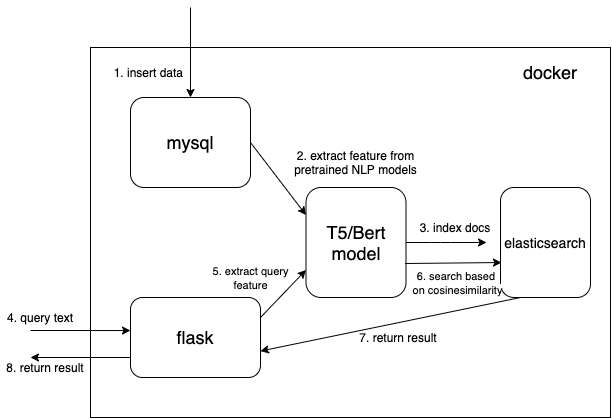
T5Elasticsearch
1.0.0
Vous trouverez ci-dessous un exemple de recherche d'emploi :
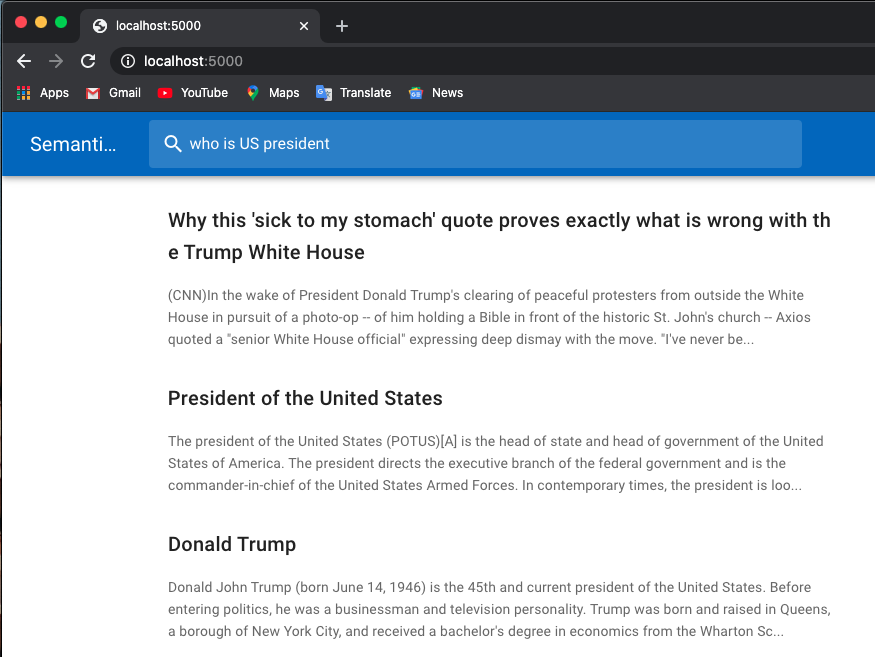
J'utilise des modèles pré-entraînés à partir de transformateurs Huggingface.
Téléchargez manuellement le tokenizer pré-entraîné et le modèle t5/bert dans les répertoires locaux. Vous pouvez vérifier les modèles ici.
J'utilise le modèle 't5-small', cochez ici et cliquez sur List all files in model pour télécharger les fichiers. 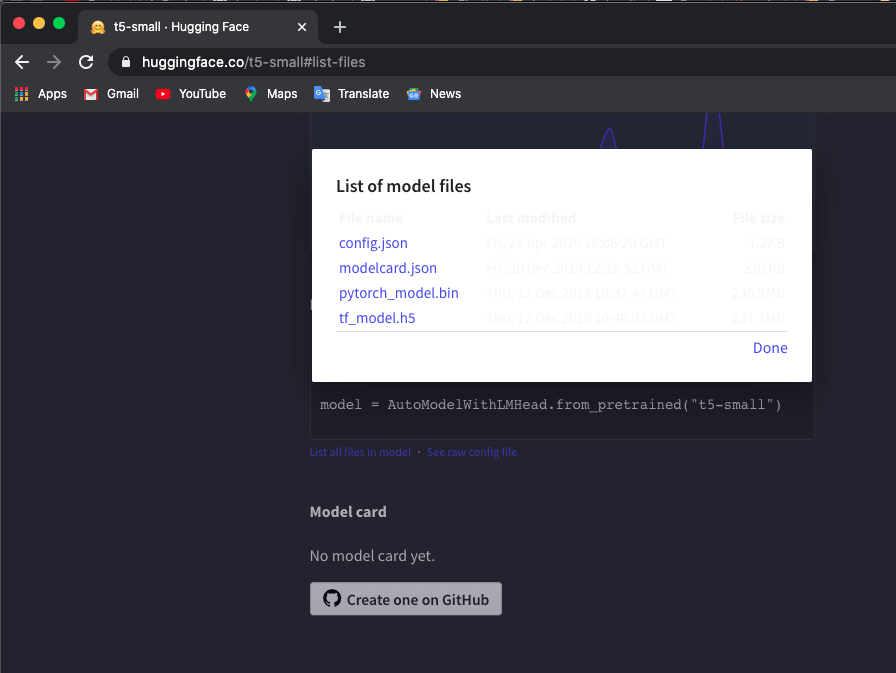
Notez la structure du répertoire des fichiers téléchargés manuellement.
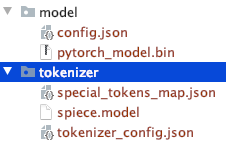
Vous pouvez utiliser d'autres modèles T5 ou Bert.
Si vous téléchargez d'autres modèles, consultez la liste des modèles pré-entraînés des transformateurs Hugoface pour vérifier le nom du modèle.
$ export TOKEN_DIR=path_to_your_tokenizer_directory/tokenizer
$ export MODEL_DIR=path_to_your_model_directory/model
$ export MODEL_NAME=t5-small # or other model you downloaded
$ export INDEX_NAME=docsearch$ docker-compose up --build J'utilise également docker system prune pour supprimer tous les conteneurs, réseaux et images inutilisés afin d'obtenir plus de mémoire. Augmentez la mémoire de votre docker (j'utilise 8GB ) si vous rencontrez Container exits with non-zero exit code 137 .
Nous utilisons un type de données vectoriel dense pour enregistrer les fonctionnalités extraites des modèles NLP pré-entraînés (t5 ou bert ici, mais vous pouvez ajouter vous-même les modèles pré-entraînés qui vous intéressent)
{
...
"text_vector" : {
"type" : " dense_vector " ,
"dims" : 512
}
...
} Dimensions dims:512 pour les modèles T5. Changez dims en 768 si vous utilisez des modèles Bert.
Lisez le document à partir de MySQL et convertissez le document au format json correct pour le regrouper dans elasticsearch.
$ cd index_files
$ pip install -r requirements.txt
$ python indexing_files.py
# or you can customize your parameters
# $ python indexing_files.py --index_file='index.json' --index_name='docsearch' --data='documents.jsonl'Accédez à http://127.0.0.1:5000.
Le code clé pour utiliser le modèle pré-entraîné pour extraire les fonctionnalités est la fonction get_emb dans les fichiers ./index_files/indexing_files.py et ./web/app.py .
def get_emb ( inputs_list , model_name , max_length = 512 ):
if 't5' in model_name : #T5 models, written in pytorch
tokenizer = T5Tokenizer . from_pretrained ( TOKEN_DIR )
model = T5Model . from_pretrained ( MODEL_DIR )
inputs = tokenizer . batch_encode_plus ( inputs_list , max_length = max_length , pad_to_max_length = True , return_tensors = "pt" )
outputs = model ( input_ids = inputs [ 'input_ids' ], decoder_input_ids = inputs [ 'input_ids' ])
last_hidden_states = torch . mean ( outputs [ 0 ], dim = 1 )
return last_hidden_states . tolist ()
elif 'bert' in model_name : #Bert models, written in tensorlow
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-multilingual-cased' )
model = TFBertModel . from_pretrained ( 'bert-base-multilingual-cased' )
batch_encoding = tokenizer . batch_encode_plus ([ "this is" , "the second" , "the thrid" ], max_length = max_length , pad_to_max_length = True )
outputs = model ( tf . convert_to_tensor ( batch_encoding [ 'input_ids' ]))
embeddings = tf . reduce_mean ( outputs [ 0 ], 1 )
return embeddings . numpy (). tolist ()Vous pouvez modifier le code et utiliser votre modèle pré-entraîné préféré. Par exemple, vous pouvez utiliser le modèle GPT2.
vous pouvez également personnaliser votre elasticsearch en utilisant votre propre fonction de score au lieu de cosineSimilarity dans .webapp.py .
Ce représentant est modifié en fonction de Hironsan/bertsearch, qui utilisent des packages bert-serving pour extraire les fonctionnalités de bert. Ça se limite à TF1.x


