées sur Docker Hub, y compris les variantes serval :
| Balises | Description | Taille de la dernière image |
|---|---|---|
edgeneko/neko-image-gallery:<version>edgeneko/neko-image-gallery:<version>-cudaedgeneko/neko-image-gallery:<version>-cuda12.1 | Prend en charge l'inférence GPU avec CUDA12.1 | |
edgeneko/neko-image-gallery:<version>-cuda11.8 | Prend en charge l'inférence GPU avec CUDA11.8 | |
edgeneko/neko-image-gallery:<version>-cpu | Prend uniquement en charge l'inférence CPU |
Où <version> est le numéro de version ou l'alias de version de NekoImageGallery, comme suit :
| Version | Description |
|---|---|
latest | La dernière version stable de NekoImageGallery |
v*.*.* / v*.* | Le numéro de version spécifique (correspond aux balises Git) |
edge | La dernière version de développement de NekoImageGallery peut contenir des fonctionnalités instables et des modifications importantes. |
Dans chaque image, nous avons regroupé les dépendances nécessaires, les poids de modèle openai/clip-vit-large-patch14 , les poids de modèle bert-base-chinese et les modèles easy-paddle-ocr pour fournir une image complète et prête à l'emploi.
Les images utilisent /opt/NekoImageGallery/static comme volume pour stocker les fichiers image, montez-les sur votre propre volume ou répertoire si un stockage local est requis.
Pour la configuration, nous suggérons d'utiliser des variables d'environnement pour remplacer la configuration par défaut. Les secrets (comme les jetons API) peuvent être fournis par les secrets Docker.
nvidia-container-runtime (utilisateurs CUDA uniquement) Si vous souhaitez utiliser l'accélération CUDA, vous devez installer nvidia-container-runtime sur votre système. Veuillez vous référer à la documentation officielle pour l'installation.
Document connexe :
- https://docs.docker.com/config/containers/resource_constraints/#gpu
- https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
- https://nvidia.github.io/nvidia-container-runtime/
docker-compose.yml depuis le référentiel. # For cuda deployment (default)
wget https://raw.githubusercontent.com/hv0905/NekoImageGallery/master/docker-compose.yml
# For CPU-only deployment
wget https://raw.githubusercontent.com/hv0905/NekoImageGallery/master/docker-compose-cpu.yml && mv docker-compose-cpu.yml docker-compose.yml # start in foreground
docker compose up
# start in background(detached mode)
docker compose up -dIl existe des moyens de télécharger des images sur NekoImageGallery
python main.py local-index < path-to-your-image-directory >python main.py local-index --help pour plus d'informations. La documentation de l'API est fournie par l'interface utilisateur Swagger intégrée de FastAPI. Vous pouvez accéder à la documentation de l'API en visitant le chemin /docs ou /redoc du serveur.
Ce projet fonctionne avec NekoImageGallery :D
Il existe de nombreuses façons de contribuer au projet : journaliser les bogues, soumettre des demandes d'extraction, signaler des problèmes et créer des suggestions.
Même si vous disposez d'un accès push sur le référentiel, vous devez créer des branches de fonctionnalités personnelles lorsque vous en avez besoin. Cela maintient le référentiel principal propre et votre flux de travail hors de vue.
Nous sommes également intéressés par vos commentaires sur l'avenir de ce projet. Vous pouvez soumettre une suggestion ou une demande de fonctionnalité via le suivi des problèmes. Pour rendre ce processus plus efficace, nous demandons que ceux-ci incluent plus d'informations pour aider à les définir plus clairement.
Copyright 2023 EdgeNeko
Sous licence AGPLv3.


