context search engine
1.0.0

L'objectif principal de ce projet est de présenter les capacités de recherche vectorielle en fournissant une interface conviviale qui permet aux utilisateurs d'effectuer des recherches contextuelles dans un corpus de documents texte. En tirant parti de la puissance du BERT de Hugging Face et du FAISS de Facebook, nous renvoyons des passages de texte très pertinents basés sur la signification sémantique de la requête de l'utilisateur plutôt que sur de simples correspondances de mots clés. Ce projet sert de point de départ aux développeurs, chercheurs et passionnés qui souhaitent approfondir le monde de la recherche de texte contextualisée et améliorer leurs applications avec des techniques de pointe en PNL.
Mon objectif est de m'assurer que nous comprenons la base de données vectorielles en coulisses à partir de zéro.
Capture d'écran de l'application :
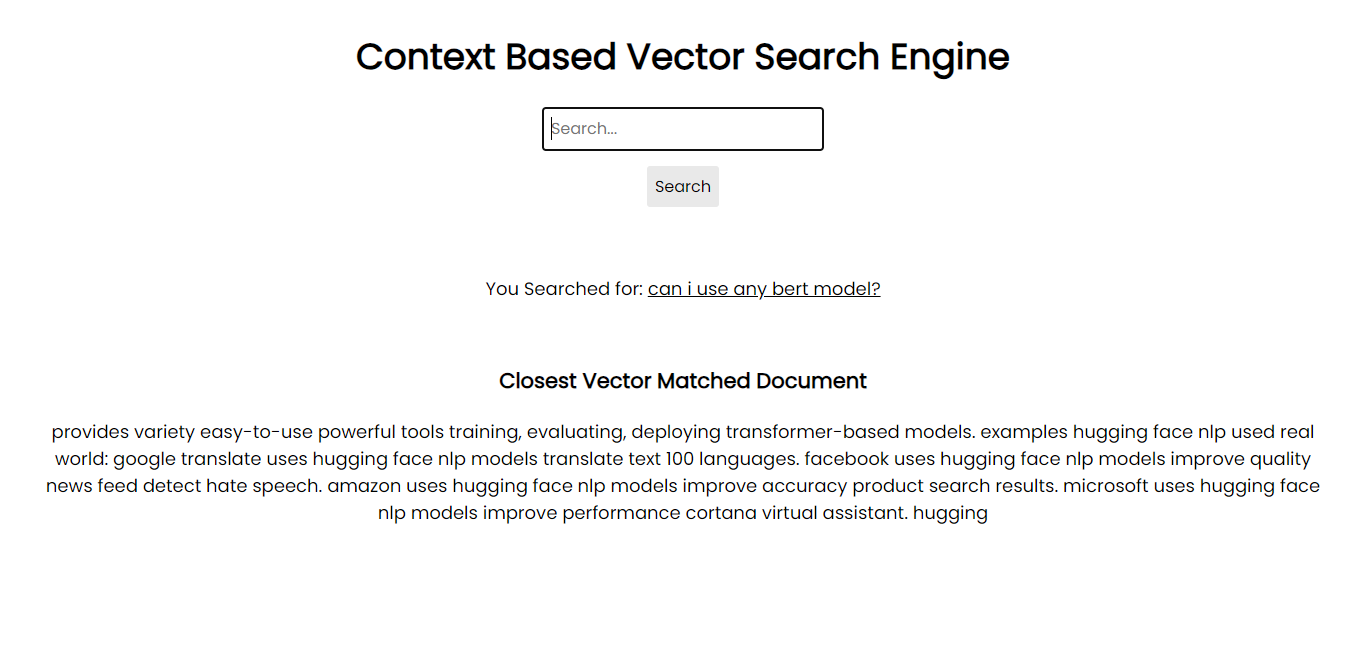
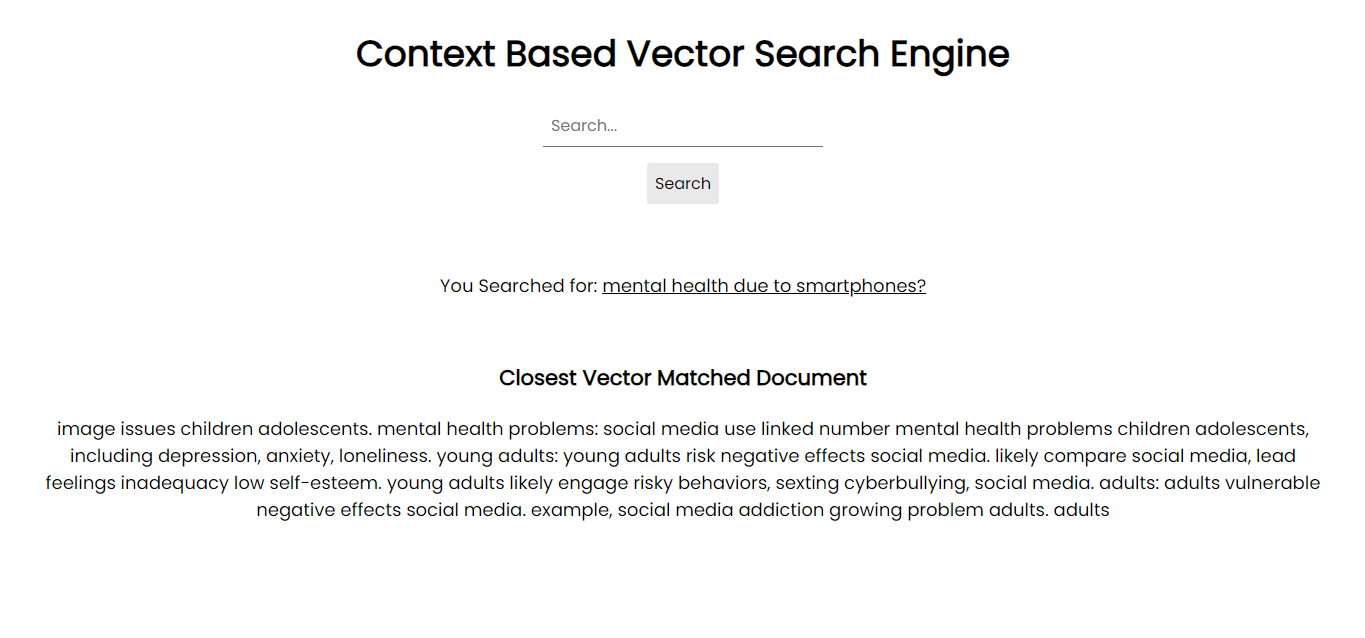
Afin de fonctionner sur votre système, vous pouvez installer tous les packages nécessaires via pip à l'aide des fichiers d'exigences :
pip install -r requirements.txtPour votre information, j'utilise Python 3.10.1.
Cependant, si vous disposez d'un GPU, vous êtes invité à installer le GPU FAISS pour des intégrations de bases de données plus rapides et plus volumineuses.
La version actuelle de ce projet comprend :
Bien que le projet offre un système de recherche contextuelle fonctionnel, il est conçu pour être modulaire, permettant une expansion et une intégration potentielles dans des systèmes ou des applications plus vastes.
Le fondement de ce projet réside dans la conviction que les techniques modernes de PNL peuvent offrir des résultats de recherche beaucoup plus précis et contextuellement pertinents par rapport aux méthodes traditionnelles basées sur des mots clés. Voici un aperçu de notre approche :
Sur la base de l'approche, j'ai divisé le projet en 2 sections :
Section 1 : Génération de données vectorielles consultables
Dans cette section, nous lisons d'abord les entrées des documents, les décomposons en morceaux plus petits, créons des vecteurs à l'aide d'un modèle basé sur BERT, puis les stockons efficacement à l'aide de FAISS. Voici un organigramme qui illustre la même chose.
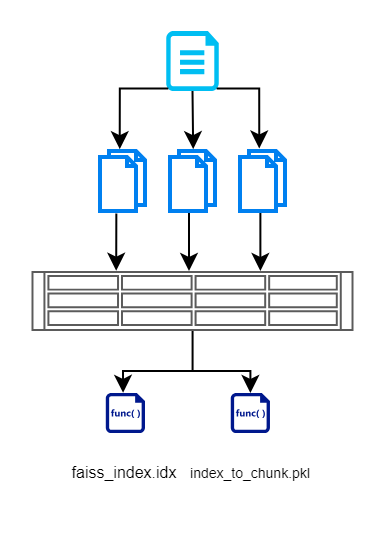
Nous créons un fichier d'index FAISS qui contient une représentation vectorielle du document fragmenté. Nous stockons également l'index de chaque morceau. Ceci est maintenu afin que nous n'ayons pas à interroger à nouveau la base de données/les documents. Cela nous aide à supprimer les opérations de lecture redondantes.
Nous effectuons cette section en utilisant create_index.py. Il générera les 2 fichiers ci-dessus. Si vous avez besoin d'utiliser d'autres modèles, êtes-vous prêt à le faire depuis le hub HuggingFace ?
Remarque : Si vous rencontrez des problèmes lors de la configuration des hyperparamètres pour les dimensions, consultez le fichier models config.json pour trouver des détails sur les dimensions du modèle que vous essayez d'utiliser.
Section 2 : Création d'une interface d'application consultable
Dans cette section, mon objectif est de créer une interface permettant aux utilisateurs d'interagir avec les documents. Je donne la priorité au design minimaliste sans poser d’obstacles supplémentaires.
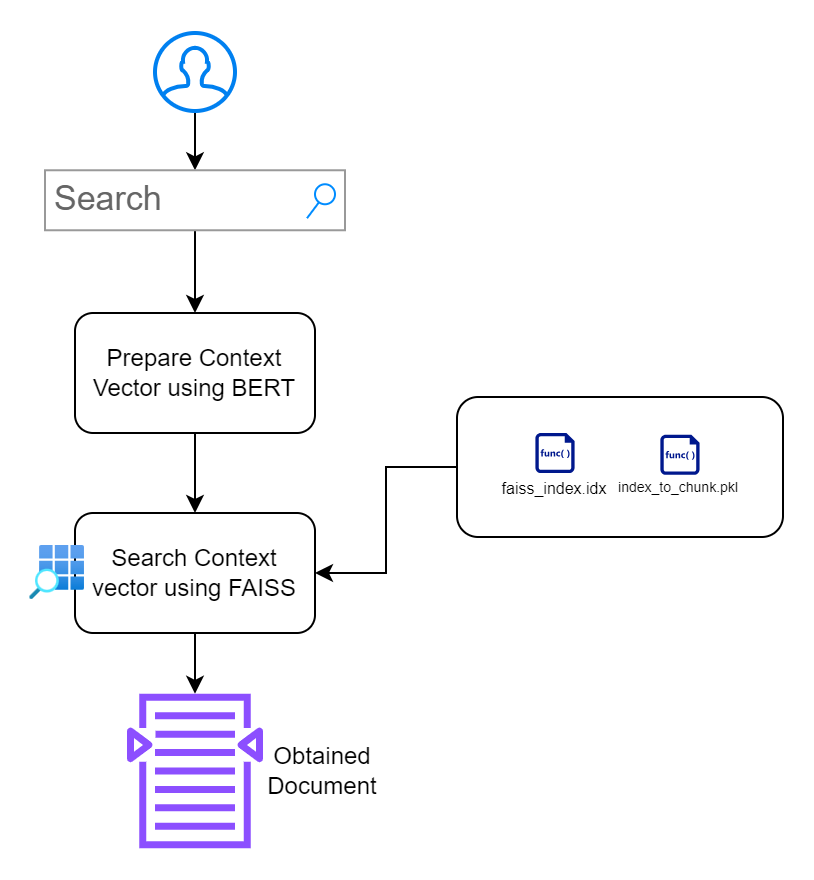
index.html : Page HTML frontale pour la saisie des requêtes de recherche.app.py : application Flask qui sert le front-end et gère les requêtes de recherche.search_engine.py : contient la logique pour la génération d'intégration, la recherche FAISS et la mise en évidence de mots clés. /context_search/
- templates/
- index.html
- static/
- css/
- style.css
- images/
- img1.png
- img2.png
- Approach.png files
- app.py
- search_engine.py
- create_index.py
- index_to_chunk.pkl
- faiss_index.idxfaiss_index.idx ) et d'un mappage qui l'accompagne de l'index au bloc de texte ( index_to_chunk.pkl ). python app.py
-- OR --
flask run --host=127.0.0.1 --port=5000
http://localhost:5000 .Il y a toujours place à des améliorations. Voici quelques améliorations potentielles et fonctionnalités supplémentaires qui peuvent être intégrées :
Ce projet est sous licence MIT. N'hésitez pas à utiliser en citant, modifier, distribuer et contribuer. En savoir plus.
Si vous souhaitez améliorer ce projet, vos contributions sont les bienvenues ! Veuillez ouvrir une Pull Request ou un Issue sur ce référentiel. Je donne essentiellement la priorité aux choses ci-dessus à faire pour des améliorations. D’autres pull request seront également prises en compte mais moins prioritaires.
Merci d'avance pour votre intérêt. :heureux: .


