idt
1.0.0

L'outil d'ensemble de données d'image (IDT) est une application CLI développée pour faciliter et accélérer la création d'ensembles de données d'image à utiliser pour l'apprentissage en profondeur. L'outil y parvient en récupérant les images de plusieurs moteurs de recherche tels que duckgo, bing et deviantart. IDT optimise également l'ensemble de données d'image, bien que cette fonctionnalité soit facultative, l'utilisateur peut réduire et compresser les images pour une taille et des dimensions de fichier optimales. Un exemple d'ensemble de données créé à l'aide d'idt et contenant une quantité totale de 23 688 fichiers image ne pèse que 559,2 mégaoctets.
Je suis fier d'annoncer notre nouvelle version ! ??
Ce qui a changé
Vous pouvez l'installer via pip ou en clonant ce référentiel.
user@admin:~ $ pip3 install idt
OU
user@admin:~ $ git clone https://github.com/deliton/idt.git && cd idt
user@admin:~/idt $ sudo python3 setup.py install
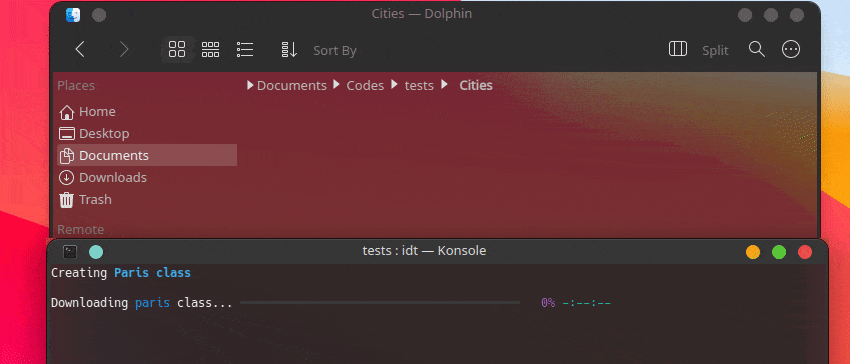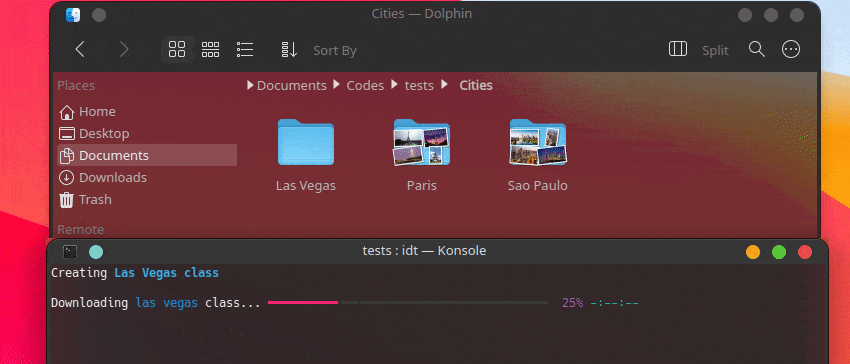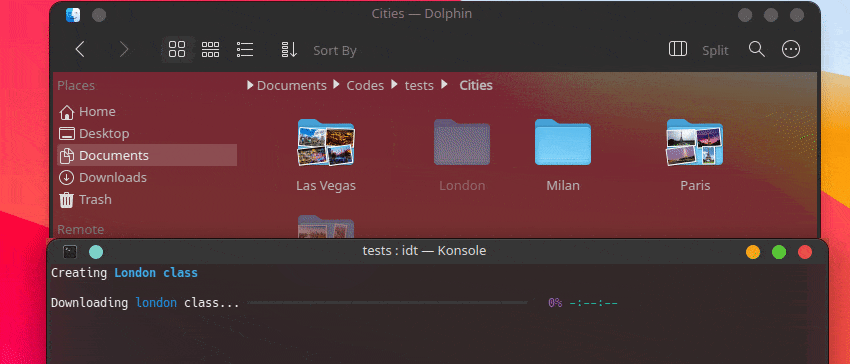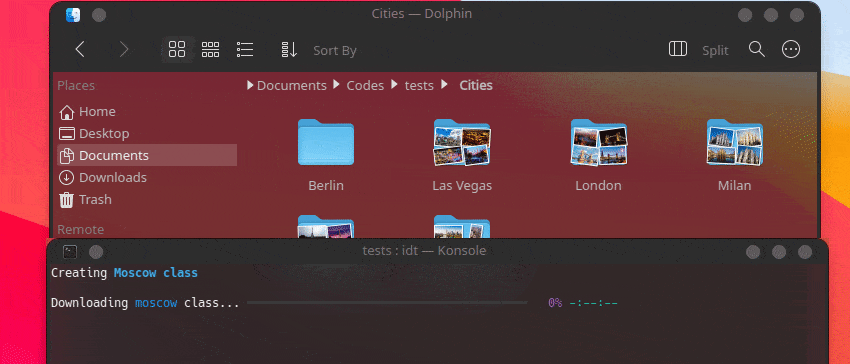
Le moyen le plus rapide de démarrer avec IDT consiste à exécuter la simple commande « exécuter ». Écrivez simplement dans votre console préférée quelque chose comme :
user@admin:~ $ idt run -i apples Cela téléchargera rapidement 50 images de pommes. Par défaut, il utilise le moteur de recherche duckgo pour ce faire. La commande run accepte les options suivantes :
| Option | Description |
|---|---|
| -i ou --entrée | le mot-clé pour trouver les images souhaitées. |
| -s ou --taille | la quantité d'images à télécharger. |
| -e ou --moteur | le moteur de recherche souhaité (options : duckgo, bing, bing_api et flickr_api) |
| --méthode-resize | choisissez une méthode de redimensionnement des images. (options : long_side, short_side et smartcrop) |
| -est ou --image-size | option pour définir le rapport de taille d’image souhaité. par défaut = 512 |
| -ak ou --api-key | Si vous utilisez un moteur de recherche nécessitant une clé API, cette option est obligatoire |
IDT nécessite un fichier de configuration qui lui indique comment votre ensemble de données doit être organisé. Vous pouvez le créer à l'aide de la commande suivante :
user@admin:~ $ idt initCette commande déclenchera le créateur du fichier de configuration et demandera les paramètres de l'ensemble de données souhaités. Dans cet exemple, créons un ensemble de données contenant des images de vos voitures préférées. Les premiers paramètres que cette commande demandera sont quel nom doit avoir votre ensemble de données ? Dans cet exemple, nommons notre ensemble de données « Mes voitures préférées »
Insert a name for your dataset: : My favorite carsEnsuite, l'outil vous demandera combien d'échantillons par recherche sont nécessaires pour monter votre ensemble de données. Afin de créer un bon ensemble de données pour l'apprentissage en profondeur, de nombreuses images sont nécessaires et comme nous utilisons un moteur de recherche pour récupérer des images, de nombreuses recherches avec des mots-clés différents sont nécessaires pour monter un ensemble de données de bonne taille. Cette valeur correspondra au nombre d'images à télécharger à chaque recherche. Dans cet exemple, nous avons besoin d'un ensemble de données avec 250 images dans chaque classe et nous utiliserons 5 mots-clés pour monter chaque classe. Donc, si nous tapons le nombre 50 ici, IDT téléchargera 50 images de chaque mot-clé fourni. Si nous fournissons 5 mots-clés, nous devrions obtenir les 250 images requises.
How many samples per search will be necessary? : 50L'outil demandera maintenant un rapport de taille d'image. Étant donné que l'utilisation de grandes images pour entraîner des réseaux de neurones n'est pas une chose viable, nous pouvons éventuellement choisir l'un des rapports de taille d'image suivants et réduire nos images à cette taille. Dans cet exemple, nous optons pour 512x512, bien que 256x256 serait une option encore meilleure pour cette tâche.
Choose images resolution:
[1] 512 pixels / 512 pixels (recommended)
[2] 1024 pixels / 1024 pixels
[3] 256 pixels / 256 pixels
[4] 128 pixels / 128 pixels
[5] Keep original image size
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
What is the desired image size ratio: 1Et puis choisissez "longer_side" pour la méthode de redimensionnement.
[1] Resize image based on longer side
[2] Resize image based on shorter side
[3] Smartcrop
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
Desired Image resize method: : longer_side
Vous devez maintenant choisir le nombre de classes/dossiers que votre ensemble de données doit contenir. Dans cet exemple, cette pièce peut être très personnelle, mais mes voitures préférées sont : Chevrolet Impala, Range Rover Evoque, Tesla Model X et (pourquoi pas) AvtoVAZ Lada. Donc dans ce cas nous avons 4 classes, une pour chaque favori.
How many image classes are required? : 4Ensuite, il vous sera demandé de choisir entre l'un des moteurs de recherche disponibles. Dans cet exemple, nous utiliserons DuckGO pour rechercher des images à notre place.
Choose a search engine:
[1] Duck GO (recommended)
[2] Bing
[3] Bing API
[4] Flickr API
Select option:: 1Nous devons maintenant remplir des formulaires de manière répétitive. Il faut nommer chaque classe et tous les mots-clés qui seront utilisés pour retrouver les images. Notez que cette partie peut être modifiée ultérieurement par votre propre code, pour générer plus de classes et de mots-clés.
Class 1 name: : Chevrolet ImpalaAprès avoir tapé le nom de la première classe, il nous sera demandé de fournir tous les mots-clés pour trouver l'ensemble de données. N'oubliez pas que nous avons demandé au programme de télécharger 50 images de chaque mot-clé, nous devons donc fournir 5 mots-clés dans ce cas pour obtenir les 250 images. Chaque mot clé DOIT être séparé par des virgules (,)
In order to achieve better results, choose several keywords that will
be provided to the search engine to find your class in different settings.
Example:
Class Name: Pineapple
keywords: pineapple, pineapple fruit, ananas, abacaxi, pineapple drawing
Type in all keywords used to find your desired class, separated by commas: Chevrolet Impala 1967 car photos,
chevrolet impala on the road, chevrolet impala vintage car, chevrolet impala convertible 1961, chevrolet impala 1964 lowrider
Répétez ensuite le processus de remplissage du nom de la classe et de ses mots-clés jusqu'à ce que vous remplissiez les 4 classes requises.
Dataset YAML file has been created successfully. Now run idt build to mount your dataset!Votre fichier de configuration de jeu de données a été créé. Maintenant, appliquez simplement la commande suivante et voyez la magie opérer :
user@admin:~ $ idt buildEt attendez que l'ensemble de données soit monté :
Creating Chevrolet Impala class
Downloading Chevrolet Impala 1967 car photos [#########################-----------] 72% 00:00:12
À la fin, toutes vos images seront disponibles dans un dossier portant le nom de l'ensemble de données. En outre, un fichier CSV contenant les statistiques de l'ensemble de données est également inclus dans le dossier racine de l'ensemble de données.
Étant donné que l'apprentissage profond vous oblige souvent à diviser votre ensemble de données en un sous-ensemble de dossiers de formation/validation, ce projet peut également le faire pour vous ! Exécutez simplement :
user@admin:~ $ idt splitVous devez maintenant choisir une proportion train/valide. Dans cet exemple j'ai choisi que 70% des images seront réservées à la formation, tandis que le reste sera réservé à la validation :
Choose the desired proportion of images of each class to be distributed in train/valid folders.
What percentage of images should be distributed towards training?
(0-100): 70
70 percent of the images will be moved to a train folder, while 30 percent of the remaining images
will be stored in a validation folder.
Is that ok? [Y/n]: yEt c'est tout ! Le partage de l'ensemble de données devrait maintenant être trouvé avec les sous-répertoires train/valid correspondants.
Ce projet est développé pendant mon temps libre et il nécessite encore beaucoup d'efforts pour être exempt de bugs. Les demandes de tirage et les contributeurs sont vraiment appréciés, n'hésitez pas à contribuer de toutes les manières possibles !


