100 Days Of ML Code
1.0.0
100 jours de codage par apprentissage automatique proposés par Siraj Raval
Obtenez les ensembles de données à partir d'ici
Consultez le code à partir d'ici.

Consultez le code à partir d'ici.

Consultez le code à partir d'ici.


En avançant dans #100DaysOfMLCode aujourd'hui, j'ai plongé plus profondément dans ce qu'est réellement la régression logistique et quels sont les mathématiques impliquées derrière elle. J'ai appris comment la fonction de coût est calculée, puis comment appliquer l'algorithme de descente de gradient à la fonction de coût pour minimiser l'erreur de prédiction.
En raison de moins de temps, je publierai désormais une infographie un jour sur deux. Aussi, si quelqu'un veut m'aider dans la documentation du code et a déjà une certaine expérience dans le domaine et connaît Markdown pour github, veuillez me contacter sur LinkedIn :) .
Consultez le code ici

#100DaysOfMLCode Pour clarifier mes idées sur la régression logistique, je cherchais sur Internet une ressource ou un article et je suis tombé sur cet article (https://towardsdatascience.com/logistic-regression-detailed-overview-46c4da4303bc) de Saishruthi Swaminathan.
Il donne une description détaillée de la régression logistique. Vérifiez-le.
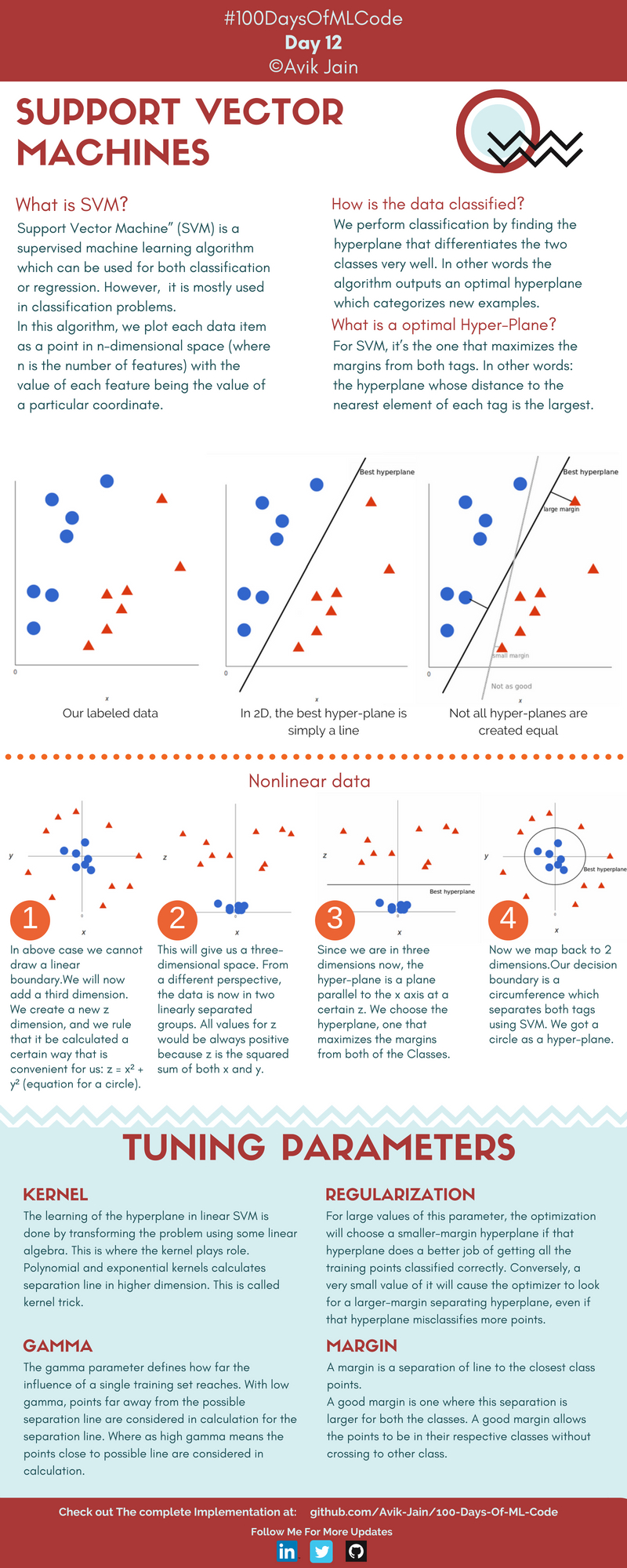
Vous avez une idée de ce qu'est SVM et comment il est utilisé pour résoudre le problème de classification.
En savoir plus sur le fonctionnement de SVM et la mise en œuvre de l'algorithme K-NN.
Implémentation de l'algorithme K-NN pour la classification. L’infographie de la machine à vecteurs de support #100DaysOfMLCode est à moitié terminée. Le mettra à jour demain.
En continuant avec #100DaysOfMLCode aujourd'hui, j'ai parcouru le classificateur Naive Bayes. J'implémente également le SVM en python en utilisant scikit-learn. Mettra à jour le code bientôt.
Aujourd'hui, j'ai implémenté SVM sur des données liées linéairement. Bibliothèque Scikit-Learn utilisée. Dans Scikit-Learn, nous avons un classificateur SVC que nous utilisons pour accomplir cette tâche. J'utiliserai kernel-trick lors de la prochaine implémentation. Vérifiez le code ici.
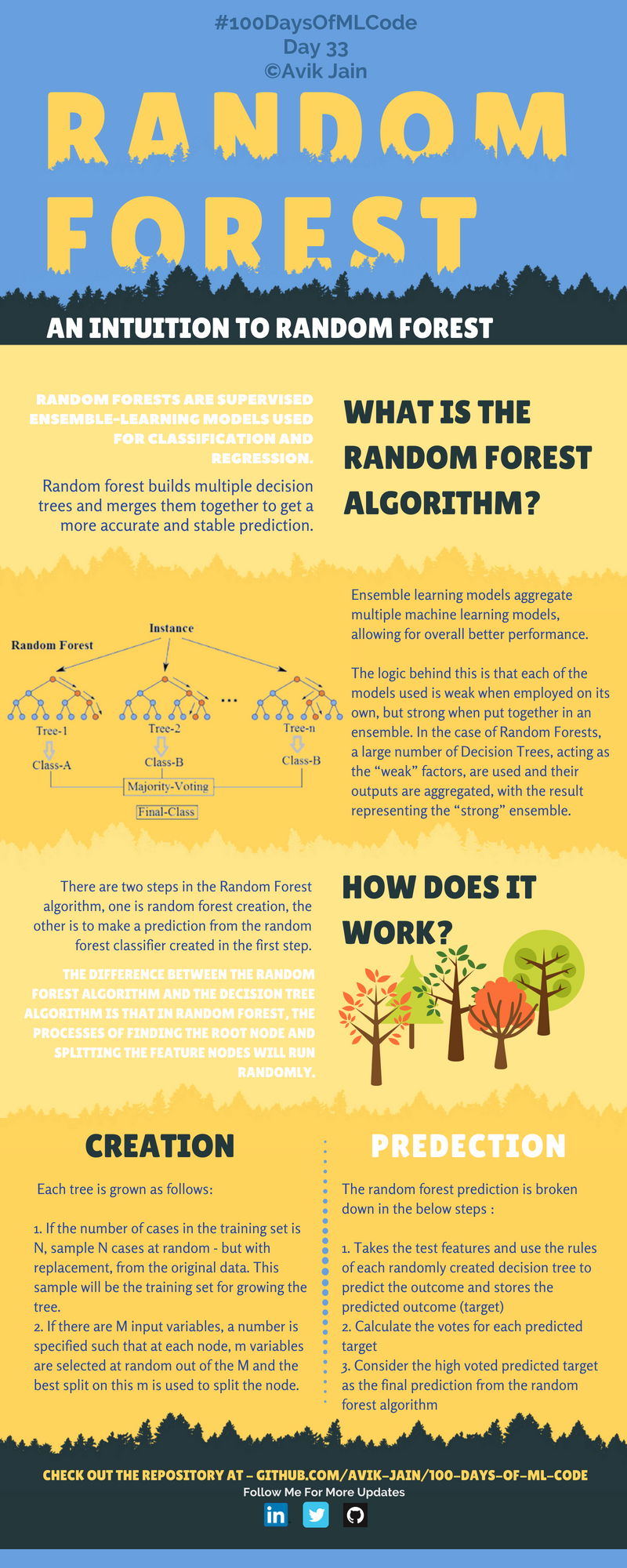
Découverte de différents types de classificateurs bayésiens naïfs. A également commencé les conférences de Bloomberg. Le premier de la liste de lecture était Black Box Machine Learning. Il donne un aperçu complet des fonctions de prédiction, de l'extraction de fonctionnalités, des algorithmes d'apprentissage, de l'évaluation des performances, de la validation croisée, du biais d'échantillon, de la non-stationnarité, du surajustement et du réglage des hyperparamètres.
À l'aide de la bibliothèque Scikit-Learn, l'algorithme SVM a été implémenté ainsi que la fonction du noyau qui mappe nos points de données dans une dimension supérieure pour trouver un hyperplan optimal.
Vous avez terminé toute la semaine 1 et la semaine 2 en une seule journée. Régression logistique apprise en tant que réseau neuronal.
J'ai terminé le cours 1 de la spécialisation deep learning. Implémentation d'un réseau de neurones en python.
Début de la conférence 1 sur 18 du cours d'apprentissage automatique de Caltech - CS 156 par le professeur Yaser Abu-Mostafa. Il s'agissait essentiellement d'une introduction aux conférences à venir. Il a également expliqué l'algorithme Perceptron.
Vous avez terminé la semaine 1 de l'amélioration des réseaux de neurones profonds : réglage, régularisation et optimisation des hyperparamètres.
J'ai regardé quelques tutoriels sur la façon de faire du web scraping à l'aide de Beautiful Soup afin de collecter des données pour créer un modèle.
Conférence 2 sur 18 du cours d'apprentissage automatique de Caltech - CS 156 par le professeur Yaser Abu-Mostafa. Découverte de l'inégalité de Hoeffding.

Lec 3 du cours Bloomberg ML a introduit certains des concepts de base tels que l'espace d'entrée, l'espace d'action, l'espace de résultat, les fonctions de prédiction, les fonctions de perte et les espaces d'hypothèses.
Vérifiez le code ici.
J'ai trouvé une chaîne incroyable sur YouTube 3Blue1Brown. Il propose une liste de lecture intitulée Essence of Linear Algebra. J'ai commencé par réaliser 4 vidéos qui donnaient un aperçu complet des vecteurs, des combinaisons linéaires, des travées, des vecteurs de base, des transformations linéaires et de la multiplication matricielle.
Lien vers la playlist ici.
Poursuivant la playlist, nous avons complété les 4 vidéos suivantes traitant des sujets Transformations 3D, Déterminants, Matrice inverse, Espace des colonnes, Espace nul et Matrices non carrées.
Lien vers la playlist ici.
Dans la playlist de 3Blue1Brown, nous avons complété 3 autres vidéos sur l'essence de l'algèbre linéaire. Les sujets abordés étaient Dot Product et Cross Product.
Lien vers la playlist ici.
J'ai terminé toute la playlist aujourd'hui, vidéos 12 à 14. Vraiment une playlist étonnante pour rafraîchir les concepts de l'algèbre linéaire. Les sujets abordés étaient le changement de base, les vecteurs propres et les valeurs propres, ainsi que les espaces vectoriels abstraits.
Lien vers la playlist ici.
Compléter la playlist - Essence of Linear Algebra par 3blue1brown, une suggestion apparue sur YouTube concernant une série de vidéos de la même chaîne 3Blue1Brown. Étant déjà impressionné par la série précédente sur l'algèbre linéaire, je me suis plongé directement dedans. Réalisation d'environ 5 vidéos sur des sujets tels que les dérivés, la règle de chaîne, la règle de produit et la dérivée exponentielle.
Lien vers la playlist ici.
J'ai regardé 2 vidéos sur le sujet Diffrentiation implicite et limites de la playlist Essence of Calculus.
Lien vers la playlist ici.
J'ai regardé les 4 vidéos restantes traitant de sujets tels que l'intégration et les dérivés d'ordre supérieur.
Lien vers la playlist ici.
Vérifiez le code ici.
Une vidéo étonnante sur les réseaux de neurones par la chaîne YouTube 3Blue1Brown. Cette vidéo donne une bonne compréhension des réseaux de neurones et utilise un ensemble de données de chiffres manuscrits pour expliquer le concept. Lien vers la vidéo.
Deuxième partie des réseaux de neurones de la chaîne YouTube 3Blue1Brown. Cette vidéo explique les concepts de Gradient Descent d'une manière intéressante. 169 à surveiller absolument et fortement recommandé. Lien vers la vidéo.
Troisième partie des réseaux de neurones de la chaîne YouTube 3Blue1Brown. Cette vidéo traite principalement des dérivées partielles et de la rétropropagation. Lien vers la vidéo.
Quatrième partie des réseaux de neurones de la chaîne YouTube 3Blue1Brown. Le but ici est de représenter, en termes un peu plus formels, l'intuition du fonctionnement de la rétropropagation et la vidéo traite principalement des dérivées partielles et de la rétropropagation. Lien vers la vidéo.
Lien vers la vidéo.
Lien vers la vidéo.
Lien vers la vidéo.
Lien vers la vidéo.
Passé à l'apprentissage non supervisé et étudié le clustering. En travaillant sur mon site Web, consultez avikjain.me. J'ai également trouvé une merveilleuse animation qui peut aider à comprendre facilement K - Means Clustering Link

Implémentation du clustering K Means. Vérifiez le code ici.
Vous avez un nouveau livre "Python Data Science HandBook" de JK VanderPlas. Consultez les cahiers Jupyter ici.
Commencé avec le chapitre 2 : Introduction à Numpy. Sujets abordés tels que les types de données, les tableaux Numpy et les calculs sur les tableaux Numpy.
Vérifiez le code -
Introduction à NumPy
Comprendre les types de données en Python
Les bases des tableaux NumPy
Calcul sur les tableaux NumPy : fonctions universelles
Chapitre 2 : Agrégations, comparaisons et diffusion
Lien vers le carnet :
Agrégations : Min, Max et tout le reste
Calcul sur des tableaux : diffusion
Comparaisons, masques et logique booléenne
Chapitre 2 : Indexation sophistiquée, tableaux de tri, données structurées
Lien vers le carnet :
Indexation sophistiquée
Tri des tableaux
Données structurées : tableaux structurés de NumPy
Chapitre 3 : Manipulation des données avec Pandas
Divers sujets couverts tels que les objets Pandas, l'indexation et la sélection des données, l'exploitation des données, la gestion des données manquantes, l'indexation hiérarchique, ConCat et Append.
Lien vers les cahiers :
Manipulation de données avec Pandas
Présentation des objets Pandas
Indexation et sélection des données
Opérer sur les données dans Pandas
Gestion des données manquantes
Indexation hiérarchique
Combinaison d'ensembles de données : Concat et Append
Chapitre 3 : Sujets suivants terminés : Fusion et jointure, Agrégation et regroupement et Tableaux croisés dynamiques.
Combinaison d'ensembles de données : fusionner et joindre
Agrégation et regroupement
Tableaux croisés dynamiques
Chapitre 3 : Opérations sur les chaînes vectorisées, utilisation des séries temporelles
Liens vers les cahiers :
Opérations de chaînes vectorisées
Travailler avec des séries chronologiques
Pandas hautes performances : eval() et query()
Chapitre 4 : Visualisation avec Matplotlib Apprentissage des tracés de lignes simples, des nuages de points simples et des tracés de densité et de contour.
Liens vers les cahiers :
Visualisation avec Matplotlib
Tracés linéaires simples
Nuages de points simples
Visualiser les erreurs
Tracés de densité et de contour
Chapitre 4 : Visualisation avec Matplotlib En savoir plus sur les histogrammes, comment personnaliser les légendes des tracés, les barres de couleurs et la création de plusieurs sous-parcelles.
Liens vers les cahiers :
Histogrammes, regroupements et densité
Personnalisation des légendes de tracé
Personnalisation des barres de couleurs
Plusieurs sous-parcelles
Texte et annotation
Chapitre 4 : Traçage tridimensionnel couvert dans Mathplotlib.
Liens vers les cahiers :
Traçage tridimensionnel dans Matplotlib
A étudié le clustering hiérarchique. Découvrez cette incroyable visualisation.



