textgenrnn
T
Entraînez facilement votre propre réseau neuronal générateur de texte, de n'importe quelle taille et complexité, sur n'importe quel ensemble de données de texte avec quelques lignes de code, ou entraînez-vous rapidement sur un texte à l'aide d'un modèle pré-entraîné.
textgenrnn est un module Python 3 au-dessus de Keras/TensorFlow pour créer des char-rnns, avec de nombreuses fonctionnalités intéressantes :
Vous pouvez jouer avec textgenrnn et entraîner n'importe quel fichier texte avec un GPU gratuitement dans ce carnet de laboratoire ! Lisez cet article de blog ou regardez cette vidéo pour plus d’informations !
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate () [Spoiler] Anyone else find this post and their person that was a little more than I really like the Star Wars in the fire or health and posting a personal house of the 2016 Letter for the game in a report of my backyard.
Le modèle inclus peut facilement être entraîné sur de nouveaux textes et peut générer un texte approprié même après un seul passage des données d'entrée .
textgen . train_from_file ( 'hacker_news_2000.txt' , num_epochs = 1 )
textgen . generate () Project State Project Firefox
Les poids des modèles sont relativement petits (2 Mo sur le disque) et ils peuvent facilement être enregistrés et chargés dans une nouvelle instance textgenrnn. En conséquence, vous pouvez jouer avec des modèles qui ont été formés sur des centaines de passages dans les données. (en fait, textgenrnn apprend si bien que vous devez augmenter considérablement la température pour une production créative !)
textgen_2 = textgenrnn ( '/weights/hacker_news.hdf5' )
textgen_2 . generate ( 3 , temperature = 1.0 ) Why we got money “regular alter”
Urburg to Firefox acquires Nelf Multi Shamn
Kubernetes by Google’s Bern
Vous pouvez également entraîner un nouveau modèle, avec la prise en charge des intégrations au niveau des mots et des couches RNN bidirectionnelles en ajoutant new_model=True à n'importe quelle fonction d'entraînement.
Il est également possible de s'impliquer dans le déroulement du résultat, étape par étape. Le mode interactif vous proposera les N principales options pour le caractère/mot suivant et vous permettra d'en choisir une.
Lors de l'exécution de textgenrnn dans le terminal, transmettez interactive=True et top=N pour generate . N est par défaut 3.
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate ( interactive = True , top_n = 5 )
Cela peut ajouter une touche humaine au résultat ; on a l'impression que c'est toi l'écrivain ! (référence)
textgenrnn peut être installé depuis pypi via pip :
pip3 install textgenrnnPour la dernière version de textgenrnn, vous devez disposer d'une version minimale de TensorFlow 2.1.0 .
Vous pouvez voir une démonstration des fonctionnalités communes et des options de configuration du modèle dans ce bloc-notes Jupyter.
/datasets contient des exemples d'ensembles de données utilisant les données Hacker News/Reddit pour la formation de textgenrnn.
/weights contient des modèles pré-entraînés sur les ensembles de données susmentionnés qui peuvent être chargés dans textgenrnn.
/outputs contient des exemples de texte générés à partir des modèles pré-entraînés ci-dessus.
textgenrnn est basé sur le projet char-rnn d'Andrej Karpathy avec quelques optimisations modernes, comme la possibilité de travailler avec de très petites séquences de texte.
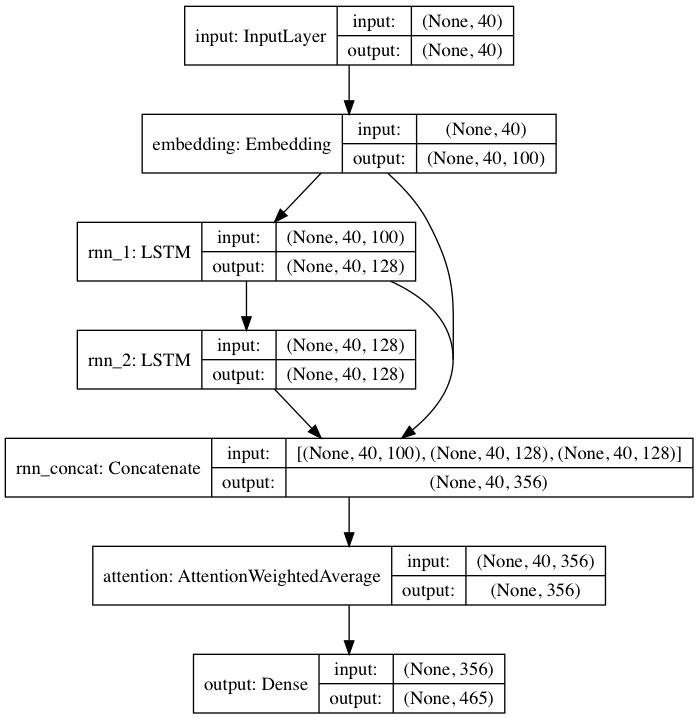
Le modèle pré-entraîné inclus suit une architecture de réseau neuronal inspirée de DeepMoji. Pour le modèle par défaut, textgenrnn prend en compte une entrée allant jusqu'à 40 caractères, convertit chaque caractère en un vecteur d'intégration de caractères de 100 D et les alimente dans une couche récurrente de mémoire à long-court-terme (LSTM) de 128 cellules. Ces sorties sont ensuite introduites dans un autre LSTM à 128 cellules. Les trois couches sont ensuite introduites dans une couche d'attention pour pondérer les caractéristiques temporelles les plus importantes et faire la moyenne ensemble (et puisque les intégrations + le 1er LSTM sont connectés par saut à la couche d'attention, les mises à jour du modèle peuvent se propager plus facilement vers elles et empêcher leur disparition. dégradés). Cette sortie est mappée aux probabilités pour un maximum de 394 caractères différents qu'ils soient le prochain caractère de la séquence, y compris les caractères majuscules, minuscules, la ponctuation et les emoji. (si vous entraînez un nouveau modèle sur un nouvel ensemble de données, tous les paramètres numériques ci-dessus peuvent être configurés)
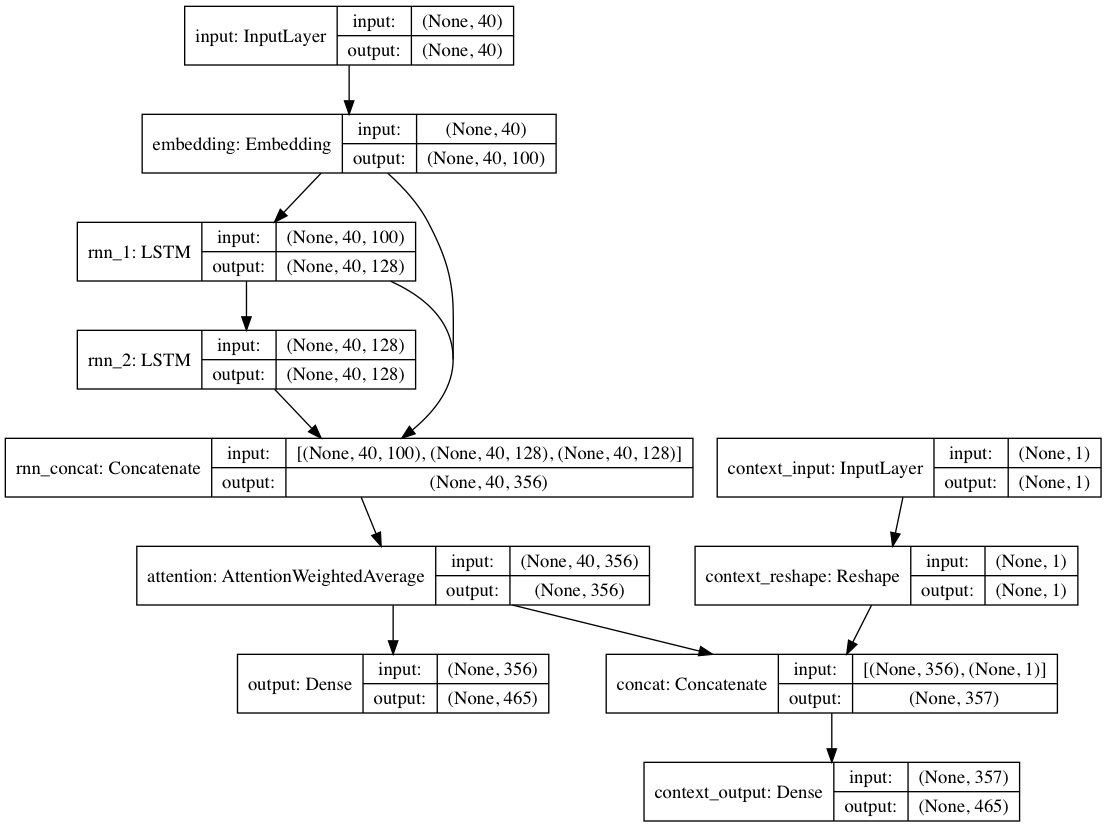
Alternativement, si des étiquettes de contexte sont fournies avec chaque document texte, le modèle peut être entraîné dans un mode contextuel, dans lequel le modèle apprend le texte en fonction du contexte afin que les couches récurrentes apprennent le langage décontextualisé . Le chemin texte uniquement peut s'appuyer sur les couches décontextualisées ; au total, cela se traduit par une formation beaucoup plus rapide et de meilleures performances quantitatives et qualitatives du modèle que la simple formation du modèle à partir du texte seul.
Les pondérations de modèle incluses dans le package sont formées sur des centaines de milliers de documents texte provenant de soumissions Reddit (via BigQuery), provenant d'une variété très diversifiée de sous-reddits. Le réseau a également été formé en utilisant l'approche décontextuelle mentionnée ci-dessus afin à la fois d'améliorer les performances de la formation et d'atténuer les biais d'auteur.
Lors du réglage fin du modèle sur un nouvel ensemble de données de textes à l'aide de textgenrnn, toutes les couches sont recyclées. Cependant, étant donné que le réseau pré-entraîné d'origine dispose initialement d'une « connaissance » beaucoup plus robuste, le nouveau textgenrnn s'entraîne plus rapidement et plus précisément à la fin, et peut potentiellement apprendre de nouvelles relations non présentes dans l'ensemble de données d'origine (par exemple, les intégrations de caractères pré-entraînées incluent le contexte pour le caractère pour tous les types possibles de grammaire Internet moderne).
De plus, le recyclage est effectué avec un optimiseur basé sur l'élan et un taux d'apprentissage décroissant linéairement, qui empêchent tous deux l'explosion des gradients et rendent beaucoup moins probable que le modèle diverge après un entraînement prolongé.
Vous n'obtiendrez pas de texte généré de qualité dans 100 % des cas , même avec un réseau neuronal fortement entraîné. C'est la principale raison pour laquelle les articles de blog viraux/les tweets Twitter utilisant la génération de texte NN génèrent souvent de nombreux textes et organisent/éditent les meilleurs par la suite.
Les résultats varieront considérablement d'un ensemble de données à l'autre . Étant donné que le réseau neuronal pré-entraîné est relativement petit, il ne peut pas stocker autant de données que les RNN généralement affichés dans les articles de blog. Pour de meilleurs résultats, utilisez un ensemble de données contenant au moins 2 000 à 5 000 documents. Si un ensemble de données est plus petit, vous devrez l'entraîner plus longtemps en définissant num_epochs plus haut lors de l'appel d'une méthode d'entraînement et/ou de l'entraînement d'un nouveau modèle à partir de zéro. Même dans ce cas, il n’existe actuellement aucune bonne heuristique permettant de déterminer un « bon » modèle.
Un GPU n'est pas nécessaire pour recycler textgenrnn, mais l'entraînement sur un CPU prendra beaucoup plus de temps. Si vous utilisez un GPU, je vous recommande d'augmenter le paramètre batch_size pour une meilleure utilisation du matériel.
Documentation plus formelle
Une implémentation basée sur le Web utilisant tensorflow.js (fonctionne particulièrement bien en raison de la petite taille du réseau)
Un moyen de visualiser les résultats de la couche d'attention pour voir comment le réseau « apprend ».
Un mode permettant d'utiliser l'architecture du modèle pour les conversations de chatbot (peut être publié en tant que projet séparé)
Plus de profondeur vers le contexte (contexte positionnel + autorisation de plusieurs étiquettes de contexte)
Un réseau pré-entraîné plus vaste pouvant accueillir des séquences de caractères plus longues et une compréhension plus approfondie du langage, créant ainsi des phrases mieux générées.
Activation hiérarchique de softmax pour les modèles au niveau des mots (une fois que Keras en aura un bon support).
FP16 pour une formation ultra-rapide sur Volta/TPU (une fois que Keras en aura un bon support).
Max Woolf (@minimaxir)
Les projets open source de Max sont soutenus par son Patreon. Si vous avez trouvé ce projet utile, toute contribution monétaire au Patreon est appréciée et sera utilisée à bon escient de manière créative.
Andrej Karpathy pour la proposition originale du char-rnn via le billet de blog The Unreasonable Effectiveness of Recurrent Neural Networks.
Daniel Grijalva pour sa contribution à un mode interactif.
MIT
Code de couche d'attention utilisé par DeepMoji (sous licence MIT)


